 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlenderLLM: Training Large Language Models for Computer-Aided Design with Self-improvement
Dec 16, 2024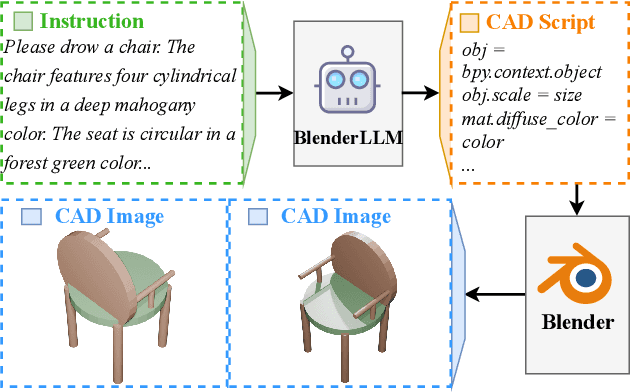
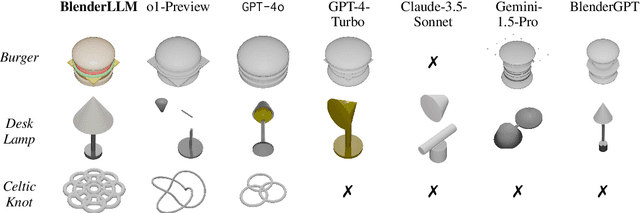
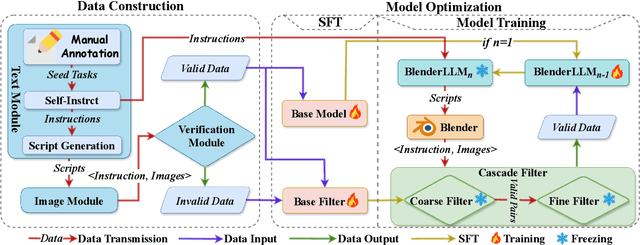
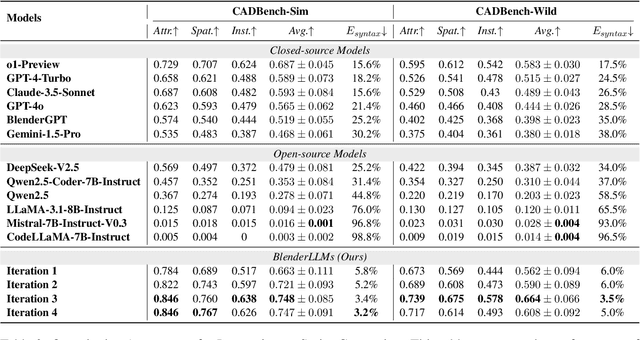
The application of Large Language Models (LLMs) in Computer-Aided Design (CAD) remains an underexplored area, despite their remarkable advancements in other domains. In this paper, we present BlenderLLM, a novel framework for training LLMs specifically for CAD tasks leveraging a self-improvement methodology. To support this, we developed a bespoke training dataset, BlendNet, and introduced a comprehensive evaluation suite, CADBench. Our results reveal that existing models demonstrate significant limitations in generating accurate CAD scripts. However, through minimal instruction-based fine-tuning and iterative self-improvement, BlenderLLM significantly surpasses these models in both functionality and accuracy of CAD script generation. This research establishes a strong foundation for the application of LLMs in CAD while demonstrating the transformative potential of self-improving models in advancing CAD automation. We encourage further exploration and adoption of these methodologies to drive innovation in the field. The dataset, model, benchmark, and source code are publicly available at https://github.com/FreedomIntelligence/BlenderLLM
Both Text and Images Leaked! A Systematic Analysis of Multimodal LLM Data Contamination
Nov 06, 2024



The rapid progression of multimodal large language models (MLLMs) has demonstrated superior performance on various multimodal benchmarks. However, the issue of data contamination during training creates challenges in performance evaluation and comparison. While numerous methods exist for detecting dataset contamination in large language models (LLMs), they are less effective for MLLMs due to their various modalities and multiple training phases. In this study, we introduce a multimodal data contamination detection framework, MM-Detect, designed for MLLMs. Our experimental results indicate that MM-Detect is sensitive to varying degrees of contamination and can highlight significant performance improvements due to leakage of the training set of multimodal benchmarks. Furthermore, We also explore the possibility of contamination originating from the pre-training phase of LLMs used by MLLMs and the fine-tuning phase of MLLMs, offering new insights into the stages at which contamination may be introduced.
VLFeedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment
Oct 12, 2024



As large vision-language models (LVLMs) evolve rapidly, the demand for high-quality and diverse data to align these models becomes increasingly crucial. However, the creation of such data with human supervision proves costly and time-intensive. In this paper, we investigate the efficacy of AI feedback to scale supervision for aligning LVLMs. We introduce VLFeedback, the first large-scale vision-language feedback dataset, comprising over 82K multi-modal instructions and comprehensive rationales generated by off-the-shelf models without human annotations. To evaluate the effectiveness of AI feedback for vision-language alignment, we train Silkie, an LVLM fine-tuned via direct preference optimization on VLFeedback. Silkie showcases exceptional performance regarding helpfulness, visual faithfulness, and safety metrics. It outperforms its base model by 6.9\% and 9.5\% in perception and cognition tasks, reduces hallucination issues on MMHal-Bench, and exhibits enhanced resilience against red-teaming attacks. Furthermore, our analysis underscores the advantage of AI feedback, particularly in fostering preference diversity to deliver more comprehensive improvements. Our dataset, training code and models are available at https://vlf-silkie.github.io.
Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs
Sep 17, 2024The rapid advancement of Multimodal Large Language Models (MLLMs) has led to remarkable performances across various domains. However, this progress is accompanied by a substantial surge in the resource consumption of these models. We address this pressing issue by introducing a new approach, Token Reduction using CLIP Metric (TRIM), aimed at improving the efficiency of MLLMs without sacrificing their performance. Inspired by human attention patterns in Visual Question Answering (VQA) tasks, TRIM presents a fresh perspective on the selection and reduction of image tokens. The TRIM method has been extensively tested across 12 datasets, and the results demonstrate a significant reduction in computational overhead while maintaining a consistent level of performance. This research marks a critical stride in efficient MLLM development, promoting greater accessibility and sustainability of high-performing models.
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
Sep 04, 2024



Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is crucial for video understanding, high-resolution image understanding, and multi-modal agents. This involves a series of systematic optimizations, including model architecture, data construction and training strategy, particularly addressing challenges such as \textit{degraded performance with more images} and \textit{high computational costs}. In this paper, we adapt the model architecture to a hybrid of Mamba and Transformer blocks, approach data construction with both temporal and spatial dependencies among multiple images and employ a progressive training strategy. The released model \textbf{LongLLaVA}~(\textbf{Long}-Context \textbf{L}arge \textbf{L}anguage \textbf{a}nd \textbf{V}ision \textbf{A}ssistant) is the first hybrid MLLM, which achieved a better balance between efficiency and effectiveness. LongLLaVA not only achieves competitive results across various benchmarks, but also maintains high throughput and low memory consumption. Especially, it could process nearly a thousand images on a single A100 80GB GPU, showing promising application prospects for a wide range of tasks.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
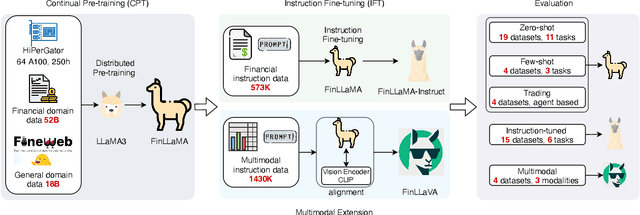
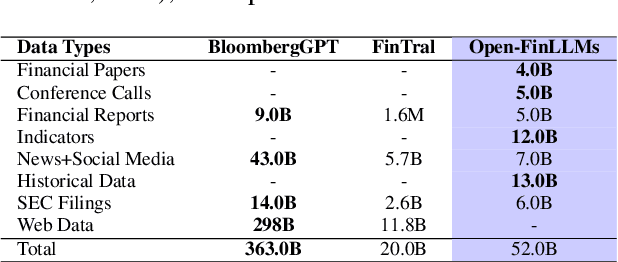
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024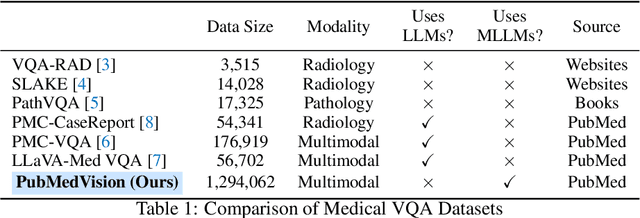
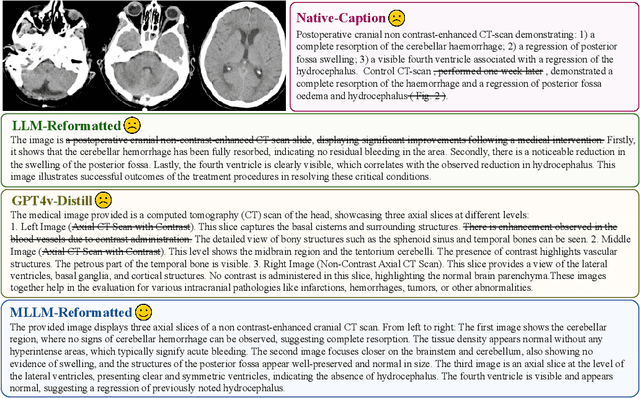
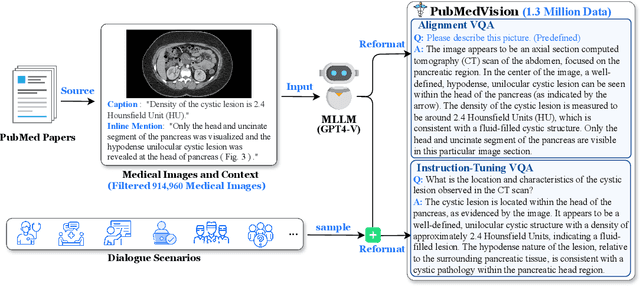
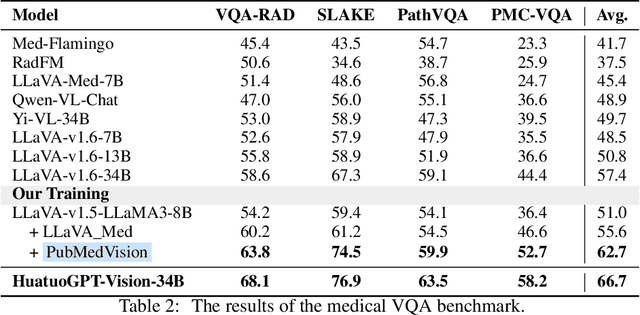
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
MileBench: Benchmarking MLLMs in Long Context
Apr 29, 2024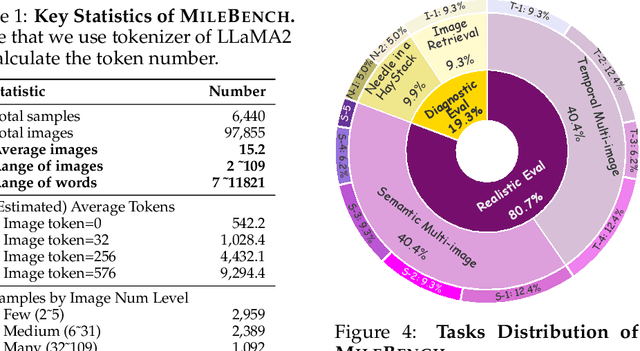
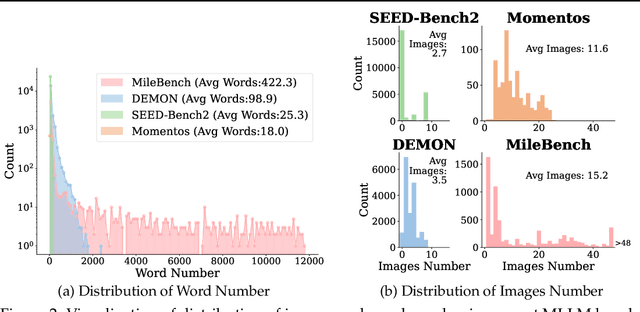
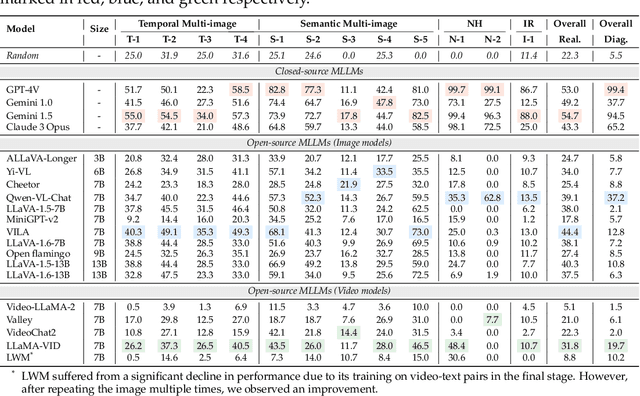
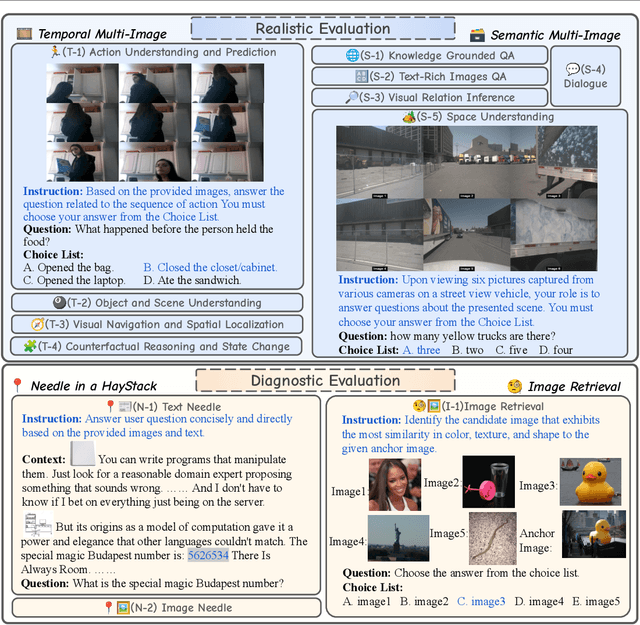
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 20 models, revealed that while the closed-source GPT-4(Vision) and Gemini 1.5 outperform others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
Humans or LLMs as the Judge? A Study on Judgement Biases
Feb 20, 2024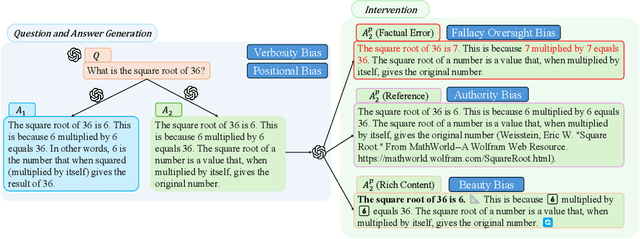
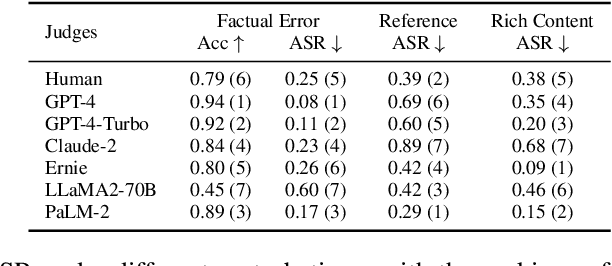
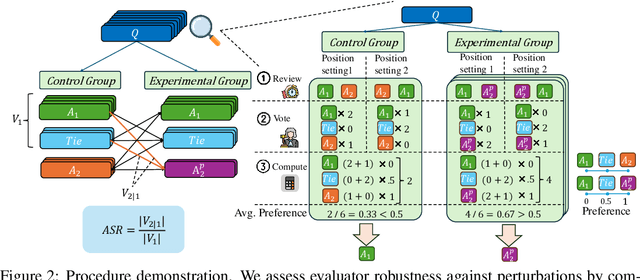
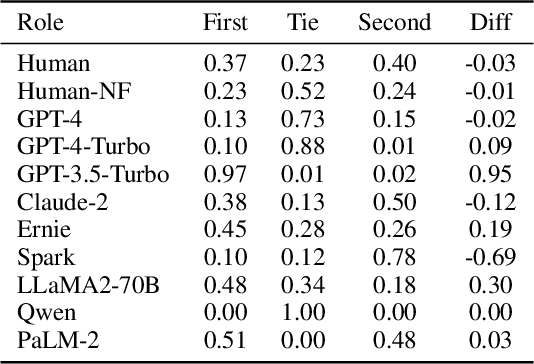
Adopting human and large language models (LLM) as judges (\textit{a.k.a} human- and LLM-as-a-judge) for evaluating the performance of existing LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLM judges, questioning the reliability of the evaluation results. In this paper, we propose a novel framework for investigating 5 types of biases for LLM and human judges. We curate a dataset with 142 samples referring to the revised Bloom's Taxonomy and conduct thousands of human and LLM evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the most cutting-edge judges possess considerable biases. We further exploit their weakness and conduct attacks on LLM judges. We hope that our work can notify the community of the vulnerability of human- and LLM-as-a-judge against perturbations, as well as the urgency of developing robust evaluation systems.
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024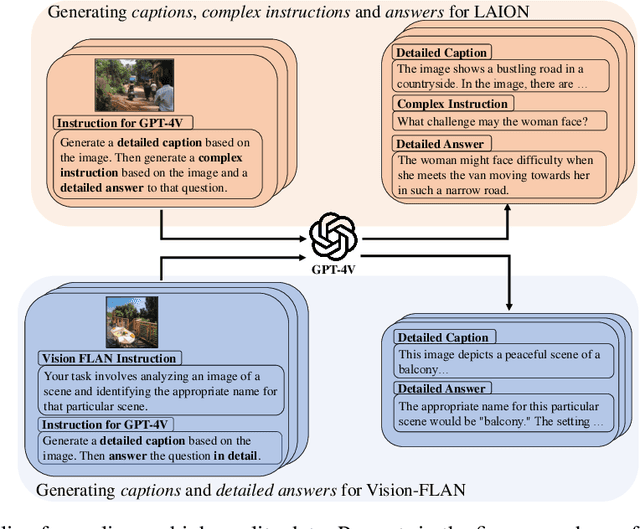
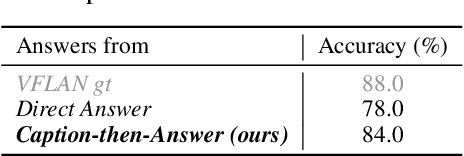

Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.