 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge8-DoFs Cable Driven Parallel Robots for Bimanual Teleportation
Apr 02, 2025



Teleoperation plays a critical role in intuitive robot control and imitation learning, particularly for complex tasks involving mobile manipulators with redundant degrees of freedom (DoFs). However, most existing master controllers are limited to 6-DoF spatial control and basic gripper control, making them insufficient for controlling high-DoF robots and restricting the operator to a small workspace. In this work, we present a novel, low-cost, high-DoF master controller based on Cable-Driven Parallel Robots (CDPRs), designed to overcome these limitations. The system decouples translation and orientation control, following a scalable 3 + 3 + n DoF structure: 3 DoFs for large-range translation using a CDPR, 3 DoFs for orientation using a gimbal mechanism, and n additional DoFs for gripper and redundant joint control. Its lightweight cable-driven design enables a large and adaptable workspace while minimizing actuator load. The end-effector remains stable without requiring continuous high-torque input, unlike most serial robot arms. We developed the first dual-arm CDPR-based master controller using cost-effective actuators and a simple mechanical structure. In demonstrations, the system successfully controlled an 8-DoF robotic arm with a 2-DoF pan-tilt camera, performing tasks such as pick-and-place, knot tying, object sorting, and tape application. The results show precise, versatile, and practical high-DoF teleoperation.
Control the Soft Robot Arm with its Physical Twin
Mar 21, 2025To exploit the compliant capabilities of soft robot arms we require controller which can exploit their physical capabilities. Teleoperation, leveraging a human in the loop, is a key step towards achieving more complex control strategies. Whilst teleoperation is widely used for rigid robots, for soft robots we require teleoperation methods where the configuration of the whole body is considered. We propose a method of using an identical 'physical twin', or demonstrator of the robot. This tendon robot can be back-driven, with the tendon lengths providing configuration perception, and enabling a direct mapping of tendon lengths for the execture. We demonstrate how this teleoperation across the entire configuration of the robot enables complex interactions with exploit the envrionment, such as squeezing into gaps. We also show how this method can generalize to robots which are a larger scale that the physical twin, and how, tuneability of the stiffness properties of the physical twin simplify its use.
Online Imitation Learning for Manipulation via Decaying Relative Correction through Teleoperation
Mar 19, 2025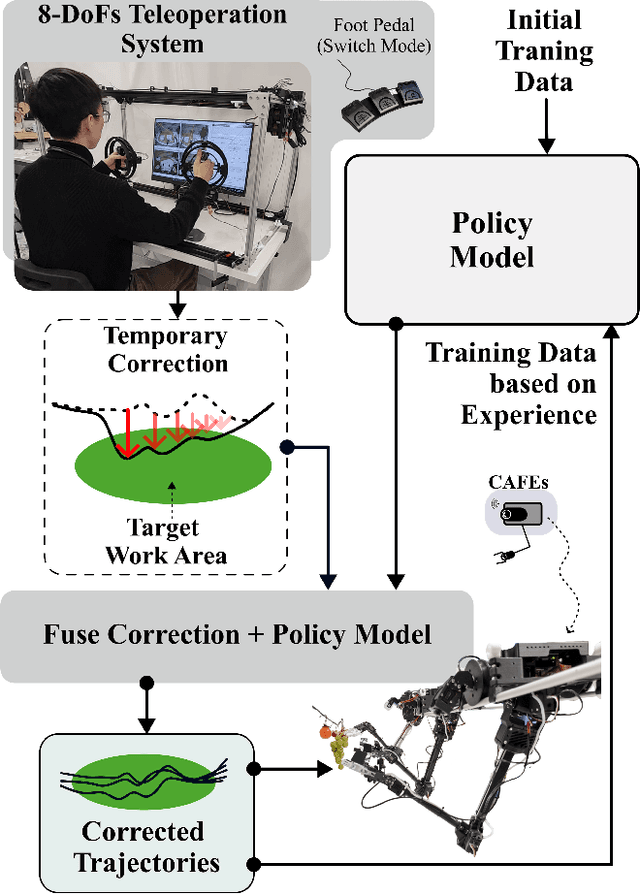
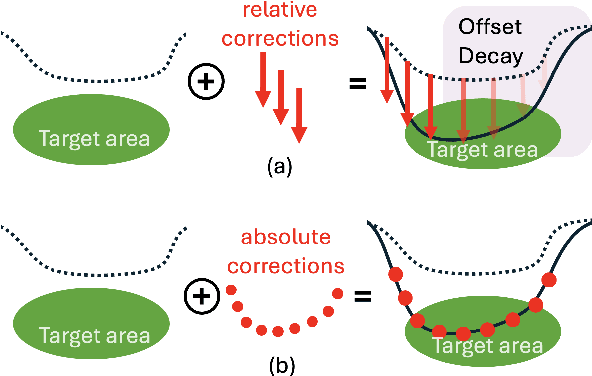
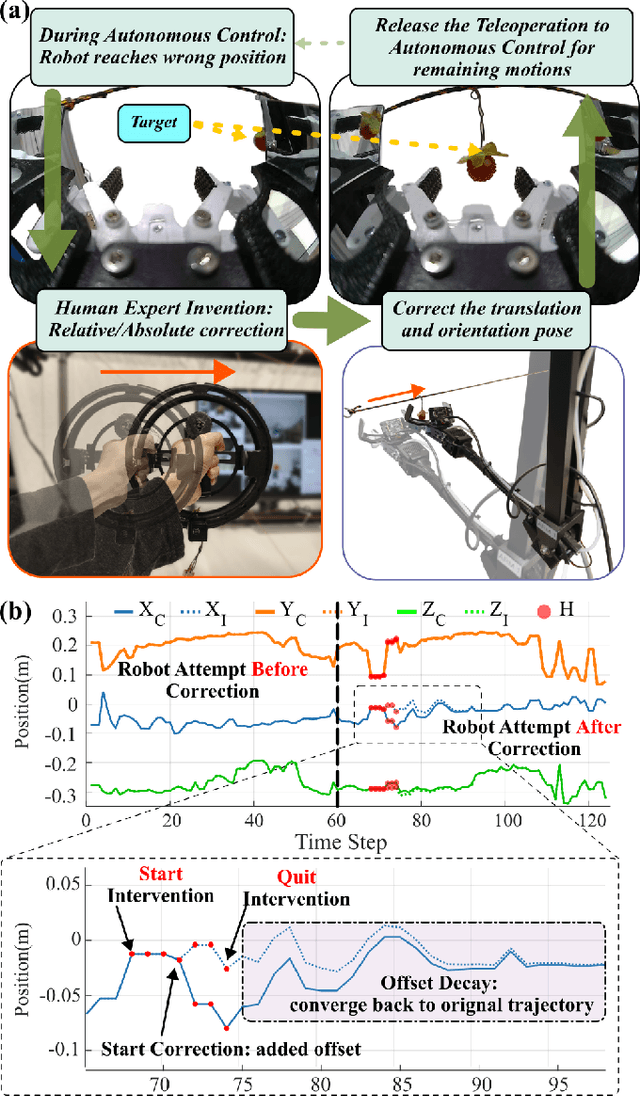
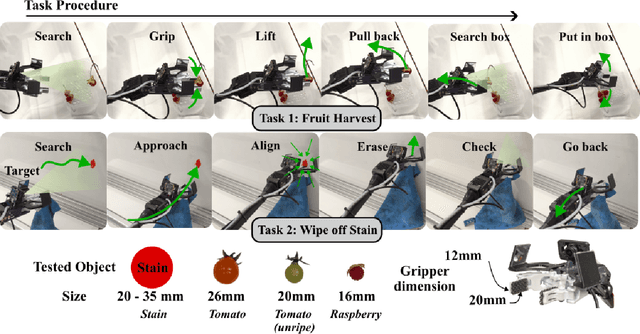
Teleoperated robotic manipulators enable the collection of demonstration data, which can be used to train control policies through imitation learning. However, such methods can require significant amounts of training data to develop robust policies or adapt them to new and unseen tasks. While expert feedback can significantly enhance policy performance, providing continuous feedback can be cognitively demanding and time-consuming for experts. To address this challenge, we propose to use a cable-driven teleoperation system which can provide spatial corrections with 6 degree of freedom to the trajectories generated by a policy model. Specifically, we propose a correction method termed Decaying Relative Correction (DRC) which is based upon the spatial offset vector provided by the expert and exists temporarily, and which reduces the intervention steps required by an expert. Our results demonstrate that DRC reduces the required expert intervention rate by 30\% compared to a standard absolute corrective method. Furthermore, we show that integrating DRC within an online imitation learning framework rapidly increases the success rate of manipulation tasks such as raspberry harvesting and cloth wiping.