 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Imitation Learning for Manipulation via Decaying Relative Correction through Teleoperation
Paper and Code
Mar 19, 2025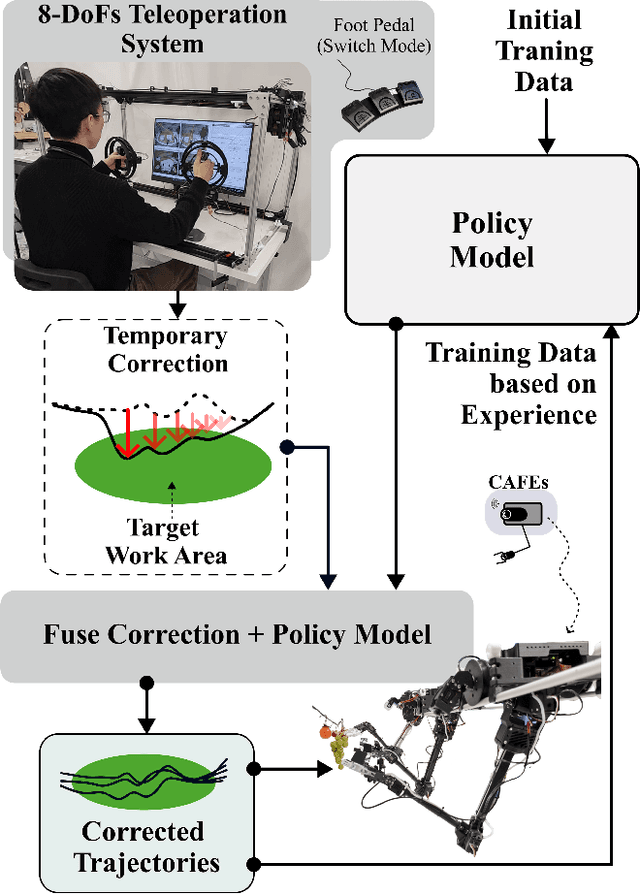
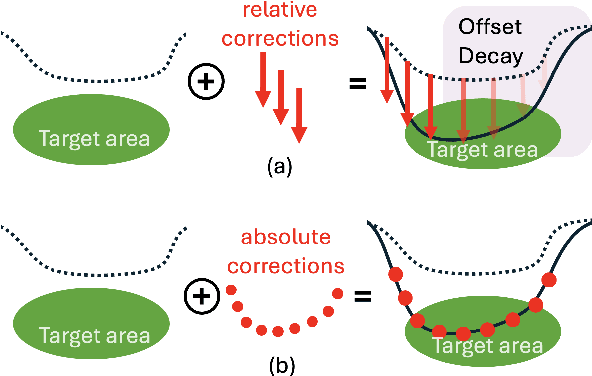
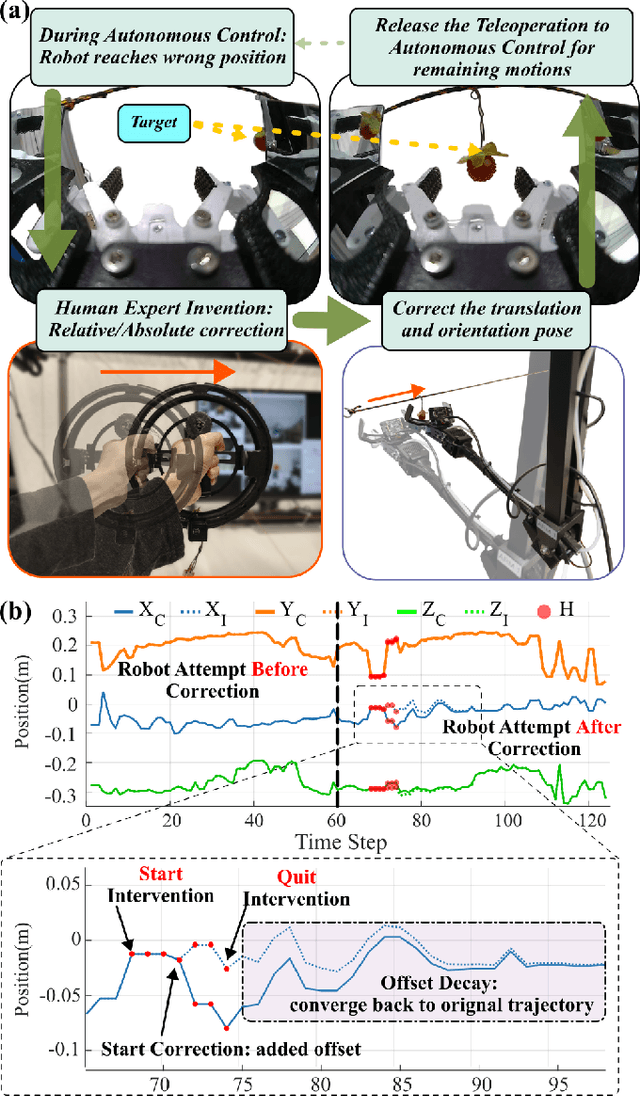
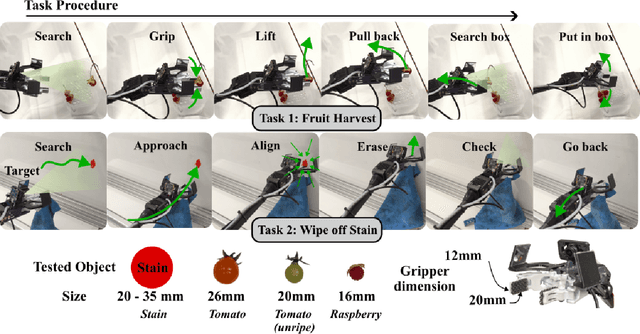
Teleoperated robotic manipulators enable the collection of demonstration data, which can be used to train control policies through imitation learning. However, such methods can require significant amounts of training data to develop robust policies or adapt them to new and unseen tasks. While expert feedback can significantly enhance policy performance, providing continuous feedback can be cognitively demanding and time-consuming for experts. To address this challenge, we propose to use a cable-driven teleoperation system which can provide spatial corrections with 6 degree of freedom to the trajectories generated by a policy model. Specifically, we propose a correction method termed Decaying Relative Correction (DRC) which is based upon the spatial offset vector provided by the expert and exists temporarily, and which reduces the intervention steps required by an expert. Our results demonstrate that DRC reduces the required expert intervention rate by 30\% compared to a standard absolute corrective method. Furthermore, we show that integrating DRC within an online imitation learning framework rapidly increases the success rate of manipulation tasks such as raspberry harvesting and cloth wiping.