 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
May 19, 2026Automating scientific discovery requires more than generating papers from ideas. Real research is iterative: hypotheses are challenged from multiple perspectives, experiments fail and inform the next attempt, and lessons accumulate across cycles. Existing autonomous research systems often model this process as a linear pipeline: they rely on single-agent reasoning, stop when execution fails, and do not carry experience across runs. We present AutoResearchClaw, a multi-agent autonomous research pipeline built on five mechanisms: structured multi-agent debate for hypothesis generation and result analysis, a self-healing executor with a \textsc{Pivot}/\textsc{Refine} decision loop that transforms failures into information, verifiable result reporting that prevents fabricated numbers and hallucinated citations, human-in-the-loop collaboration with seven intervention modes spanning full autonomy to step-by-step oversight, and cross-run evolution that converts past mistakes into future safeguards. On ARC-Bench, a 25-topic experiment-stage benchmark, AutoResearchClaw outperforms AI Scientist v2 by 54.7%. A human-in-the-loop ablation across seven intervention modes reveals that precise, targeted collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. We position AutoResearchClaw as a research amplifier that augments rather than replaces human scientific judgment. Code is available at https://github.com/aiming-lab/AutoResearchClaw.
MLLM-Bench, Evaluating Multi-modal LLMs using GPT-4V
Nov 23, 2023


In the pursuit of Artificial General Intelligence (AGI), the integration of vision in language models has marked a significant milestone. The advent of vision-language models (MLLMs) like GPT-4V have expanded AI applications, aligning with the multi-modal capabilities of the human brain. However, evaluating the efficacy of MLLMs poses a substantial challenge due to the subjective nature of tasks that lack definitive answers. Existing automatic evaluation methodologies on multi-modal large language models rely on objective queries that have standard answers, inadequately addressing the nuances of creative and associative multi-modal tasks. To address this, we introduce MLLM-Bench, an innovative benchmark inspired by Vicuna, spanning a diverse array of scenarios, including Perception, Understanding, Applying, Analyzing, Evaluating, and Creation along with the ethical consideration. MLLM-Bench is designed to reflect user experience more accurately and provide a more holistic assessment of model performance. Comparative evaluations indicate a significant performance gap between existing open-source models and GPT-4V. We posit that MLLM-Bench will catalyze progress in the open-source community towards developing user-centric vision-language models that meet a broad spectrum of real-world applications. See online leaderboard in \url{https://mllm-bench.llmzoo.com}.
More Samples or More Prompt Inputs? Exploring Effective In-Context Sampling for LLM Few-Shot Prompt Engineering
Nov 16, 2023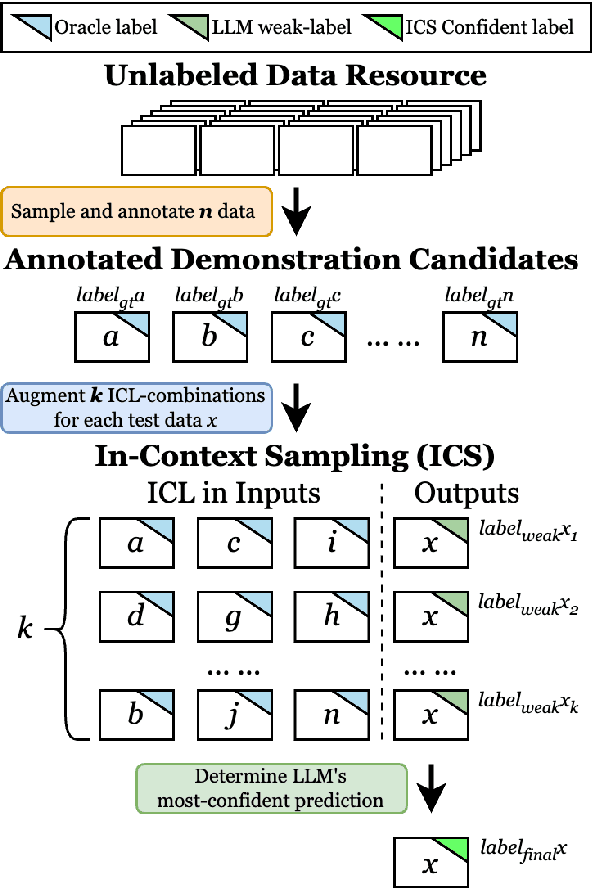
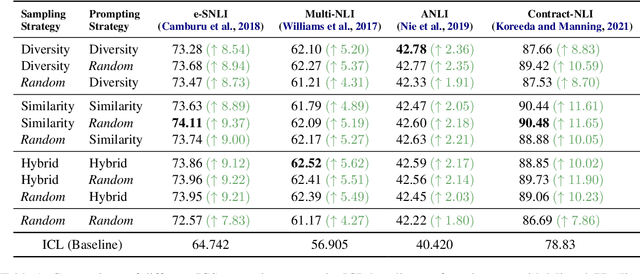
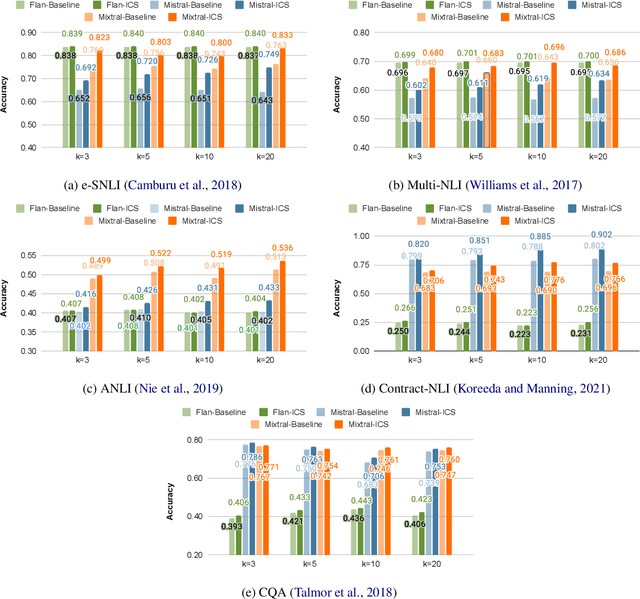
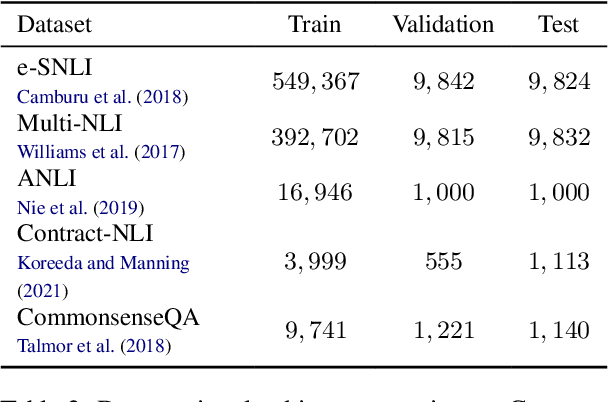
While most existing works on LLM prompt-engineering focus only on how to select a better set of data samples inside one single prompt input (In-Context Learning or ICL), why can't we design and leverage multiple prompt inputs together to further improve the LLM performance? In this work, we propose In-Context Sampling (ICS), a low-resource LLM prompt-engineering technique to produce the most confident prediction results by optimizing the construction of multiple ICL prompt inputs. Extensive experiments with two SOTA LLMs (FlanT5-XL and Mistral-7B) on three NLI datasets (e-SNLI, Multi-NLI, and ANLI) illustrate that ICS can consistently enhance LLM's prediction performance and confidence. An ablation study suggests that a diversity-based ICS strategy may further improve LLM's performance, which sheds light on a new yet promising future research direction.
HuatuoGPT, towards Taming Language Model to Be a Doctor
May 24, 2023
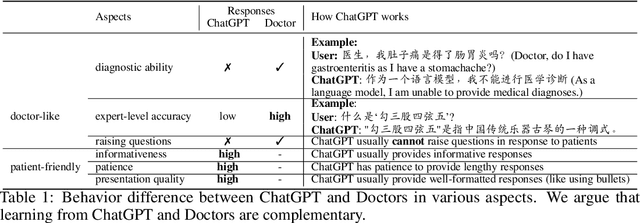
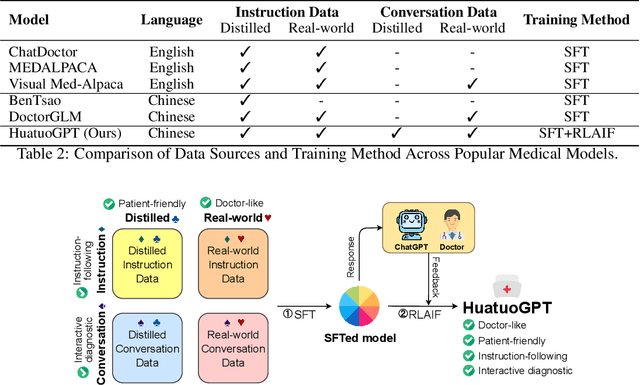
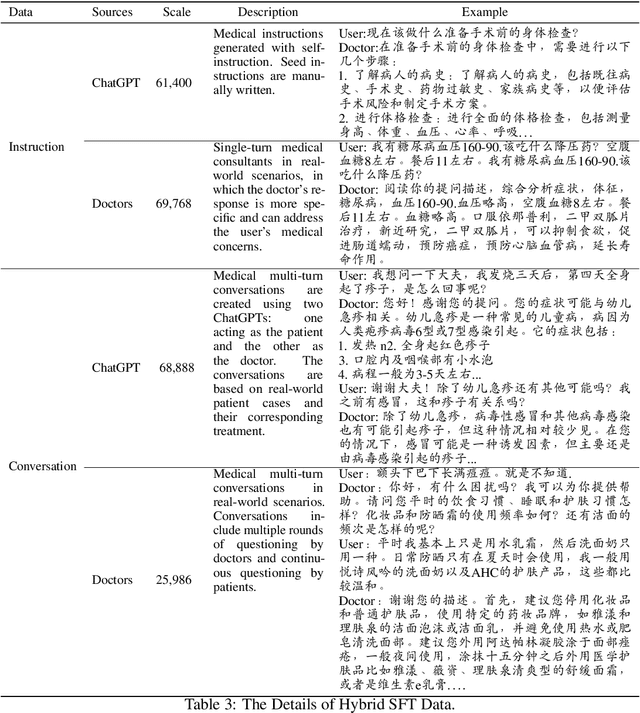
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both \textit{distilled data from ChatGPT} and \textit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
Phoenix: Democratizing ChatGPT across Languages
Apr 20, 2023



This paper presents our efforts to democratize ChatGPT across language. We release a large language model "Phoenix", achieving competitive performance among open-source English and Chinese models while excelling in languages with limited resources (covering both Latin and non-Latin languages). We believe this work will be beneficial to make ChatGPT more accessible, especially in countries where people cannot use ChatGPT due to restrictions from OpenAI or local goverments. Our data, code, and models are available at https://github.com/FreedomIntelligence/LLMZoo.