 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025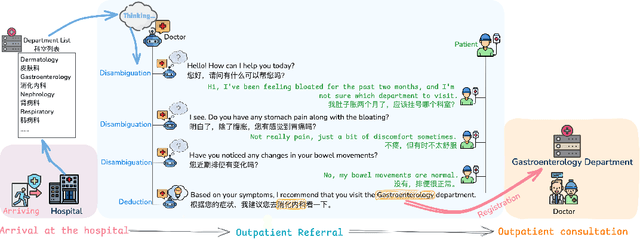
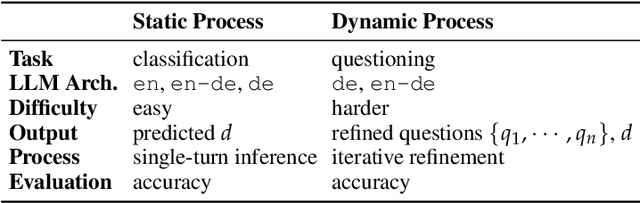
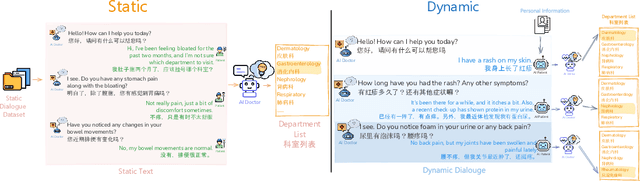
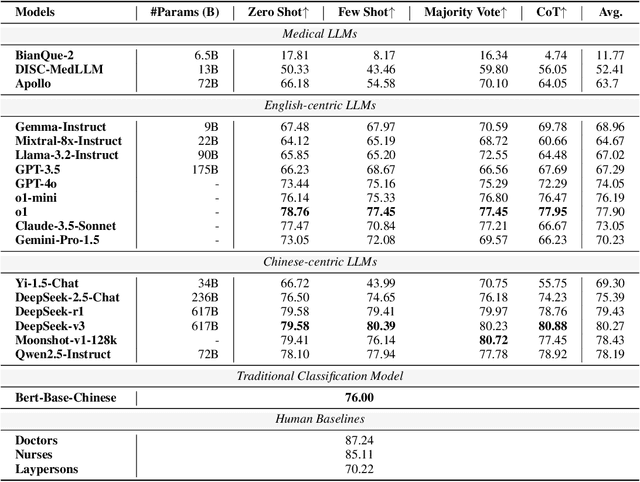
Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Apollo: An Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
Mar 09, 2024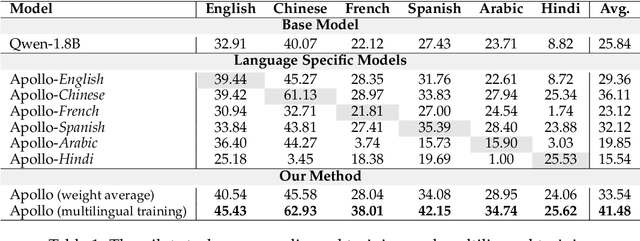


Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
Online Training of Large Language Models: Learn while chatting
Mar 04, 2024



Large Language Models(LLMs) have dramatically revolutionized the field of Natural Language Processing(NLP), offering remarkable capabilities that have garnered widespread usage. However, existing interaction paradigms between LLMs and users are constrained by either inflexibility, limitations in customization, or a lack of persistent learning. This inflexibility is particularly evident as users, especially those without programming skills, have restricted avenues to enhance or personalize the model. Existing frameworks further complicate the model training and deployment process due to their computational inefficiencies and lack of user-friendly interfaces. To overcome these challenges, this paper introduces a novel interaction paradigm-'Online Training using External Interactions'-that merges the benefits of persistent, real-time model updates with the flexibility for individual customization through external interactions such as AI agents or online/offline knowledge bases.
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024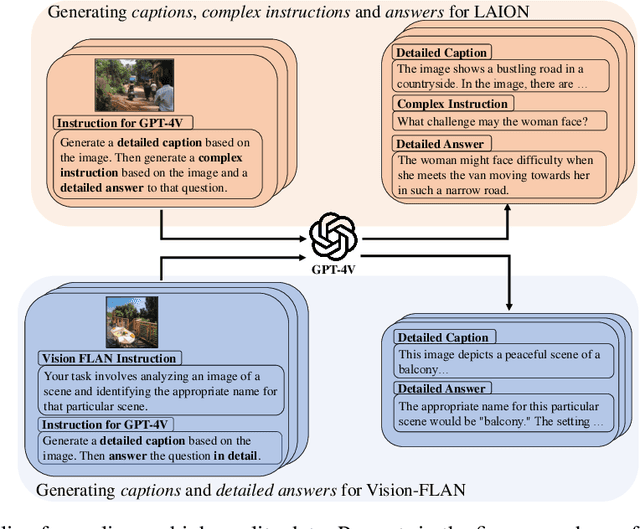
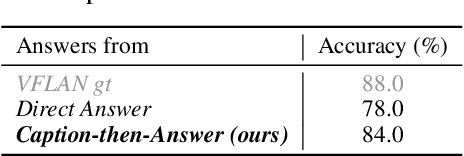

Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.
HuatuoGPT, towards Taming Language Model to Be a Doctor
May 24, 2023
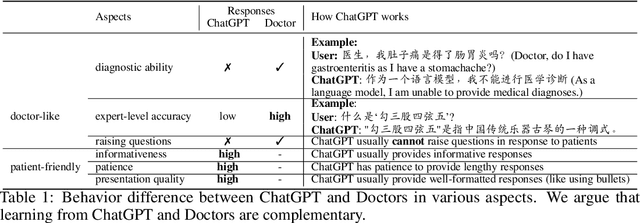
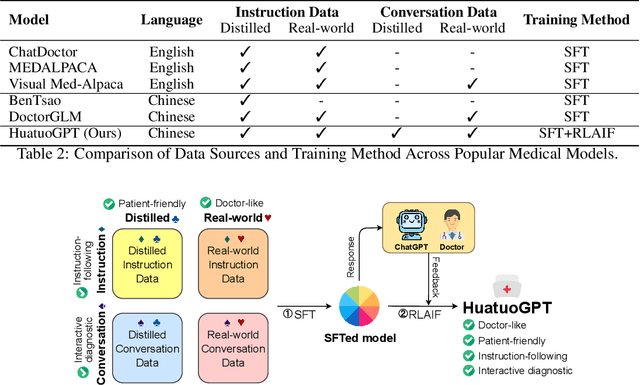
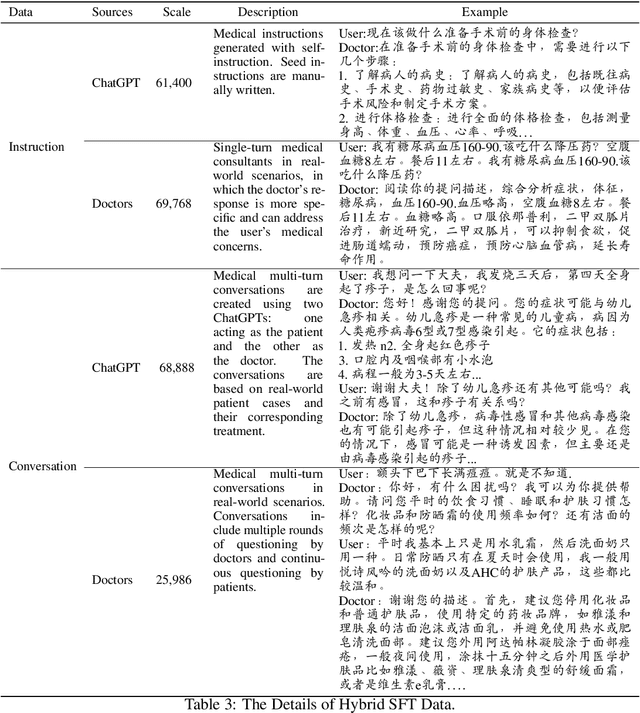
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both \textit{distilled data from ChatGPT} and \textit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
Huatuo-26M, a Large-scale Chinese Medical QA Dataset
May 02, 2023
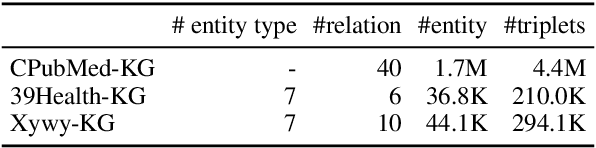

In this paper, we release a largest ever medical Question Answering (QA) dataset with 26 million QA pairs. We benchmark many existing approaches in our dataset in terms of both retrieval and generation. Experimental results show that the existing models perform far lower than expected and the released dataset is still challenging in the pre-trained language model era. Moreover, we also experimentally show the benefit of the proposed dataset in many aspects: (i) trained models for other QA datasets in a zero-shot fashion; and (ii) as external knowledge for retrieval-augmented generation (RAG); and (iii) improving existing pre-trained language models by using the QA pairs as a pre-training corpus in continued training manner. We believe that this dataset will not only contribute to medical research but also facilitate both the patients and clinical doctors. See \url{https://github.com/FreedomIntelligence/Huatuo-26M}.
Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
Jul 02, 2022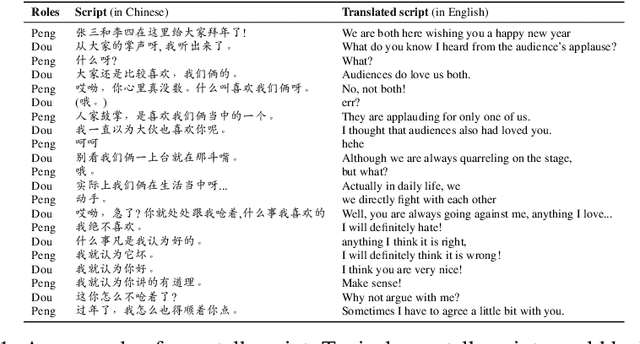



Language is the principal tool for human communication, in which humor is one of the most attractive parts. Producing natural language like humans using computers, a.k.a, Natural Language Generation (NLG), has been widely used for dialogue systems, chatbots, machine translation, as well as computer-aid creation e.g., idea generations, scriptwriting. However, the humor aspect of natural language is relatively under-investigated, especially in the age of pre-trained language models. In this work, we aim to preliminarily test whether NLG can generate humor as humans do. We build a new dataset consisting of numerous digitized Chinese Comical Crosstalk scripts (called C$^3$ in short), which is for a popular Chinese performing art called `Xiangsheng' since 1800s. (For convenience for non-Chinese speakers, we called `crosstalk' for `Xiangsheng' in this paper.) We benchmark various generation approaches including training-from-scratch Seq2seq, fine-tuned middle-scale PLMs, and large-scale PLMs (with and without fine-tuning). Moreover, we also conduct a human assessment, showing that 1) large-scale pretraining largely improves crosstalk generation quality; and 2) even the scripts generated from the best PLM is far from what we expect, with only 65% quality of human-created crosstalk. We conclude, humor generation could be largely improved using large-scaled PLMs, but it is still in its infancy. The data and benchmarking code is publicly available in \url{https://github.com/anonNo2/crosstalk-generation}.