 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
Paper and Code
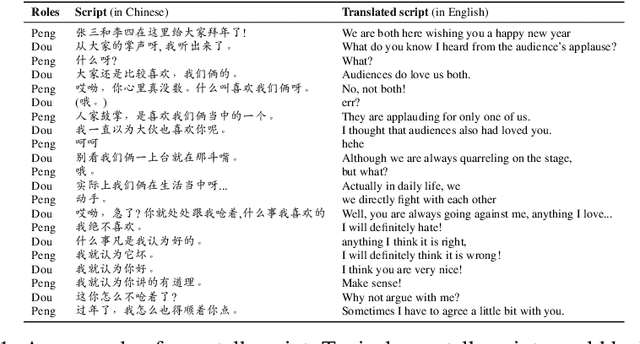



Language is the principal tool for human communication, in which humor is one of the most attractive parts. Producing natural language like humans using computers, a.k.a, Natural Language Generation (NLG), has been widely used for dialogue systems, chatbots, machine translation, as well as computer-aid creation e.g., idea generations, scriptwriting. However, the humor aspect of natural language is relatively under-investigated, especially in the age of pre-trained language models. In this work, we aim to preliminarily test whether NLG can generate humor as humans do. We build a new dataset consisting of numerous digitized Chinese Comical Crosstalk scripts (called C$^3$ in short), which is for a popular Chinese performing art called `Xiangsheng' since 1800s. (For convenience for non-Chinese speakers, we called `crosstalk' for `Xiangsheng' in this paper.) We benchmark various generation approaches including training-from-scratch Seq2seq, fine-tuned middle-scale PLMs, and large-scale PLMs (with and without fine-tuning). Moreover, we also conduct a human assessment, showing that 1) large-scale pretraining largely improves crosstalk generation quality; and 2) even the scripts generated from the best PLM is far from what we expect, with only 65% quality of human-created crosstalk. We conclude, humor generation could be largely improved using large-scaled PLMs, but it is still in its infancy. The data and benchmarking code is publicly available in \url{https://github.com/anonNo2/crosstalk-generation}.