 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBS-LDM: Effective Bone Suppression in High-Resolution Chest X-Ray Images with Conditional Latent Diffusion Models
Dec 24, 2024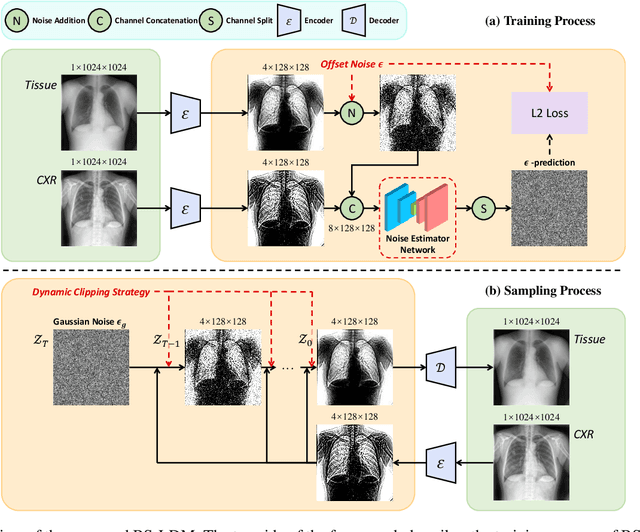
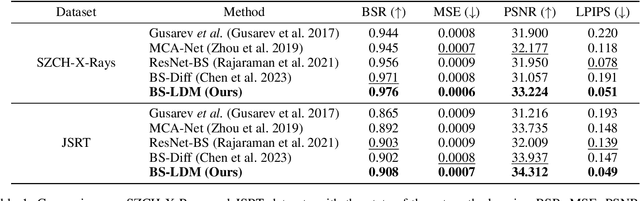
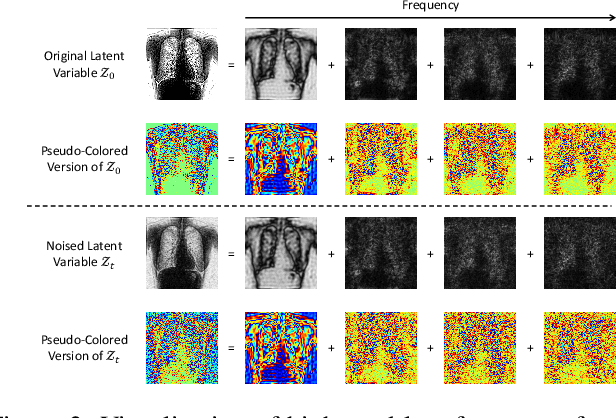
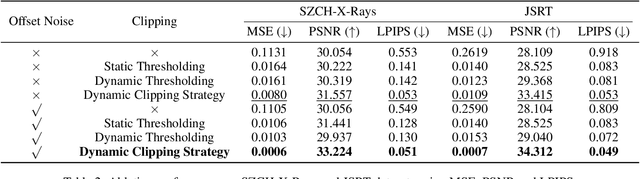
The interference of overlapping bones and pulmonary structures can reduce the effectiveness of Chest X-ray (CXR) examinations. Bone suppression techniques have been developed to improve diagnostic accuracy. Dual-energy subtraction (DES) imaging, a common method for bone suppression, is costly and exposes patients to higher radiation levels. Deep learning-based image generation methods have been proposed as alternatives, however, they often fail to produce high-quality and high-resolution images, resulting in the loss of critical lesion information and texture details. To address these issues, in this paper, we introduce an end-to-end framework for bone suppression in high-resolution CXR images, termed BS-LDM. This framework employs a conditional latent diffusion model to generate high-resolution soft tissue images with fine detail and critical lung pathology by performing bone suppression in the latent space. We implement offset noise during the noise addition phase of the training process to better render low-frequency information in soft tissue images. Additionally, we introduce a dynamic clipping strategy during the sampling process to refine pixel intensity in the generated soft tissue images. We compiled a substantial and high-quality bone suppression dataset, SZCH-X-Rays, including high-resolution paired CXR and DES soft tissue images from 818 patients, collected from our partner hospitals. Moreover, we pre-processed 241 pairs of CXR and DES soft tissue images from the JSRT dataset, the largest publicly available dataset. Comprehensive experimental and clinical evaluations demonstrate that BS-LDM exhibits superior bone suppression capabilities, highlighting its significant clinical potential.
UWAFA-GAN: Ultra-Wide-Angle Fluorescein Angiography Transformation via Multi-scale Generation and Registration Enhancement
May 01, 2024



Fundus photography, in combination with the ultra-wide-angle fundus (UWF) techniques, becomes an indispensable diagnostic tool in clinical settings by offering a more comprehensive view of the retina. Nonetheless, UWF fluorescein angiography (UWF-FA) necessitates the administration of a fluorescent dye via injection into the patient's hand or elbow unlike UWF scanning laser ophthalmoscopy (UWF-SLO). To mitigate potential adverse effects associated with injections, researchers have proposed the development of cross-modality medical image generation algorithms capable of converting UWF-SLO images into their UWF-FA counterparts. Current image generation techniques applied to fundus photography encounter difficulties in producing high-resolution retinal images, particularly in capturing minute vascular lesions. To address these issues, we introduce a novel conditional generative adversarial network (UWAFA-GAN) to synthesize UWF-FA from UWF-SLO. This approach employs multi-scale generators and an attention transmit module to efficiently extract both global structures and local lesions. Additionally, to counteract the image blurriness issue that arises from training with misaligned data, a registration module is integrated within this framework. Our method performs non-trivially on inception scores and details generation. Clinical user studies further indicate that the UWF-FA images generated by UWAFA-GAN are clinically comparable to authentic images in terms of diagnostic reliability. Empirical evaluations on our proprietary UWF image datasets elucidate that UWAFA-GAN outperforms extant methodologies. The code is accessible at https://github.com/Tinysqua/UWAFA-GAN.
BS-Diff: Effective Bone Suppression Using Conditional Diffusion Models from Chest X-Ray Images
Nov 26, 2023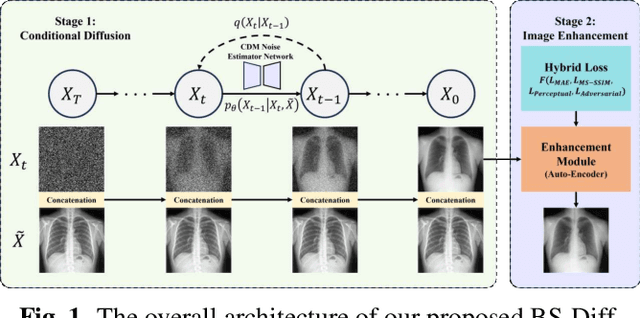
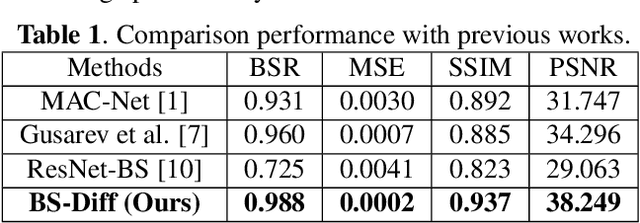
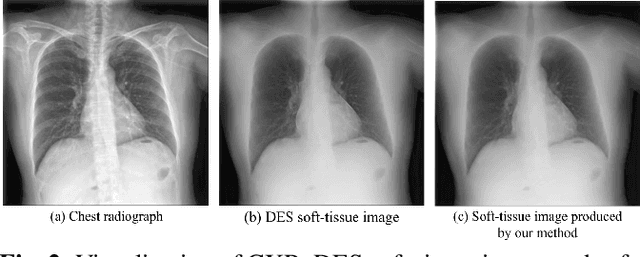
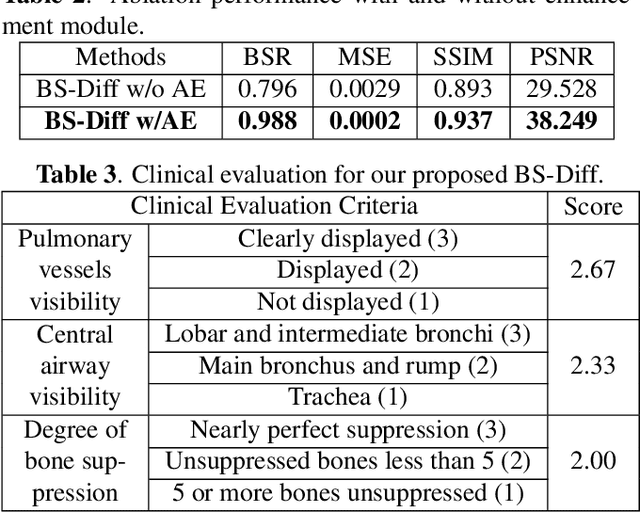
Chest X-rays (CXRs) are commonly utilized as a low-dose modality for lung screening. Nonetheless, the efficacy of CXRs is somewhat impeded, given that approximately 75% of the lung area overlaps with bone, which in turn hampers the detection and diagnosis of diseases. As a remedial measure, bone suppression techniques have been introduced. The current dual-energy subtraction imaging technique in the clinic requires costly equipment and subjects being exposed to high radiation. To circumvent these issues, deep learning-based image generation algorithms have been proposed. However, existing methods fall short in terms of producing high-quality images and capturing texture details, particularly with pulmonary vessels. To address these issues, this paper proposes a new bone suppression framework, termed BS-Diff, that comprises a conditional diffusion model equipped with a U-Net architecture and a simple enhancement module to incorporate an autoencoder. Our proposed network cannot only generate soft tissue images with a high bone suppression rate but also possesses the capability to capture fine image details. Additionally, we compiled the largest dataset since 2010, including data from 120 patients with high-definition, high-resolution paired CXRs and soft tissue images collected by our affiliated hospital. Extensive experiments, comparative analyses, ablation studies, and clinical evaluations indicate that the proposed BS-Diff outperforms several bone-suppression models across multiple metrics.
UWAT-GAN: Fundus Fluorescein Angiography Synthesis via Ultra-wide-angle Transformation Multi-scale GAN
Jul 21, 2023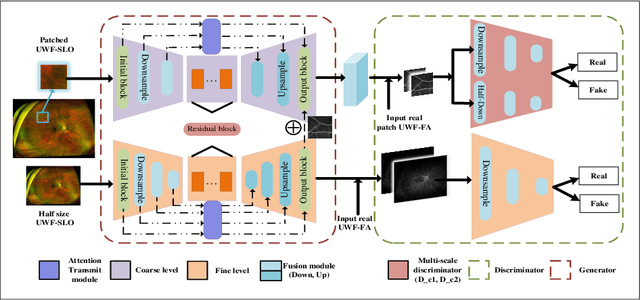



Fundus photography is an essential examination for clinical and differential diagnosis of fundus diseases. Recently, Ultra-Wide-angle Fundus (UWF) techniques, UWF Fluorescein Angiography (UWF-FA) and UWF Scanning Laser Ophthalmoscopy (UWF-SLO) have been gradually put into use. However, Fluorescein Angiography (FA) and UWF-FA require injecting sodium fluorescein which may have detrimental influences. To avoid negative impacts, cross-modality medical image generation algorithms have been proposed. Nevertheless, current methods in fundus imaging could not produce high-resolution images and are unable to capture tiny vascular lesion areas. This paper proposes a novel conditional generative adversarial network (UWAT-GAN) to synthesize UWF-FA from UWF-SLO. Using multi-scale generators and a fusion module patch to better extract global and local information, our model can generate high-resolution images. Moreover, an attention transmit module is proposed to help the decoder learn effectively. Besides, a supervised approach is used to train the network using multiple new weighted losses on different scales of data. Experiments on an in-house UWF image dataset demonstrate the superiority of the UWAT-GAN over the state-of-the-art methods. The source code is available at: https://github.com/Tinysqua/UWAT-GAN.
Analysis of Bag-of-n-grams Representation's Properties Based on Textual Reconstruction
Sep 18, 2018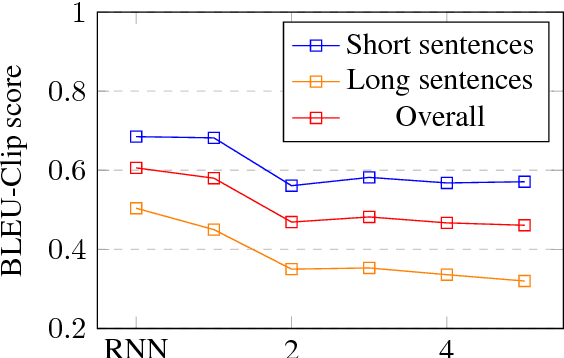
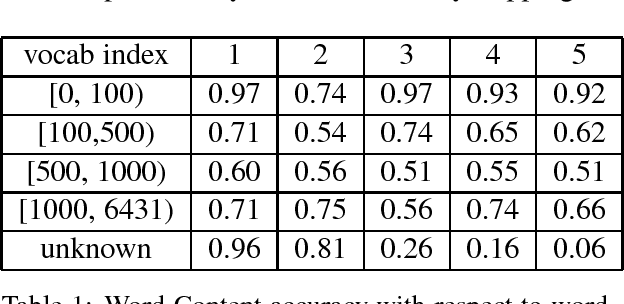
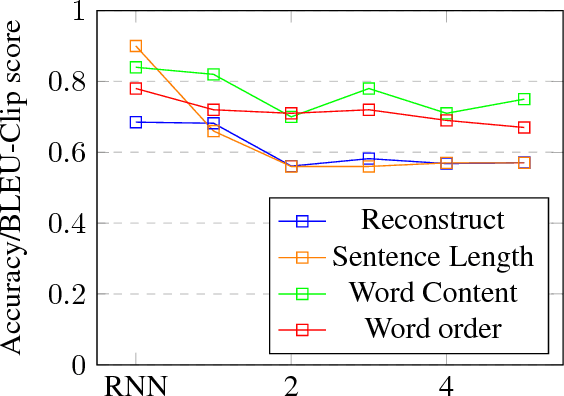
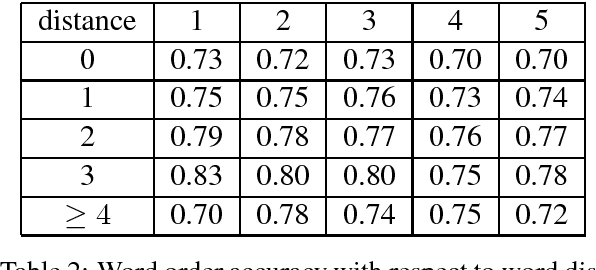
Despite its simplicity, bag-of-n-grams sen- tence representation has been found to excel in some NLP tasks. However, it has not re- ceived much attention in recent years and fur- ther analysis on its properties is necessary. We propose a framework to investigate the amount and type of information captured in a general- purposed bag-of-n-grams sentence represen- tation. We first use sentence reconstruction as a tool to obtain bag-of-n-grams representa- tion that contains general information of the sentence. We then run prediction tasks (sen- tence length, word content, phrase content and word order) using the obtained representation to look into the specific type of information captured in the representation. Our analysis demonstrates that bag-of-n-grams representa- tion does contain sentence structure level in- formation. However, incorporating n-grams with higher order n empirically helps little with encoding more information in general, except for phrase content information.