 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherRemover: All-in-one Adverse Weather Removal with Multi-scale Feature Map Compression
Apr 08, 2026Photographs taken in adverse weather conditions often suffer from blurriness, occlusion, and low brightness due to interference from rain, snow, and fog. These issues can significantly hinder the performance of subsequent computer vision tasks, making the removal of weather effects a crucial step in image enhancement. Existing methods primarily target specific weather conditions, with only a few capable of handling multiple weather scenarios. However, mainstream approaches often overlook performance considerations, resulting in large parameter sizes, long inference times, and high memory costs. In this study, we introduce the WeatherRemover model, designed to enhance the restoration of images affected by various weather conditions while balancing performance. Our model adopts a UNet-like structure with a gating mechanism and a multi-scale pyramid vision Transformer. It employs channel-wise attention derived from convolutional neural networks to optimize feature extraction, while linear spatial reduction helps curtail the computational demands of attention. The gating mechanisms, strategically placed within the feed-forward and downsampling phases, refine the processing of information by selectively addressing redundancy and mitigating its influence on learning. This approach facilitates the adaptive selection of essential data, ensuring superior restoration and maximizing efficiency. Additionally, our lightweight model achieves an optimal balance between restoration quality, parameter efficiency, computational overhead, and memory usage, distinguishing it from other multi-weather models, thereby meeting practical application demands effectively. The source code is available at https://github.com/RICKand-MORTY/WeatherRemover.
USCNet: Transformer-Based Multimodal Fusion with Segmentation Guidance for Urolithiasis Classification
Apr 08, 2026Kidney stone disease ranks among the most prevalent conditions in urology, and understanding the composition of these stones is essential for creating personalized treatment plans and preventing recurrence. Current methods for analyzing kidney stones depend on postoperative specimens, which prevents rapid classification before surgery. To overcome this limitation, we introduce a new approach called the Urinary Stone Segmentation and Classification Network (USCNet). This innovative method allows for precise preoperative classification of kidney stones by integrating Computed Tomography (CT) images with clinical data from Electronic Health Records (EHR). USCNet employs a Transformer-based multimodal fusion framework with CT-EHR attention and segmentation-guided attention modules for accurate classification. Moreover, a dynamic loss function is introduced to effectively balance the dual objectives of segmentation and classification. Experiments on an in-house kidney stone dataset show that USCNet demonstrates outstanding performance across all evaluation metrics, with its classification efficacy significantly surpassing existing mainstream methods. This study presents a promising solution for the precise preoperative classification of kidney stones, offering substantial clinical benefits. The source code has been made publicly available: https://github.com/ZhangSongqi0506/KidneyStone.
Balancing Efficiency and Restoration: Lightweight Mamba-Based Model for CT Metal Artifact Reduction
Apr 08, 2026In computed tomography imaging, metal implants frequently generate severe artifacts that compromise image quality and hinder diagnostic accuracy. There are three main challenges in the existing methods: the deterioration of organ and tissue structures, dependence on sinogram data, and an imbalance between resource use and restoration efficiency. Addressing these issues, we introduce MARMamba, which effectively eliminates artifacts caused by metals of different sizes while maintaining the integrity of the original anatomical structures of the image. Furthermore, this model only focuses on CT images affected by metal artifacts, thus negating the requirement for additional input data. The model is a streamlined UNet architecture, which incorporates multi-scale Mamba (MS-Mamba) as its core module. Within MS-Mamba, a flip mamba block captures comprehensive contextual information by analyzing images from multiple orientations. Subsequently, the average maximum feed-forward network integrates critical features with average features to suppress the artifacts. This combination allows MARMamba to reduce artifacts efficiently. The experimental results demonstrate that our model excels in reducing metal artifacts, offering distinct advantages over other models. It also strikes an optimal balance between computational demands, memory usage, and the number of parameters, highlighting its practical utility in the real world. The code of the presented model is available at: https://github.com/RICKand-MORTY/MARMamba.
DGSAN: Dual-Graph Spatiotemporal Attention Network for Pulmonary Nodule Malignancy Prediction
Dec 24, 2025Lung cancer continues to be the leading cause of cancer-related deaths globally. Early detection and diagnosis of pulmonary nodules are essential for improving patient survival rates. Although previous research has integrated multimodal and multi-temporal information, outperforming single modality and single time point, the fusion methods are limited to inefficient vector concatenation and simple mutual attention, highlighting the need for more effective multimodal information fusion. To address these challenges, we introduce a Dual-Graph Spatiotemporal Attention Network, which leverages temporal variations and multimodal data to enhance the accuracy of predictions. Our methodology involves developing a Global-Local Feature Encoder to better capture the local, global, and fused characteristics of pulmonary nodules. Additionally, a Dual-Graph Construction method organizes multimodal features into inter-modal and intra-modal graphs. Furthermore, a Hierarchical Cross-Modal Graph Fusion Module is introduced to refine feature integration. We also compiled a novel multimodal dataset named the NLST-cmst dataset as a comprehensive source of support for related research. Our extensive experiments, conducted on both the NLST-cmst and curated CSTL-derived datasets, demonstrate that our DGSAN significantly outperforms state-of-the-art methods in classifying pulmonary nodules with exceptional computational efficiency.
GraphMMP: A Graph Neural Network Model with Mutual Information and Global Fusion for Multimodal Medical Prognosis
Aug 24, 2025In the field of multimodal medical data analysis, leveraging diverse types of data and understanding their hidden relationships continues to be a research focus. The main challenges lie in effectively modeling the complex interactions between heterogeneous data modalities with distinct characteristics while capturing both local and global dependencies across modalities. To address these challenges, this paper presents a two-stage multimodal prognosis model, GraphMMP, which is based on graph neural networks. The proposed model constructs feature graphs using mutual information and features a global fusion module built on Mamba, which significantly boosts prognosis performance. Empirical results show that GraphMMP surpasses existing methods on datasets related to liver prognosis and the METABRIC study, demonstrating its effectiveness in multimodal medical prognosis tasks.
Small Lesions-aware Bidirectional Multimodal Multiscale Fusion Network for Lung Disease Classification
Aug 06, 2025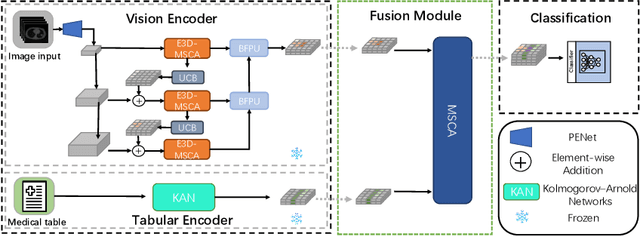
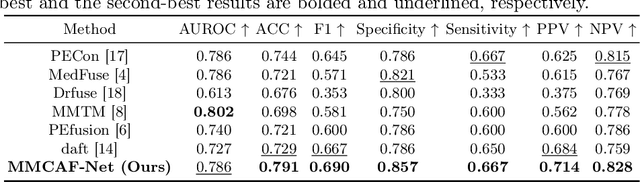
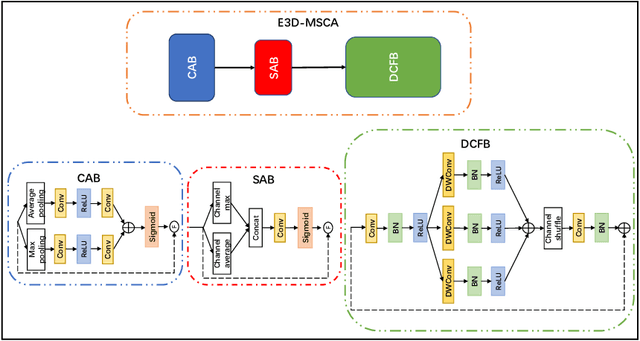
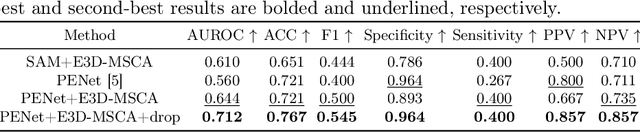
The diagnosis of medical diseases faces challenges such as the misdiagnosis of small lesions. Deep learning, particularly multimodal approaches, has shown great potential in the field of medical disease diagnosis. However, the differences in dimensionality between medical imaging and electronic health record data present challenges for effective alignment and fusion. To address these issues, we propose the Multimodal Multiscale Cross-Attention Fusion Network (MMCAF-Net). This model employs a feature pyramid structure combined with an efficient 3D multi-scale convolutional attention module to extract lesion-specific features from 3D medical images. To further enhance multimodal data integration, MMCAF-Net incorporates a multi-scale cross-attention module, which resolves dimensional inconsistencies, enabling more effective feature fusion. We evaluated MMCAF-Net on the Lung-PET-CT-Dx dataset, and the results showed a significant improvement in diagnostic accuracy, surpassing current state-of-the-art methods. The code is available at https://github.com/yjx1234/MMCAF-Net
ITCFN: Incomplete Triple-Modal Co-Attention Fusion Network for Mild Cognitive Impairment Conversion Prediction
Jan 20, 2025


Alzheimer's disease (AD) is a common neurodegenerative disease among the elderly. Early prediction and timely intervention of its prodromal stage, mild cognitive impairment (MCI), can decrease the risk of advancing to AD. Combining information from various modalities can significantly improve predictive accuracy. However, challenges such as missing data and heterogeneity across modalities complicate multimodal learning methods as adding more modalities can worsen these issues. Current multimodal fusion techniques often fail to adapt to the complexity of medical data, hindering the ability to identify relationships between modalities. To address these challenges, we propose an innovative multimodal approach for predicting MCI conversion, focusing specifically on the issues of missing positron emission tomography (PET) data and integrating diverse medical information. The proposed incomplete triple-modal MCI conversion prediction network is tailored for this purpose. Through the missing modal generation module, we synthesize the missing PET data from the magnetic resonance imaging and extract features using specifically designed encoders. We also develop a channel aggregation module and a triple-modal co-attention fusion module to reduce feature redundancy and achieve effective multimodal data fusion. Furthermore, we design a loss function to handle missing modality issues and align cross-modal features. These components collectively harness multimodal data to boost network performance. Experimental results on the ADNI1 and ADNI2 datasets show that our method significantly surpasses existing unimodal and other multimodal models. Our code is available at https://github.com/justinhxy/ITFC.
BS-LDM: Effective Bone Suppression in High-Resolution Chest X-Ray Images with Conditional Latent Diffusion Models
Dec 24, 2024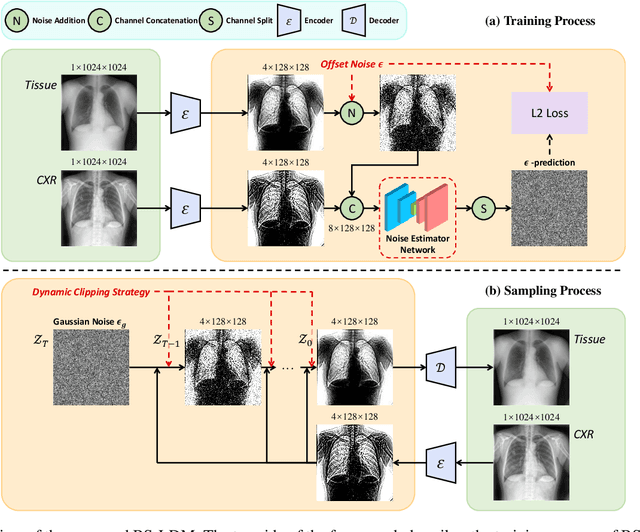
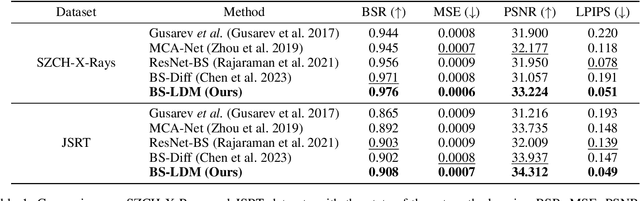
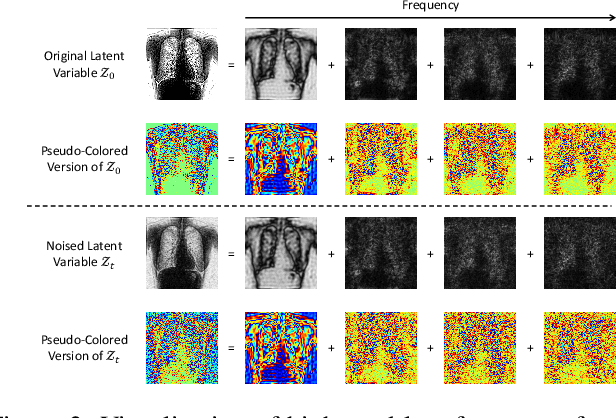
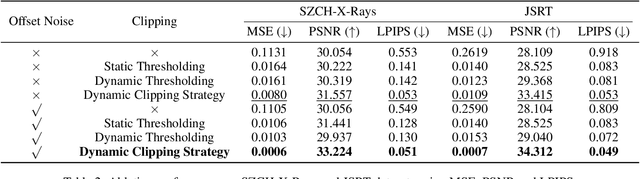
The interference of overlapping bones and pulmonary structures can reduce the effectiveness of Chest X-ray (CXR) examinations. Bone suppression techniques have been developed to improve diagnostic accuracy. Dual-energy subtraction (DES) imaging, a common method for bone suppression, is costly and exposes patients to higher radiation levels. Deep learning-based image generation methods have been proposed as alternatives, however, they often fail to produce high-quality and high-resolution images, resulting in the loss of critical lesion information and texture details. To address these issues, in this paper, we introduce an end-to-end framework for bone suppression in high-resolution CXR images, termed BS-LDM. This framework employs a conditional latent diffusion model to generate high-resolution soft tissue images with fine detail and critical lung pathology by performing bone suppression in the latent space. We implement offset noise during the noise addition phase of the training process to better render low-frequency information in soft tissue images. Additionally, we introduce a dynamic clipping strategy during the sampling process to refine pixel intensity in the generated soft tissue images. We compiled a substantial and high-quality bone suppression dataset, SZCH-X-Rays, including high-resolution paired CXR and DES soft tissue images from 818 patients, collected from our partner hospitals. Moreover, we pre-processed 241 pairs of CXR and DES soft tissue images from the JSRT dataset, the largest publicly available dataset. Comprehensive experimental and clinical evaluations demonstrate that BS-LDM exhibits superior bone suppression capabilities, highlighting its significant clinical potential.
ICH-SCNet: Intracerebral Hemorrhage Segmentation and Prognosis Classification Network Using CLIP-guided SAM mechanism
Nov 07, 2024Intracerebral hemorrhage (ICH) is the most fatal subtype of stroke and is characterized by a high incidence of disability. Accurate segmentation of the ICH region and prognosis prediction are critically important for developing and refining treatment plans for post-ICH patients. However, existing approaches address these two tasks independently and predominantly focus on imaging data alone, thereby neglecting the intrinsic correlation between the tasks and modalities. This paper introduces a multi-task network, ICH-SCNet, designed for both ICH segmentation and prognosis classification. Specifically, we integrate a SAM-CLIP cross-modal interaction mechanism that combines medical text and segmentation auxiliary information with neuroimaging data to enhance cross-modal feature recognition. Additionally, we develop an effective feature fusion module and a multi-task loss function to improve performance further. Extensive experiments on an ICH dataset reveal that our approach surpasses other state-of-the-art methods. It excels in the overall performance of classification tasks and outperforms competing models in all segmentation task metrics.
LPUWF-LDM: Enhanced Latent Diffusion Model for Precise Late-phase UWF-FA Generation on Limited Dataset
Sep 01, 2024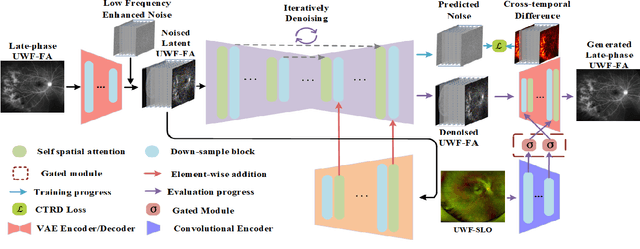
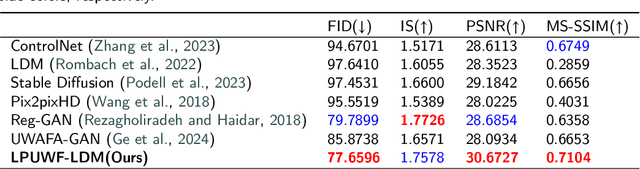
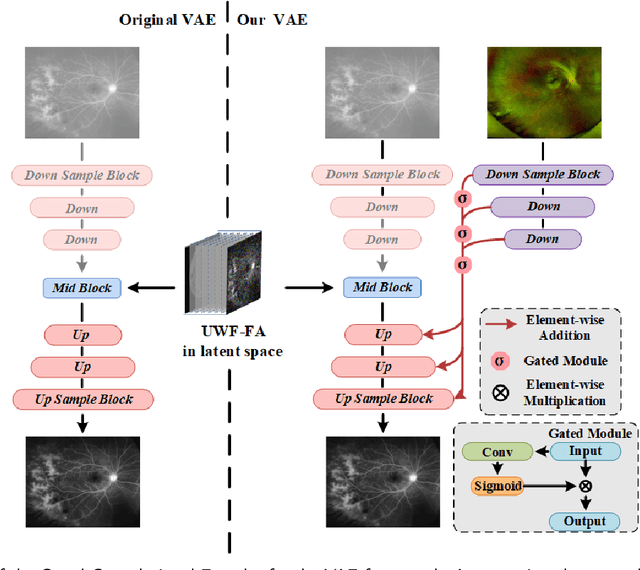

Ultra-Wide-Field Fluorescein Angiography (UWF-FA) enables precise identification of ocular diseases using sodium fluorescein, which can be potentially harmful. Existing research has developed methods to generate UWF-FA from Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) to reduce the adverse reactions associated with injections. However, these methods have been less effective in producing high-quality late-phase UWF-FA, particularly in lesion areas and fine details. Two primary challenges hinder the generation of high-quality late-phase UWF-FA: the scarcity of paired UWF-SLO and early/late-phase UWF-FA datasets, and the need for realistic generation at lesion sites and potential blood leakage regions. This study introduces an improved latent diffusion model framework to generate high-quality late-phase UWF-FA from limited paired UWF images. To address the challenges as mentioned earlier, our approach employs a module utilizing Cross-temporal Regional Difference Loss, which encourages the model to focus on the differences between early and late phases. Additionally, we introduce a low-frequency enhanced noise strategy in the diffusion forward process to improve the realism of medical images. To further enhance the mapping capability of the variational autoencoder module, especially with limited datasets, we implement a Gated Convolutional Encoder to extract additional information from conditional images. Our Latent Diffusion Model for Ultra-Wide-Field Late-Phase Fluorescein Angiography (LPUWF-LDM) effectively reconstructs fine details in late-phase UWF-FA and achieves state-of-the-art results compared to other existing methods when working with limited datasets. Our source code is available at: https://github.com/Tinysqua/****.