 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITCFN: Incomplete Triple-Modal Co-Attention Fusion Network for Mild Cognitive Impairment Conversion Prediction
Jan 20, 2025


Alzheimer's disease (AD) is a common neurodegenerative disease among the elderly. Early prediction and timely intervention of its prodromal stage, mild cognitive impairment (MCI), can decrease the risk of advancing to AD. Combining information from various modalities can significantly improve predictive accuracy. However, challenges such as missing data and heterogeneity across modalities complicate multimodal learning methods as adding more modalities can worsen these issues. Current multimodal fusion techniques often fail to adapt to the complexity of medical data, hindering the ability to identify relationships between modalities. To address these challenges, we propose an innovative multimodal approach for predicting MCI conversion, focusing specifically on the issues of missing positron emission tomography (PET) data and integrating diverse medical information. The proposed incomplete triple-modal MCI conversion prediction network is tailored for this purpose. Through the missing modal generation module, we synthesize the missing PET data from the magnetic resonance imaging and extract features using specifically designed encoders. We also develop a channel aggregation module and a triple-modal co-attention fusion module to reduce feature redundancy and achieve effective multimodal data fusion. Furthermore, we design a loss function to handle missing modality issues and align cross-modal features. These components collectively harness multimodal data to boost network performance. Experimental results on the ADNI1 and ADNI2 datasets show that our method significantly surpasses existing unimodal and other multimodal models. Our code is available at https://github.com/justinhxy/ITFC.
Label-efficient Multi-organ Segmentation Method with Diffusion Model
Feb 23, 2024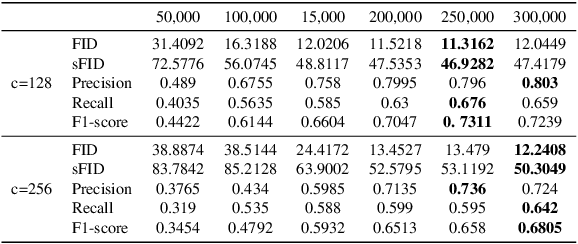
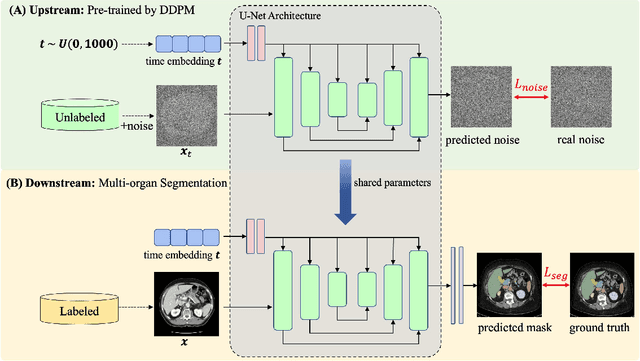

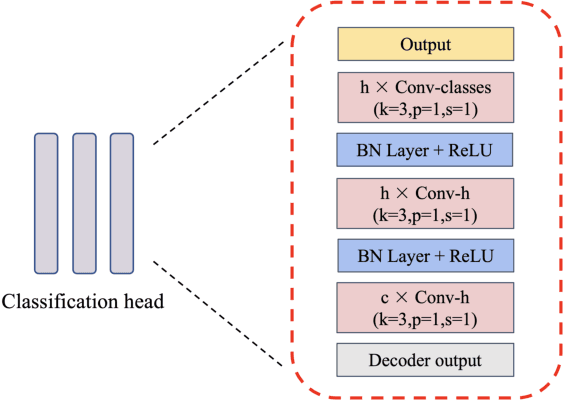
Accurate segmentation of multiple organs in Computed Tomography (CT) images plays a vital role in computer-aided diagnosis systems. Various supervised-learning approaches have been proposed recently. However, these methods heavily depend on a large amount of high-quality labeled data, which is expensive to obtain in practice. In this study, we present a label-efficient learning approach using a pre-trained diffusion model for multi-organ segmentation tasks in CT images. First, a denoising diffusion model was trained using unlabeled CT data, generating additional two-dimensional (2D) CT images. Then the pre-trained denoising diffusion network was transferred to the downstream multi-organ segmentation task, effectively creating a semi-supervised learning model that requires only a small amount of labeled data. Furthermore, linear classification and fine-tuning decoder strategies were employed to enhance the network's segmentation performance. Our generative model at 256x256 resolution achieves impressive performance in terms of Fr\'echet inception distance, spatial Fr\'echet inception distance, and F1-score, with values of 11.32, 46.93, and 73.1\%, respectively. These results affirm the diffusion model's ability to generate diverse and realistic 2D CT images. Additionally, our method achieves competitive multi-organ segmentation performance compared to state-of-the-art methods on the FLARE 2022 dataset, particularly in limited labeled data scenarios. Remarkably, even with only 1\% and 10\% labeled data, our method achieves Dice similarity coefficients (DSCs) of 71.56\% and 78.51\% after fine-tuning, respectively. The method achieves a DSC score of 51.81\% using just four labeled CT scans. These results demonstrate the efficacy of our approach in overcoming the limitations of supervised learning heavily reliant on large-scale labeled data.
A Systematic Review for Transformer-based Long-term Series Forecasting
Oct 31, 2023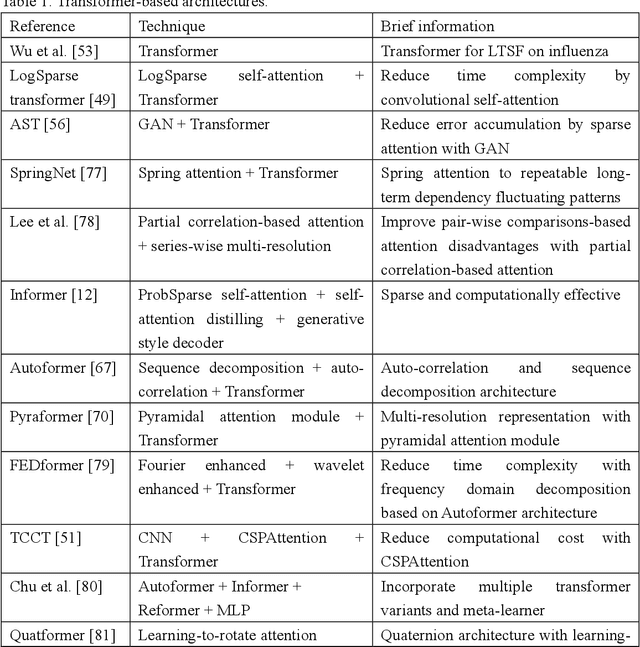
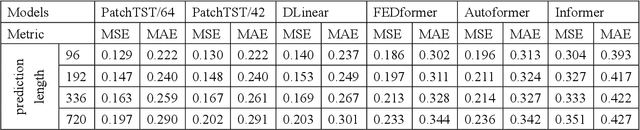

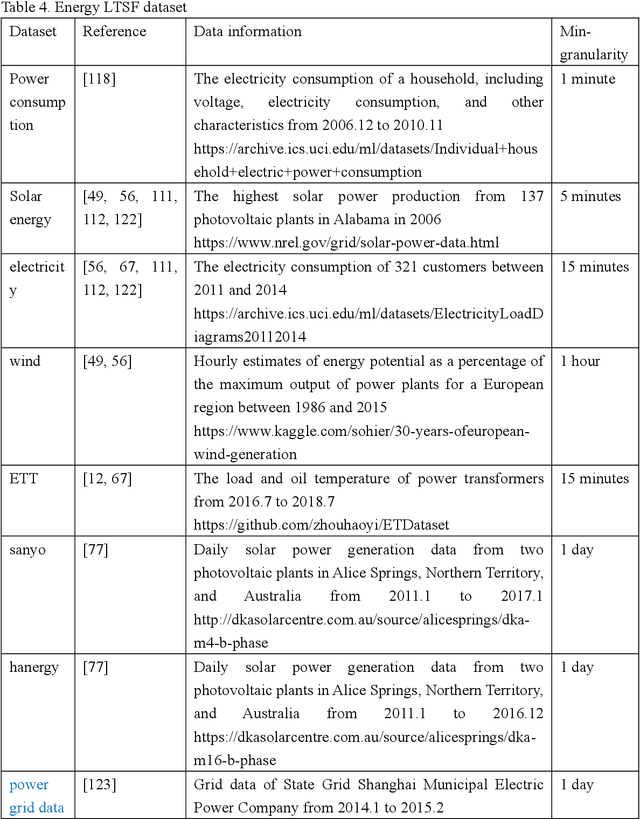
The emergence of deep learning has yielded noteworthy advancements in time series forecasting (TSF). Transformer architectures, in particular, have witnessed broad utilization and adoption in TSF tasks. Transformers have proven to be the most successful solution to extract the semantic correlations among the elements within a long sequence. Various variants have enabled transformer architecture to effectively handle long-term time series forecasting (LTSF) tasks. In this article, we first present a comprehensive overview of transformer architectures and their subsequent enhancements developed to address various LTSF tasks. Then, we summarize the publicly available LTSF datasets and relevant evaluation metrics. Furthermore, we provide valuable insights into the best practices and techniques for effectively training transformers in the context of time-series analysis. Lastly, we propose potential research directions in this rapidly evolving field.