 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce Computational Complexity for Convolutional Layers by Skipping Zeros
Jul 12, 2023

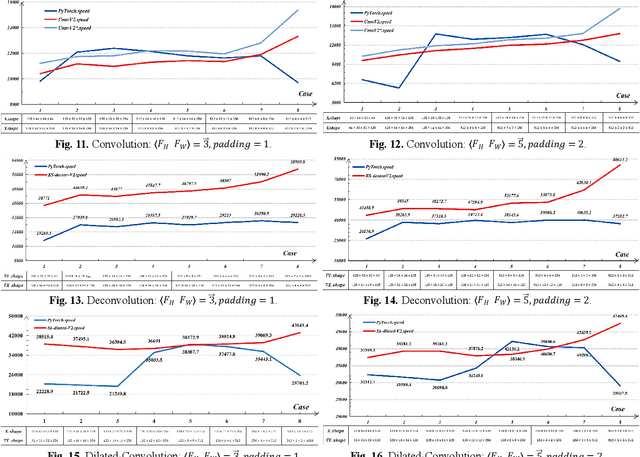
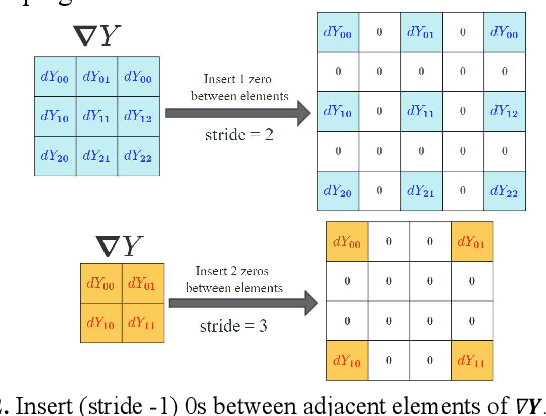
Deep neural networks rely on parallel processors for acceleration. To design operators for them, it requires not only good algorithm to reduce complexity, but also sufficient utilization of hardwares. Convolutional layers mainly contain 3 kinds of operators: convolution in forward propagation, deconvolution and dilated-convolution in backward propagation. When executing these operators, 0s are always added to tensors, causing redundant calculations. This paper gives C-K-S algorithm (ConvV2, KS-deconv, Sk-dilated), which skips these 0s in two ways: trim the filters to exclude padded 0s; transform sparse tensors to dense tensors, to avoid inserted 0s in deconvolution and dilated-convolution. In contrast to regular convolution, deconvolution is hard to accelerate due to its complicacy. This paper provides high-performance GPU implementations of C-K-S, and verifies their effectiveness with comparison to PyTorch. According to the experiments, C-K-S has advantages over PyTorch in certain cases, especially in deconvolution on small feature-maps. Further enhancement of C-K-S can be done by making full optimizations oriented at specific GPU architectures.