 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025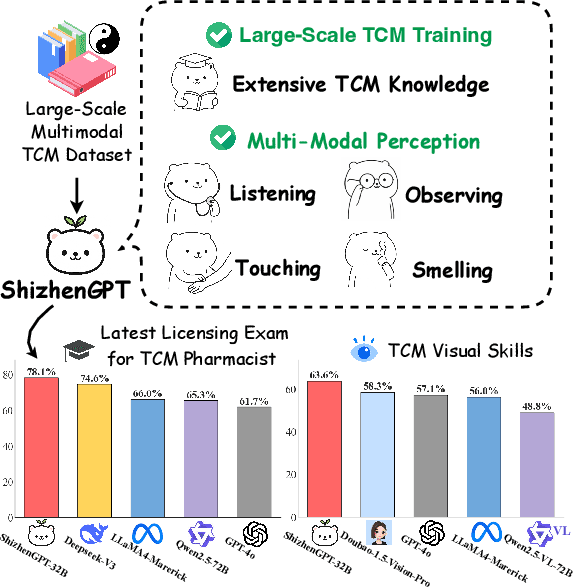
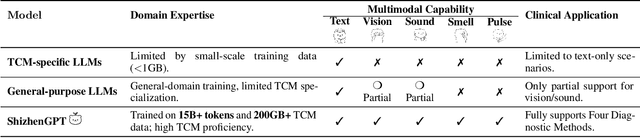
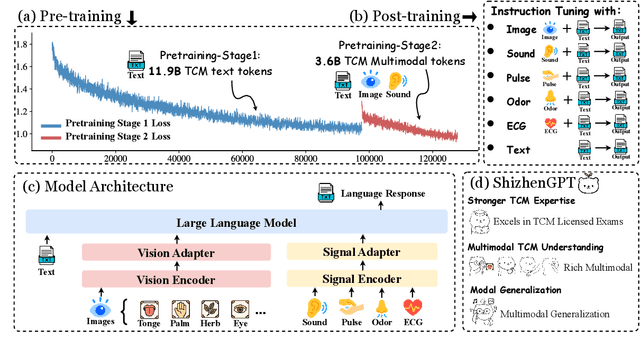
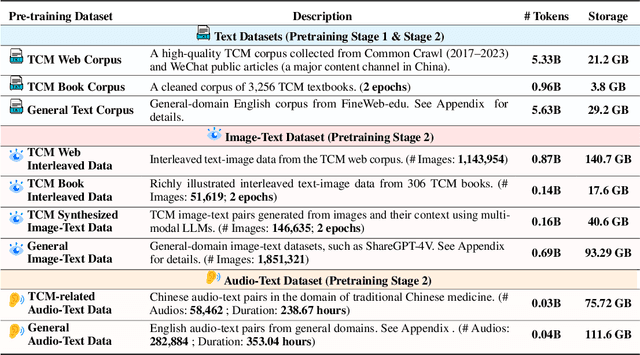
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Towards Assessing Medical Ethics from Knowledge to Practice
Aug 07, 2025The integration of large language models into healthcare necessitates a rigorous evaluation of their ethical reasoning, an area current benchmarks often overlook. We introduce PrinciplismQA, a comprehensive benchmark with 3,648 questions designed to systematically assess LLMs' alignment with core medical ethics. Grounded in Principlism, our benchmark features a high-quality dataset. This includes multiple-choice questions curated from authoritative textbooks and open-ended questions sourced from authoritative medical ethics case study literature, all validated by medical experts. Our experiments reveal a significant gap between models' ethical knowledge and their practical application, especially in dynamically applying ethical principles to real-world scenarios. Most LLMs struggle with dilemmas concerning Beneficence, often over-emphasizing other principles. Frontier closed-source models, driven by strong general capabilities, currently lead the benchmark. Notably, medical domain fine-tuning can enhance models' overall ethical competence, but further progress requires better alignment with medical ethical knowledge. PrinciplismQA offers a scalable framework to diagnose these specific ethical weaknesses, paving the way for more balanced and responsible medical AI.
Large Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025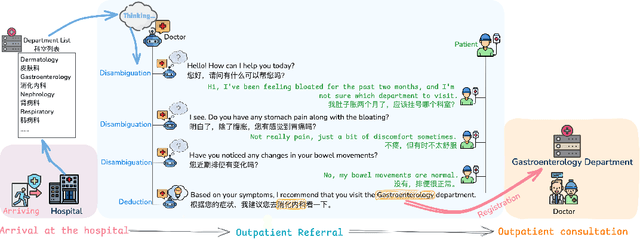
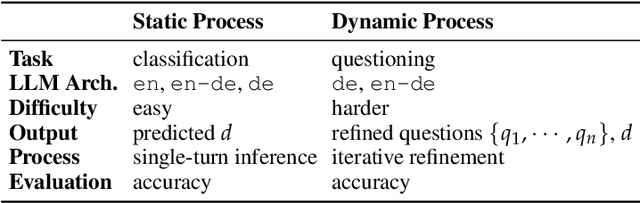
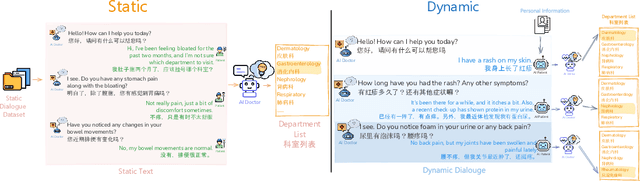
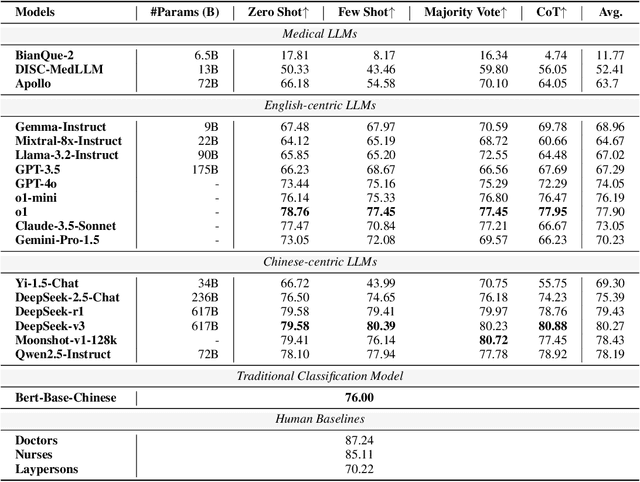
Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
LLMs for Doctors: Leveraging Medical LLMs to Assist Doctors, Not Replace Them
Jun 26, 2024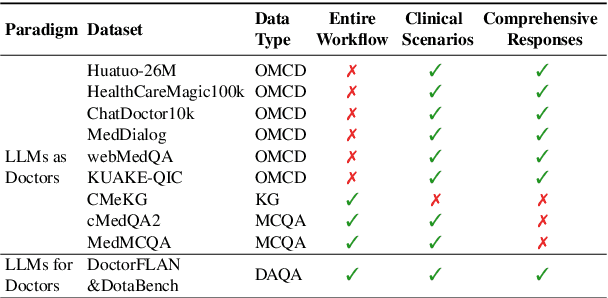
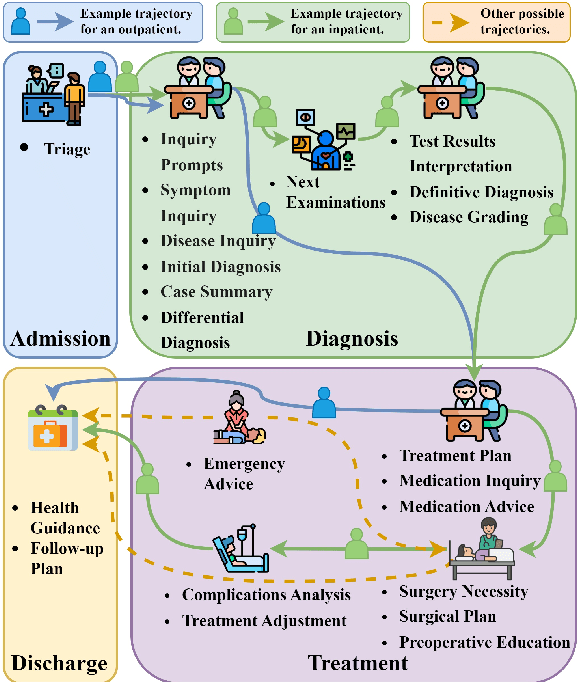
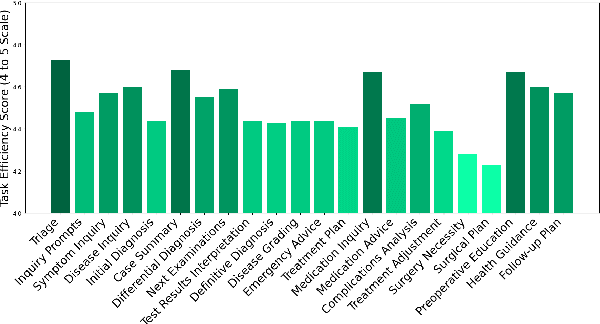
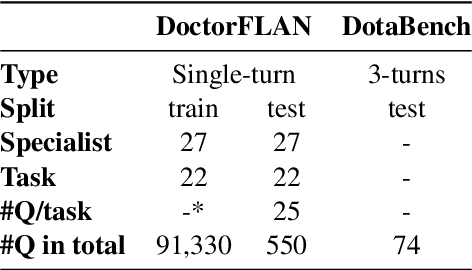
The recent success of Large Language Models (LLMs) has had a significant impact on the healthcare field, providing patients with medical advice, diagnostic information, and more. However, due to a lack of professional medical knowledge, patients are easily misled by generated erroneous information from LLMs, which may result in serious medical problems. To address this issue, we focus on tuning the LLMs to be medical assistants who collaborate with more experienced doctors. We first conduct a two-stage survey by inspiration-feedback to gain a broad understanding of the real needs of doctors for medical assistants. Based on this, we construct a Chinese medical dataset called DoctorFLAN to support the entire workflow of doctors, which includes 92K Q\&A samples from 22 tasks and 27 specialists. Moreover, we evaluate LLMs in doctor-oriented scenarios by constructing the DoctorFLAN-\textit{test} containing 550 single-turn Q\&A and DotaBench containing 74 multi-turn conversations. The evaluation results indicate that being a medical assistant still poses challenges for existing open-source models, but DoctorFLAN can help them significantly. It demonstrates that the doctor-oriented dataset and benchmarks we construct can complement existing patient-oriented work and better promote medical LLMs research.
GCS-ICHNet: Assessment of Intracerebral Hemorrhage Prognosis using Self-Attention with Domain Knowledge Integration
Nov 08, 2023



Intracerebral Hemorrhage (ICH) is a severe condition resulting from damaged brain blood vessel ruptures, often leading to complications and fatalities. Timely and accurate prognosis and management are essential due to its high mortality rate. However, conventional methods heavily rely on subjective clinician expertise, which can lead to inaccurate diagnoses and delays in treatment. Artificial intelligence (AI) models have been explored to assist clinicians, but many prior studies focused on model modification without considering domain knowledge. This paper introduces a novel deep learning algorithm, GCS-ICHNet, which integrates multimodal brain CT image data and the Glasgow Coma Scale (GCS) score to improve ICH prognosis. The algorithm utilizes a transformer-based fusion module for assessment. GCS-ICHNet demonstrates high sensitivity 81.03% and specificity 91.59%, outperforming average clinicians and other state-of-the-art methods.
CMB: A Comprehensive Medical Benchmark in Chinese
Aug 17, 2023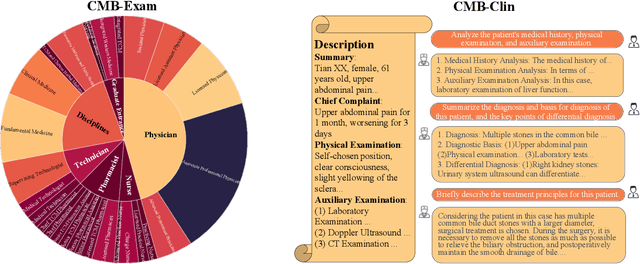
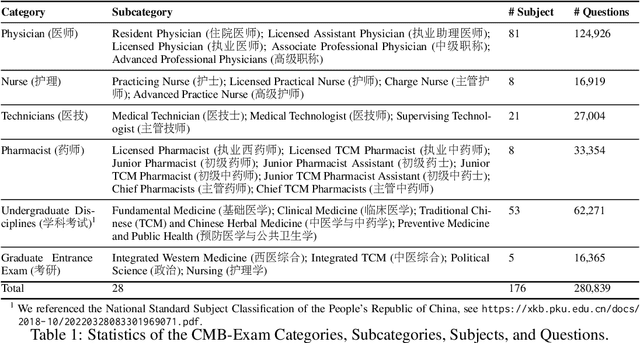

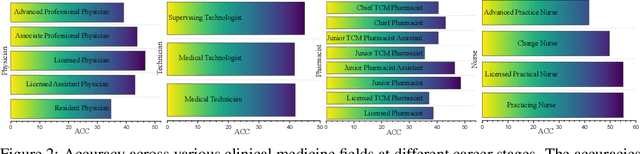
Large Language Models (LLMs) provide a possibility to make a great breakthrough in medicine. The establishment of a standardized medical benchmark becomes a fundamental cornerstone to measure progression. However, medical environments in different regions have their local characteristics, e.g., the ubiquity and significance of traditional Chinese medicine within China. Therefore, merely translating English-based medical evaluation may result in \textit{contextual incongruities} to a local region. To solve the issue, we propose a localized medical benchmark called CMB, a Comprehensive Medical Benchmark in Chinese, designed and rooted entirely within the native Chinese linguistic and cultural framework. While traditional Chinese medicine is integral to this evaluation, it does not constitute its entirety. Using this benchmark, we have evaluated several prominent large-scale LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. It is worth noting that our benchmark is not devised as a leaderboard competition but as an instrument for self-assessment of model advancements. We hope this benchmark could facilitate the widespread adoption and enhancement of medical LLMs within China. Check details in \url{https://cmedbenchmark.llmzoo.com/}.
HuatuoGPT, towards Taming Language Model to Be a Doctor
May 24, 2023
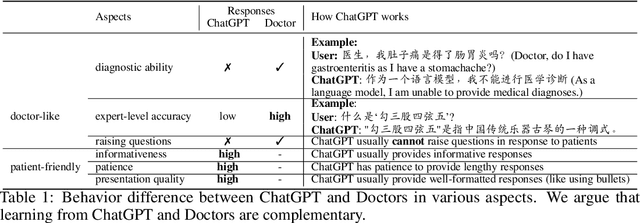
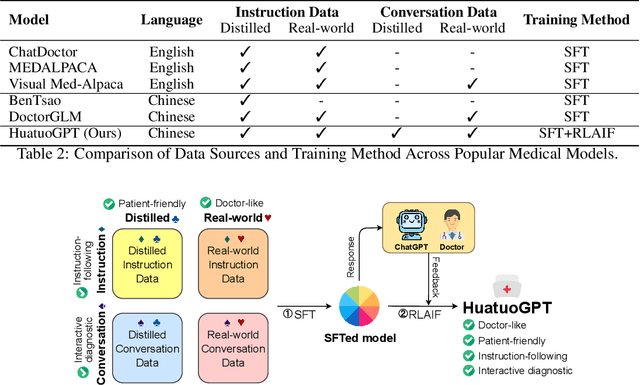
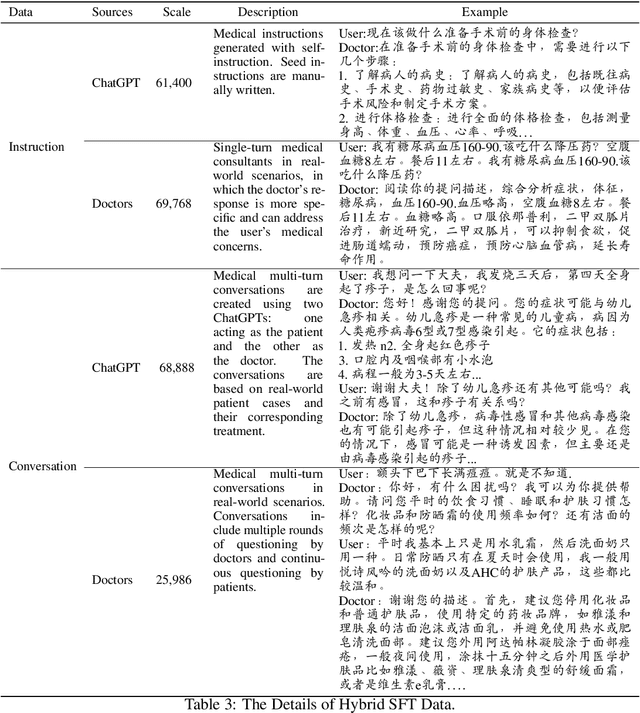
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both \textit{distilled data from ChatGPT} and \textit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.