 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Training of Large Language Models: Learn while chatting
Mar 04, 2024



Large Language Models(LLMs) have dramatically revolutionized the field of Natural Language Processing(NLP), offering remarkable capabilities that have garnered widespread usage. However, existing interaction paradigms between LLMs and users are constrained by either inflexibility, limitations in customization, or a lack of persistent learning. This inflexibility is particularly evident as users, especially those without programming skills, have restricted avenues to enhance or personalize the model. Existing frameworks further complicate the model training and deployment process due to their computational inefficiencies and lack of user-friendly interfaces. To overcome these challenges, this paper introduces a novel interaction paradigm-'Online Training using External Interactions'-that merges the benefits of persistent, real-time model updates with the flexibility for individual customization through external interactions such as AI agents or online/offline knowledge bases.
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024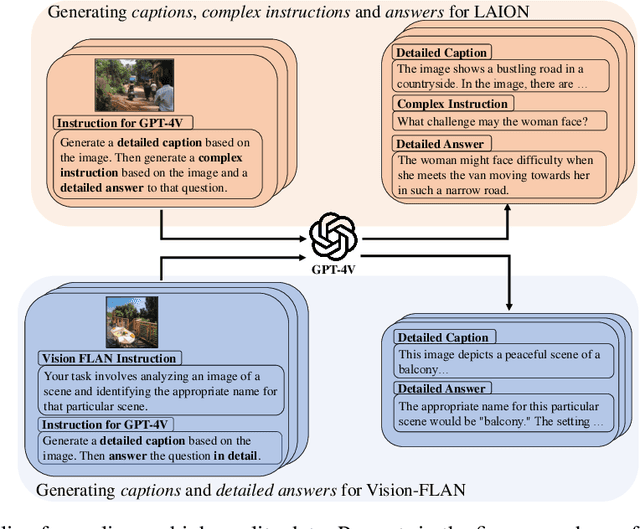
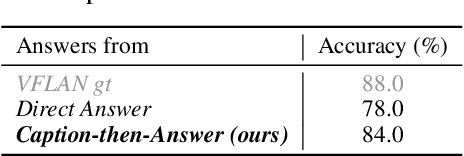

Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.
MLLM-Bench, Evaluating Multi-modal LLMs using GPT-4V
Nov 23, 2023


In the pursuit of Artificial General Intelligence (AGI), the integration of vision in language models has marked a significant milestone. The advent of vision-language models (MLLMs) like GPT-4V have expanded AI applications, aligning with the multi-modal capabilities of the human brain. However, evaluating the efficacy of MLLMs poses a substantial challenge due to the subjective nature of tasks that lack definitive answers. Existing automatic evaluation methodologies on multi-modal large language models rely on objective queries that have standard answers, inadequately addressing the nuances of creative and associative multi-modal tasks. To address this, we introduce MLLM-Bench, an innovative benchmark inspired by Vicuna, spanning a diverse array of scenarios, including Perception, Understanding, Applying, Analyzing, Evaluating, and Creation along with the ethical consideration. MLLM-Bench is designed to reflect user experience more accurately and provide a more holistic assessment of model performance. Comparative evaluations indicate a significant performance gap between existing open-source models and GPT-4V. We posit that MLLM-Bench will catalyze progress in the open-source community towards developing user-centric vision-language models that meet a broad spectrum of real-world applications. See online leaderboard in \url{https://mllm-bench.llmzoo.com}.
Uplift Modeling based on Graph Neural Network Combined with Causal Knowledge
Nov 14, 2023



Uplift modeling is a fundamental component of marketing effect modeling, which is commonly employed to evaluate the effects of treatments on outcomes. Through uplift modeling, we can identify the treatment with the greatest benefit. On the other side, we can identify clients who are likely to make favorable decisions in response to a certain treatment. In the past, uplift modeling approaches relied heavily on the difference-in-difference (DID) architecture, paired with a machine learning model as the estimation learner, while neglecting the link and confidential information between features. We proposed a framework based on graph neural networks that combine causal knowledge with an estimate of uplift value. Firstly, we presented a causal representation technique based on CATE (conditional average treatment effect) estimation and adjacency matrix structure learning. Secondly, we suggested a more scalable uplift modeling framework based on graph convolution networks for combining causal knowledge. Our findings demonstrate that this method works effectively for predicting uplift values, with small errors in typical simulated data, and its effectiveness has been verified in actual industry marketing data.
AceGPT, Localizing Large Language Models in Arabic
Sep 22, 2023



This paper explores the imperative need and methodology for developing a localized Large Language Model (LLM) tailored for Arabic, a language with unique cultural characteristics that are not adequately addressed by current mainstream models like ChatGPT. Key concerns additionally arise when considering cultural sensitivity and local values. To this end, the paper outlines a packaged solution, including further pre-training with Arabic texts, supervised fine-tuning (SFT) using native Arabic instructions and GPT-4 responses in Arabic, and reinforcement learning with AI feedback (RLAIF) using a reward model that is sensitive to local culture and values. The objective is to train culturally aware and value-aligned Arabic LLMs that can serve the diverse application-specific needs of Arabic-speaking communities. Extensive evaluations demonstrated that the resulting LLM called `AceGPT' is the SOTA open Arabic LLM in various benchmarks, including instruction-following benchmark (i.e., Arabic Vicuna-80 and Arabic AlpacaEval), knowledge benchmark (i.e., Arabic MMLU and EXAMs), as well as the newly-proposed Arabic cultural \& value alignment benchmark. Notably, AceGPT outperforms ChatGPT in the popular Vicuna-80 benchmark when evaluated with GPT-4, despite the benchmark's limited scale. % Natural Language Understanding (NLU) benchmark (i.e., ALUE) Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.
A Semi-automatic Oriental Ink Painting Framework for Robotic Drawing from 3D Models
Aug 26, 2023Creating visually pleasing stylized ink paintings from 3D models is a challenge in robotic manipulation. We propose a semi-automatic framework that can extract expressive strokes from 3D models and draw them in oriental ink painting styles by using a robotic arm. The framework consists of a simulation stage and a robotic drawing stage. In the simulation stage, geometrical contours were automatically extracted from a certain viewpoint and a neural network was employed to create simplified contours. Then, expressive digital strokes were generated after interactive editing according to user's aesthetic understanding. In the robotic drawing stage, an optimization method was presented for drawing smooth and physically consistent strokes to the digital strokes, and two oriental ink painting styles termed as Noutan (shade) and Kasure (scratchiness) were applied to the strokes by robotic control of a brush's translation, dipping and scraping. Unlike existing methods that concentrate on generating paintings from 2D images, our framework has the advantage of rendering stylized ink paintings from 3D models by using a consumer-grade robotic arm. We evaluate the proposed framework by taking 3 standard models and a user-defined model as examples. The results show that our framework is able to draw visually pleasing oriental ink paintings with expressive strokes.
CMB: A Comprehensive Medical Benchmark in Chinese
Aug 17, 2023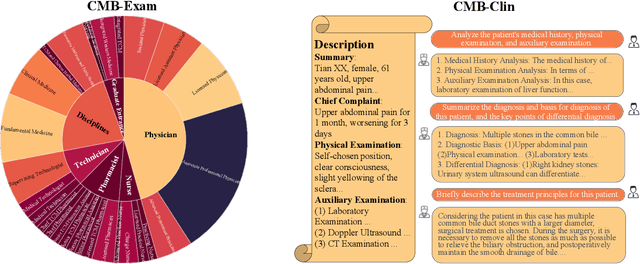
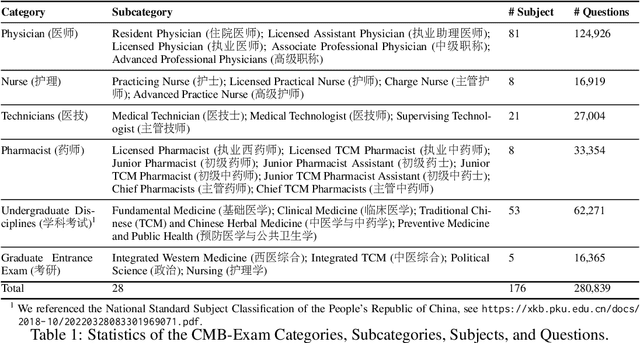

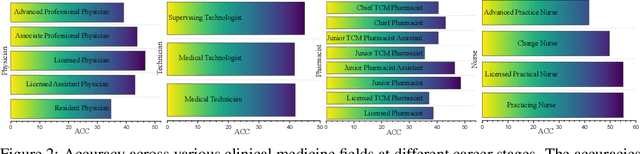
Large Language Models (LLMs) provide a possibility to make a great breakthrough in medicine. The establishment of a standardized medical benchmark becomes a fundamental cornerstone to measure progression. However, medical environments in different regions have their local characteristics, e.g., the ubiquity and significance of traditional Chinese medicine within China. Therefore, merely translating English-based medical evaluation may result in \textit{contextual incongruities} to a local region. To solve the issue, we propose a localized medical benchmark called CMB, a Comprehensive Medical Benchmark in Chinese, designed and rooted entirely within the native Chinese linguistic and cultural framework. While traditional Chinese medicine is integral to this evaluation, it does not constitute its entirety. Using this benchmark, we have evaluated several prominent large-scale LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. It is worth noting that our benchmark is not devised as a leaderboard competition but as an instrument for self-assessment of model advancements. We hope this benchmark could facilitate the widespread adoption and enhancement of medical LLMs within China. Check details in \url{https://cmedbenchmark.llmzoo.com/}.
Reduce Computational Complexity for Convolutional Layers by Skipping Zeros
Jul 12, 2023

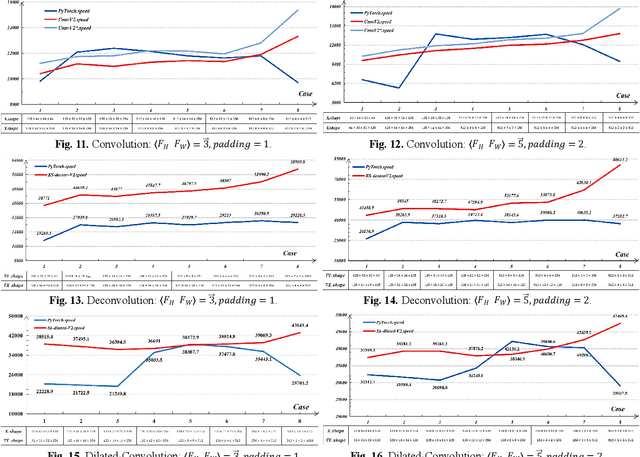
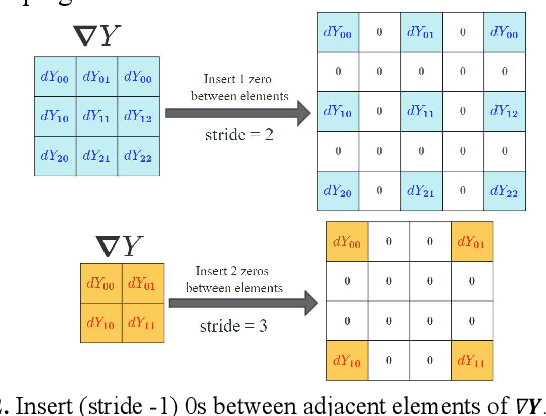
Deep neural networks rely on parallel processors for acceleration. To design operators for them, it requires not only good algorithm to reduce complexity, but also sufficient utilization of hardwares. Convolutional layers mainly contain 3 kinds of operators: convolution in forward propagation, deconvolution and dilated-convolution in backward propagation. When executing these operators, 0s are always added to tensors, causing redundant calculations. This paper gives C-K-S algorithm (ConvV2, KS-deconv, Sk-dilated), which skips these 0s in two ways: trim the filters to exclude padded 0s; transform sparse tensors to dense tensors, to avoid inserted 0s in deconvolution and dilated-convolution. In contrast to regular convolution, deconvolution is hard to accelerate due to its complicacy. This paper provides high-performance GPU implementations of C-K-S, and verifies their effectiveness with comparison to PyTorch. According to the experiments, C-K-S has advantages over PyTorch in certain cases, especially in deconvolution on small feature-maps. Further enhancement of C-K-S can be done by making full optimizations oriented at specific GPU architectures.
HuatuoGPT, towards Taming Language Model to Be a Doctor
May 24, 2023
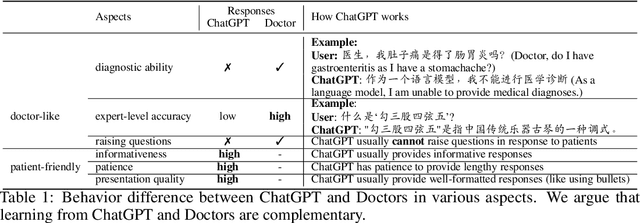
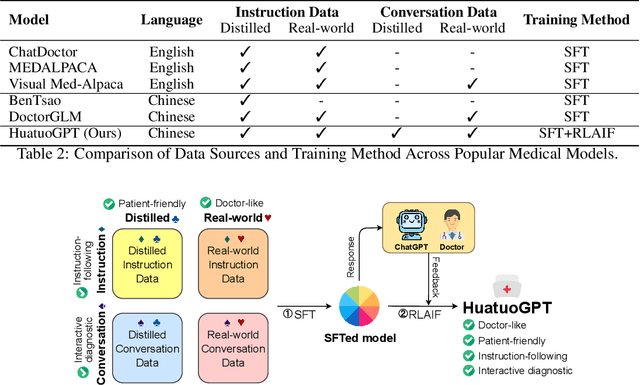
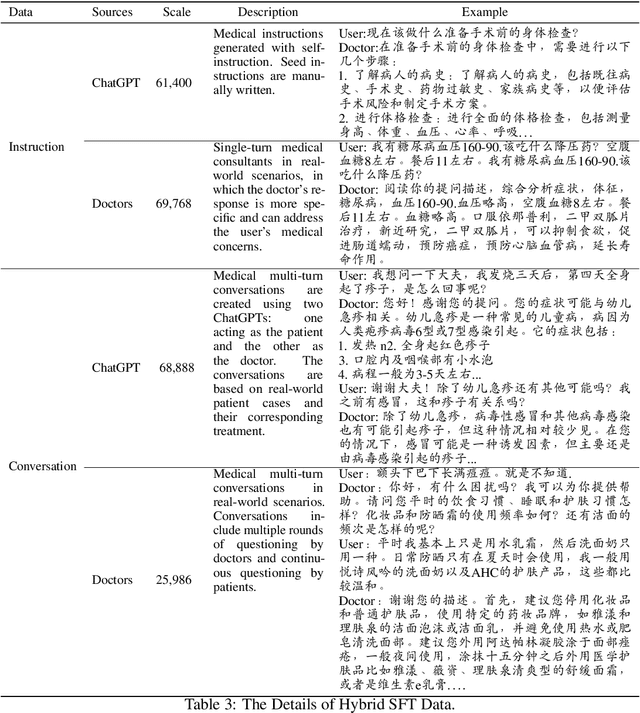
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both \textit{distilled data from ChatGPT} and \textit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
Dragon-Alpha&cu32: A Java-based Tensor Computing Framework With its High-Performance CUDA Library
May 15, 2023



Java is very powerful, but in Deep Learning field, its capabilities probably has not been sufficiently exploited. Compared to the Java-based deep-learning-frameworks, the Python-based (PyTorch, TensorFlow, etc) are undoubtedly the mainstream, due to their easy-to-use, flexibility and better ecosystem. Dragon-Alpha is a Java-based Tensor Computing Framework, with easy-to-use, high-scalability and high-performance, trying to break Java's dilemma in deep learning field and make it more effective. Dragon-Alpha supports different levels of APIs, and can be used as a deep-learning-framework through its user-friendly high-level APIs. Dragon-Alpha has potential to aggregate computing-power across heterogeneous platforms and devices, based on its multi-layer architecture and Java's big-data ecosystem. Dragon-Alpha has its asynchronized APIs to improve parallelism, and highly-optimized CUDA library cu32 which adopts unique convolution\deconvolution operators for small feature maps. The experiments show that, compared to PyTorch&cuDNN, Dragon-Alpha&cu32 costs less time and memory (75.38% to 97.32%, 29.2% to 66.4%), to train some typical neural networks (AlexNet, VGG, GoogleNet, ResNet) on Cifar-10.