 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans or LLMs as the Judge? A Study on Judgement Biases
Paper and Code
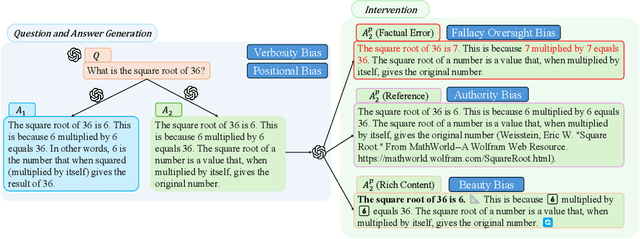
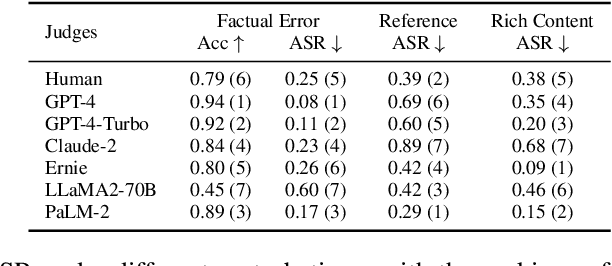
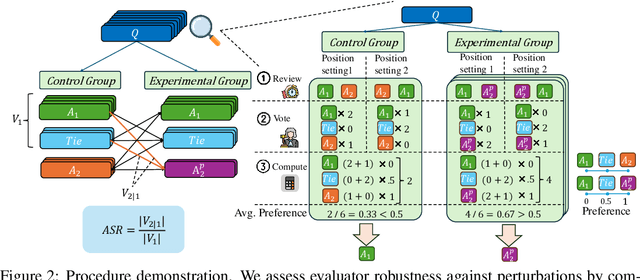
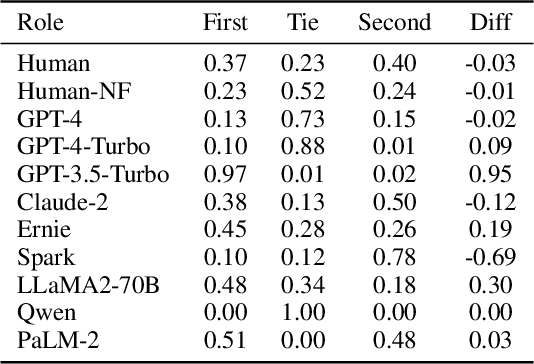
Adopting human and large language models (LLM) as judges (\textit{a.k.a} human- and LLM-as-a-judge) for evaluating the performance of existing LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLM judges, questioning the reliability of the evaluation results. In this paper, we propose a novel framework for investigating 5 types of biases for LLM and human judges. We curate a dataset with 142 samples referring to the revised Bloom's Taxonomy and conduct thousands of human and LLM evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the most cutting-edge judges possess considerable biases. We further exploit their weakness and conduct attacks on LLM judges. We hope that our work can notify the community of the vulnerability of human- and LLM-as-a-judge against perturbations, as well as the urgency of developing robust evaluation systems.