 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherRemover: All-in-one Adverse Weather Removal with Multi-scale Feature Map Compression
Apr 08, 2026Photographs taken in adverse weather conditions often suffer from blurriness, occlusion, and low brightness due to interference from rain, snow, and fog. These issues can significantly hinder the performance of subsequent computer vision tasks, making the removal of weather effects a crucial step in image enhancement. Existing methods primarily target specific weather conditions, with only a few capable of handling multiple weather scenarios. However, mainstream approaches often overlook performance considerations, resulting in large parameter sizes, long inference times, and high memory costs. In this study, we introduce the WeatherRemover model, designed to enhance the restoration of images affected by various weather conditions while balancing performance. Our model adopts a UNet-like structure with a gating mechanism and a multi-scale pyramid vision Transformer. It employs channel-wise attention derived from convolutional neural networks to optimize feature extraction, while linear spatial reduction helps curtail the computational demands of attention. The gating mechanisms, strategically placed within the feed-forward and downsampling phases, refine the processing of information by selectively addressing redundancy and mitigating its influence on learning. This approach facilitates the adaptive selection of essential data, ensuring superior restoration and maximizing efficiency. Additionally, our lightweight model achieves an optimal balance between restoration quality, parameter efficiency, computational overhead, and memory usage, distinguishing it from other multi-weather models, thereby meeting practical application demands effectively. The source code is available at https://github.com/RICKand-MORTY/WeatherRemover.
Balancing Efficiency and Restoration: Lightweight Mamba-Based Model for CT Metal Artifact Reduction
Apr 08, 2026In computed tomography imaging, metal implants frequently generate severe artifacts that compromise image quality and hinder diagnostic accuracy. There are three main challenges in the existing methods: the deterioration of organ and tissue structures, dependence on sinogram data, and an imbalance between resource use and restoration efficiency. Addressing these issues, we introduce MARMamba, which effectively eliminates artifacts caused by metals of different sizes while maintaining the integrity of the original anatomical structures of the image. Furthermore, this model only focuses on CT images affected by metal artifacts, thus negating the requirement for additional input data. The model is a streamlined UNet architecture, which incorporates multi-scale Mamba (MS-Mamba) as its core module. Within MS-Mamba, a flip mamba block captures comprehensive contextual information by analyzing images from multiple orientations. Subsequently, the average maximum feed-forward network integrates critical features with average features to suppress the artifacts. This combination allows MARMamba to reduce artifacts efficiently. The experimental results demonstrate that our model excels in reducing metal artifacts, offering distinct advantages over other models. It also strikes an optimal balance between computational demands, memory usage, and the number of parameters, highlighting its practical utility in the real world. The code of the presented model is available at: https://github.com/RICKand-MORTY/MARMamba.
Online Imitation Learning for Manipulation via Decaying Relative Correction through Teleoperation
Mar 19, 2025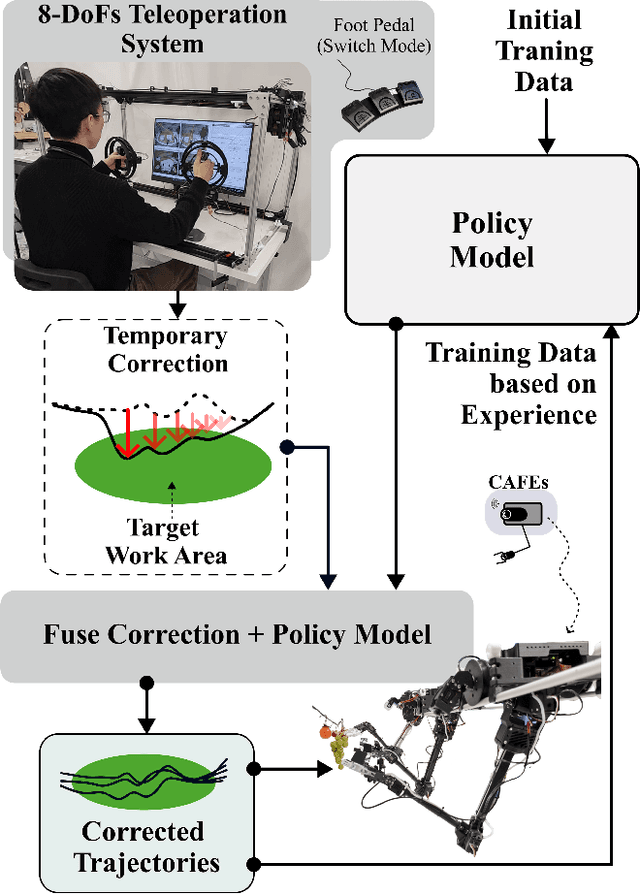
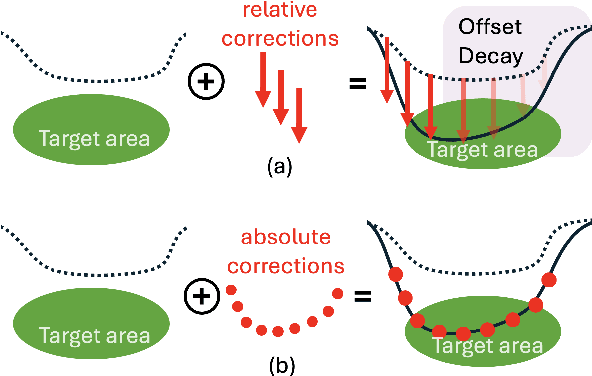
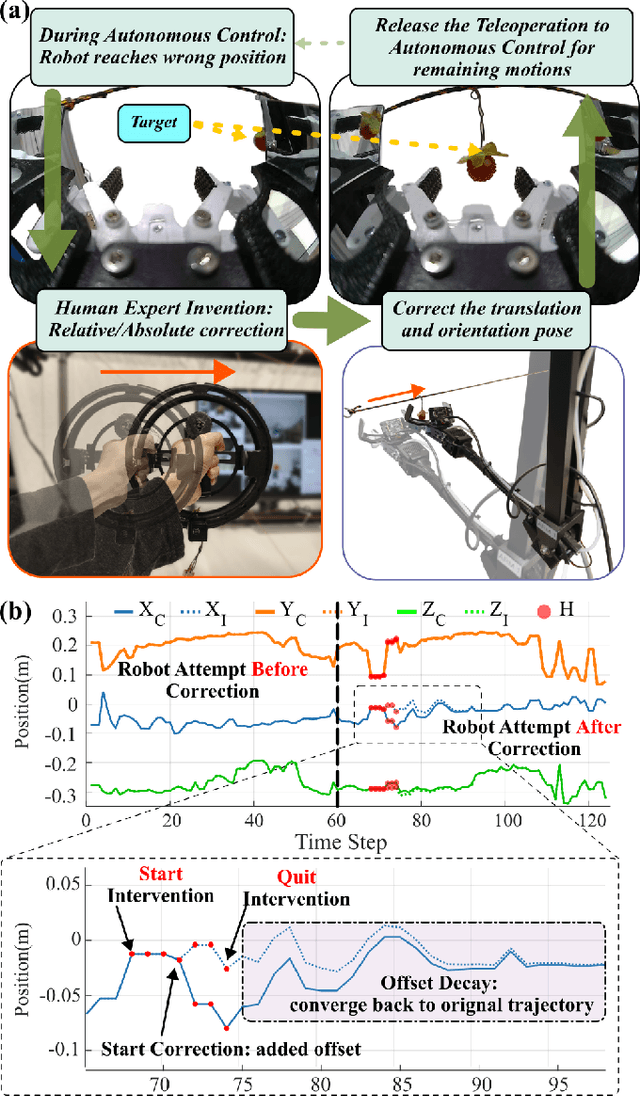
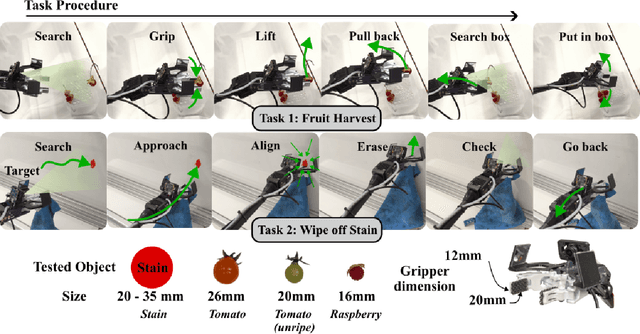
Teleoperated robotic manipulators enable the collection of demonstration data, which can be used to train control policies through imitation learning. However, such methods can require significant amounts of training data to develop robust policies or adapt them to new and unseen tasks. While expert feedback can significantly enhance policy performance, providing continuous feedback can be cognitively demanding and time-consuming for experts. To address this challenge, we propose to use a cable-driven teleoperation system which can provide spatial corrections with 6 degree of freedom to the trajectories generated by a policy model. Specifically, we propose a correction method termed Decaying Relative Correction (DRC) which is based upon the spatial offset vector provided by the expert and exists temporarily, and which reduces the intervention steps required by an expert. Our results demonstrate that DRC reduces the required expert intervention rate by 30\% compared to a standard absolute corrective method. Furthermore, we show that integrating DRC within an online imitation learning framework rapidly increases the success rate of manipulation tasks such as raspberry harvesting and cloth wiping.
Vision-Language-Action Model and Diffusion Policy Switching Enables Dexterous Control of an Anthropomorphic Hand
Oct 17, 2024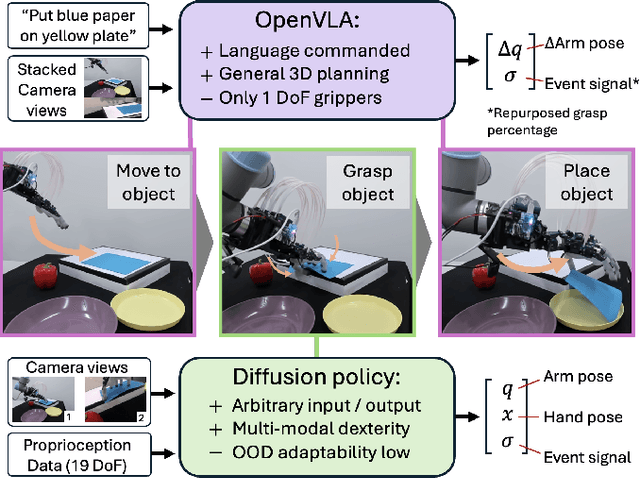
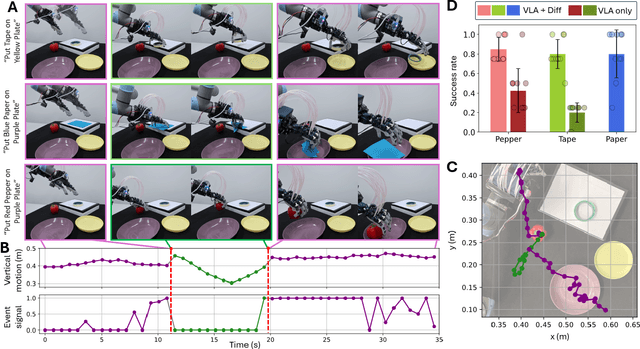

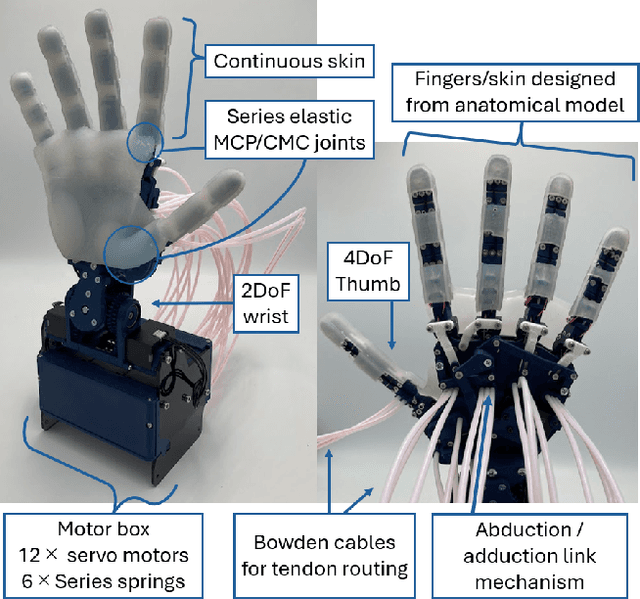
To advance autonomous dexterous manipulation, we propose a hybrid control method that combines the relative advantages of a fine-tuned Vision-Language-Action (VLA) model and diffusion models. The VLA model provides language commanded high-level planning, which is highly generalizable, while the diffusion model handles low-level interactions which offers the precision and robustness required for specific objects and environments. By incorporating a switching signal into the training-data, we enable event based transitions between these two models for a pick-and-place task where the target object and placement location is commanded through language. This approach is deployed on our anthropomorphic ADAPT Hand 2, a 13DoF robotic hand, which incorporates compliance through series elastic actuation allowing for resilience for any interactions: showing the first use of a multi-fingered hand controlled with a VLA model. We demonstrate this model switching approach results in a over 80\% success rate compared to under 40\% when only using a VLA model, enabled by accurate near-object arm motion by the VLA model and a multi-modal grasping motion with error recovery abilities from the diffusion model.
BS-Diff: Effective Bone Suppression Using Conditional Diffusion Models from Chest X-Ray Images
Nov 26, 2023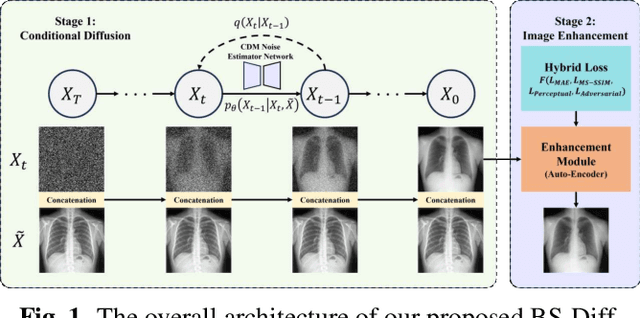
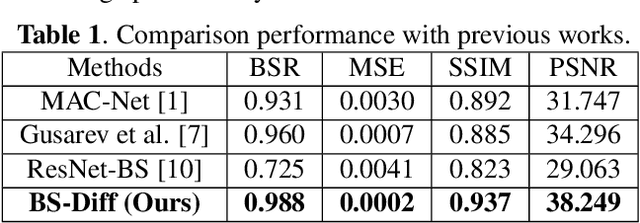
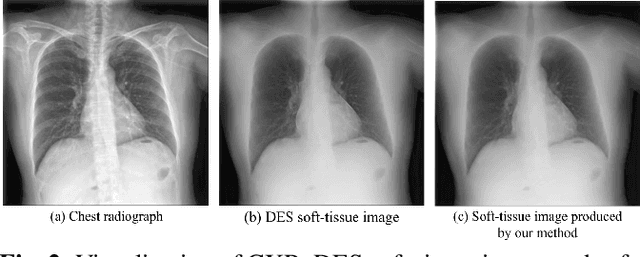
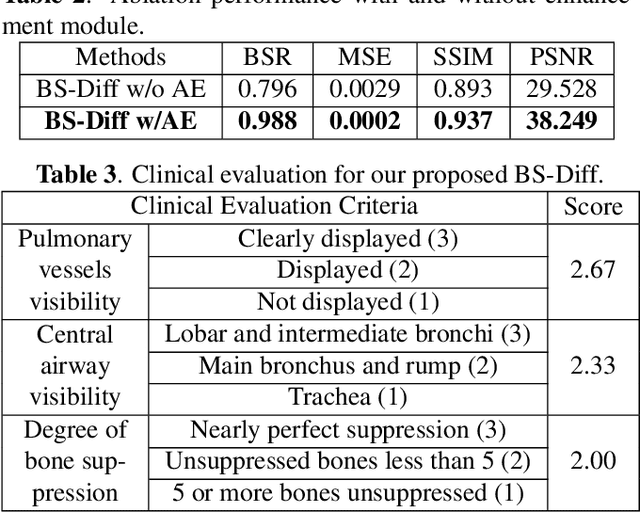
Chest X-rays (CXRs) are commonly utilized as a low-dose modality for lung screening. Nonetheless, the efficacy of CXRs is somewhat impeded, given that approximately 75% of the lung area overlaps with bone, which in turn hampers the detection and diagnosis of diseases. As a remedial measure, bone suppression techniques have been introduced. The current dual-energy subtraction imaging technique in the clinic requires costly equipment and subjects being exposed to high radiation. To circumvent these issues, deep learning-based image generation algorithms have been proposed. However, existing methods fall short in terms of producing high-quality images and capturing texture details, particularly with pulmonary vessels. To address these issues, this paper proposes a new bone suppression framework, termed BS-Diff, that comprises a conditional diffusion model equipped with a U-Net architecture and a simple enhancement module to incorporate an autoencoder. Our proposed network cannot only generate soft tissue images with a high bone suppression rate but also possesses the capability to capture fine image details. Additionally, we compiled the largest dataset since 2010, including data from 120 patients with high-definition, high-resolution paired CXRs and soft tissue images collected by our affiliated hospital. Extensive experiments, comparative analyses, ablation studies, and clinical evaluations indicate that the proposed BS-Diff outperforms several bone-suppression models across multiple metrics.