 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbMoE: Differentiable Probabilistic Routing for Mixture-of-Experts
Jun 01, 2026Mixture-of-Experts (MoE) models scale by activating only a small subset of experts per token. However, training such models remains challenging because top-$k$ routing is discrete and non-differentiable, requiring gradient estimators for expert selection whose design remains a central open problem. We introduce ProbMoE, a probabilistic routing framework that models expert selection as a distribution over cardinality-constrained expert subsets and formulates routing as probabilistic inference in this discrete subset space. We first propose ProbMoE Exact-$k$ routing, which samples $k$-expert subsets in the forward pass, and the backward pass uses gradients through each expert's exact marginal probability as a tractable surrogate for the true gradient. ProbMoE naturally generalizes to a dynamic-$k$ routing setting, where both training and inference constrain the routing cardinality to the same predefined range, allowing adaptive expert allocation per token. Across benchmarks and model backbones, ProbMoE Exact-$k$ achieves strong performance compared to competitive baselines, with improved expert utilization and routing diversity; ProbMoE Dynamic-$k$ achieves comparable performance with fewer activated experts.
HIR-ALIGN: Enhancing Hyperspectral Image Restoration via Diffusion-Based Data Generation
May 13, 2026Hyperspectral image (HSI) restoration is crucial for reliable analysis, as real HSIs suffer from degradations like noise, blur, and resolution loss. However, existing models trained on source data often fail on target domains lacking clean references, a common occurrence in practice. To address this issue, we present HIR-ALIGN, a plug-and-play target-adaptive augmentation framework that enhances hyperspectral image restoration by augmenting limited training images with synthetic data that closely matches the target distribution using no extra data. It consists of three stages: (i) proxy generation, where off-the-shelf restoration models restore degraded target observations to produce semantics-preserving proxy HSIs that approximate target-domain clean images; (ii) distribution-adaptive synthesis, where a blur-robust unCLIP diffusion model generates target-aligned RGBs from proxy RGBs, with prompt conditioning and embedding-space noise initialization. Then, a warp-based spectral transfer module synthesizes HSIs by aligning each generated RGB with the proxy RGB, estimating soft patch-wise transport weights, and applying these weights and learnable local interpolation kernels to the proxy HSI; and (iii) aligned supervised finetuning, where restoration networks pretrained on the source distribution are finetuned using both the proxy HSIs and synthesized target-aligned HSIs, and are then deployed on degraded target images. We further provide theoretical analysis showing that augmentation-based finetuning can achieve lower target-domain restoration risk by jointly improving target distribution coverage and controlling spectral bias. Extensive experiments on simulated and real datasets across denoising and super-resolution tasks demonstrate that HIR-ALIGN consistently improves source-only supervised baselines, outperforming both source-only counterparts and representative unsupervised methods.
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
AD-Copilot: A Vision-Language Assistant for Industrial Anomaly Detection via Visual In-context Comparison
Mar 14, 2026Multimodal Large Language Models (MLLMs) have achieved impressive success in natural visual understanding, yet they consistently underperform in industrial anomaly detection (IAD). This is because MLLMs trained mostly on general web data differ significantly from industrial images. Moreover, they encode each image independently and can only compare images in the language space, making them insensitive to subtle visual differences that are key to IAD. To tackle these issues, we present AD-Copilot, an interactive MLLM specialized for IAD via visual in-context comparison. We first design a novel data curation pipeline to mine inspection knowledge from sparsely labeled industrial images and generate precise samples for captioning, VQA, and defect localization, yielding a large-scale multimodal dataset Chat-AD rich in semantic signals for IAD. On this foundation, AD-Copilot incorporates a novel Comparison Encoder that employs cross-attention between paired image features to enhance multi-image fine-grained perception, and is trained with a multi-stage strategy that incorporates domain knowledge and gradually enhances IAD skills. In addition, we introduce MMAD-BBox, an extended benchmark for anomaly localization with bounding-box-based evaluation. The experiments show that AD-Copilot achieves 82.3% accuracy on the MMAD benchmark, outperforming all other models without any data leakage. In the MMAD-BBox test, it achieves a maximum improvement of $3.35\times$ over the baseline. AD-Copilot also exhibits excellent generalization of its performance gains across other specialized and general-purpose benchmarks. Remarkably, AD-Copilot surpasses human expert-level performance on several IAD tasks, demonstrating its potential as a reliable assistant for real-world industrial inspection. All datasets and models will be released for the broader benefit of the community.
Compress, Cross and Scale: Multi-Level Compression Cross Networks for Efficient Scaling in Recommender Systems
Feb 12, 2026Modeling high-order feature interactions efficiently is a central challenge in click-through rate and conversion rate prediction. Modern industrial recommender systems are predominantly built upon deep learning recommendation models, where the interaction backbone plays a critical role in determining both predictive performance and system efficiency. However, existing interaction modules often struggle to simultaneously achieve strong interaction capacity, high computational efficiency, and good scalability, resulting in limited ROI when models are scaled under strict production constraints. In this work, we propose MLCC, a structured feature interaction architecture that organizes feature crosses through hierarchical compression and dynamic composition, which can efficiently capture high-order feature dependencies while maintaining favorable computational complexity. We further introduce MC-MLCC, a Multi-Channel extension that decomposes feature interactions into parallel subspaces, enabling efficient horizontal scaling with improved representation capacity and significantly reduced parameter growth. Extensive experiments on three public benchmarks and a large-scale industrial dataset show that our proposed models consistently outperform strong DLRM-style baselines by up to 0.52 AUC, while reducing model parameters and FLOPs by up to 26$\times$ under comparable performance. Comprehensive scaling analyses demonstrate stable and predictable scaling behavior across embedding dimension, head number, and channel count, with channel-based scaling achieving substantially better efficiency than conventional embedding inflation. Finally, online A/B testing on a real-world advertising platform validates the practical effectiveness of our approach, which has been widely adopted in Bilibili advertising system under strict latency and resource constraints.
Agentic Spatio-Temporal Grounding via Collaborative Reasoning
Feb 10, 2026Spatio-Temporal Video Grounding (STVG) aims to retrieve the spatio-temporal tube of a target object or person in a video given a text query. Most existing approaches perform frame-wise spatial localization within a predicted temporal span, resulting in redundant computation, heavy supervision requirements, and limited generalization. Weakly-supervised variants mitigate annotation costs but remain constrained by the dataset-level train-and-fit paradigm with an inferior performance. To address these challenges, we propose the Agentic Spatio-Temporal Grounder (ASTG) framework for the task of STVG towards an open-world and training-free scenario. Specifically, two specialized agents SRA (Spatial Reasoning Agent) and TRA (Temporal Reasoning Agent) constructed leveraging on modern Multimoal Large Language Models (MLLMs) work collaboratively to retrieve the target tube in an autonomous and self-guided manner. Following a propose-and-evaluation paradigm, ASTG duly decouples spatio-temporal reasoning and automates the tube extraction, verification and temporal localization processes. With a dedicate visual memory and dialogue context, the retrieval efficiency is significantly enhanced. Experiments on popular benchmarks demonstrate the superiority of the proposed approach where it outperforms existing weakly-supervised and zero-shot approaches by a margin and is comparable to some of the fully-supervised methods.
DP-CSGP: Differentially Private Stochastic Gradient Push with Compressed Communication
Dec 15, 2025In this paper, we propose a Differentially Private Stochastic Gradient Push with Compressed communication (termed DP-CSGP) for decentralized learning over directed graphs. Different from existing works, the proposed algorithm is designed to maintain high model utility while ensuring both rigorous differential privacy (DP) guarantees and efficient communication. For general non-convex and smooth objective functions, we show that the proposed algorithm achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}δ \right)}/(\sqrt{n}Jε) \right)$ ($J$ and $d$ are the number of local samples and the dimension of decision variables, respectively) with $\left(ε, δ\right)$-DP guarantee for each node, matching that of decentralized counterparts with exact communication. Extensive experiments on benchmark tasks show that, under the same privacy budget, DP-CSGP achieves comparable model accuracy with significantly lower communication cost than existing decentralized counterparts with exact communication.
Video Set Distillation: Information Diversification and Temporal Densification
Nov 28, 2024



The rapid development of AI models has led to a growing emphasis on enhancing their capabilities for complex input data such as videos. While large-scale video datasets have been introduced to support this growth, the unique challenges of reducing redundancies in video \textbf{sets} have not been explored. Compared to image datasets or individual videos, video \textbf{sets} have a two-layer nested structure, where the outer layer is the collection of individual videos, and the inner layer contains the correlations among frame-level data points to provide temporal information. Video \textbf{sets} have two dimensions of redundancies: within-sample and inter-sample redundancies. Existing methods like key frame selection, dataset pruning or dataset distillation are not addressing the unique challenge of video sets since they aimed at reducing redundancies in only one of the dimensions. In this work, we are the first to study Video Set Distillation, which synthesizes optimized video data by jointly addressing within-sample and inter-sample redundancies. Our Information Diversification and Temporal Densification (IDTD) method jointly reduces redundancies across both dimensions. This is achieved through a Feature Pool and Feature Selectors mechanism to preserve inter-sample diversity, alongside a Temporal Fusor that maintains temporal information density within synthesized videos. Our method achieves state-of-the-art results in Video Dataset Distillation, paving the way for more effective redundancy reduction and efficient AI model training on video datasets.
A Systematic Review for Transformer-based Long-term Series Forecasting
Oct 31, 2023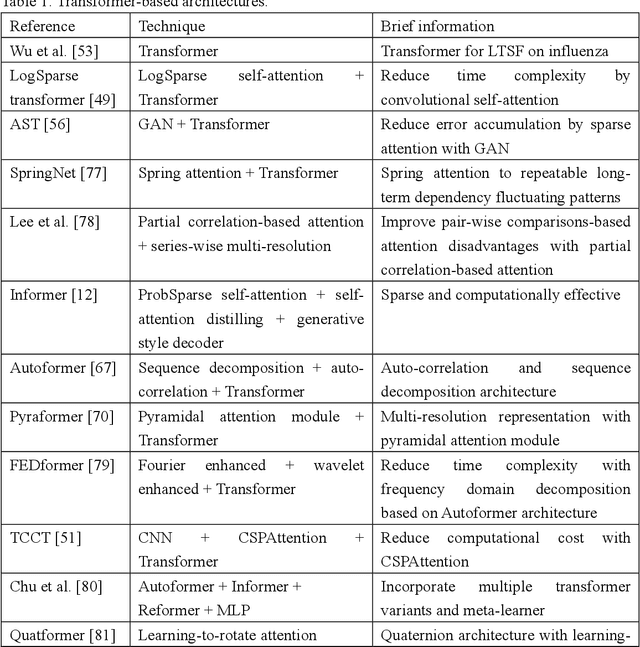
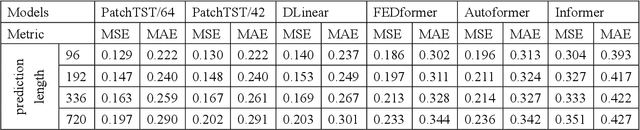

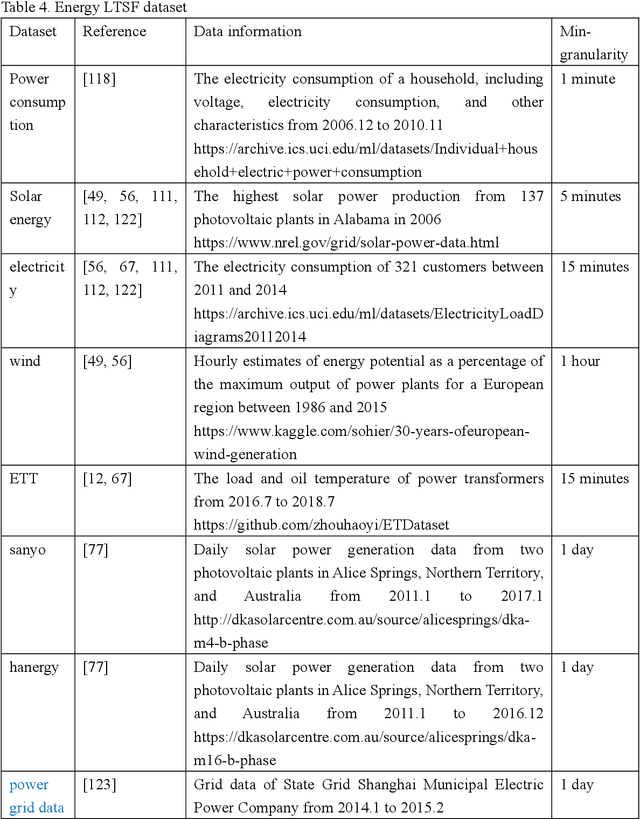
The emergence of deep learning has yielded noteworthy advancements in time series forecasting (TSF). Transformer architectures, in particular, have witnessed broad utilization and adoption in TSF tasks. Transformers have proven to be the most successful solution to extract the semantic correlations among the elements within a long sequence. Various variants have enabled transformer architecture to effectively handle long-term time series forecasting (LTSF) tasks. In this article, we first present a comprehensive overview of transformer architectures and their subsequent enhancements developed to address various LTSF tasks. Then, we summarize the publicly available LTSF datasets and relevant evaluation metrics. Furthermore, we provide valuable insights into the best practices and techniques for effectively training transformers in the context of time-series analysis. Lastly, we propose potential research directions in this rapidly evolving field.
Composite Fixed-Length Ordered Features for Palmprint Template Protection with Diminished Performance Loss
Nov 09, 2022



Palmprint recognition has become more and more popular due to its advantages over other biometric modalities such as fingerprint, in that it is larger in area, richer in information and able to work at a distance. However, the issue of palmprint privacy and security (especially palmprint template protection) remains under-studied. Among the very few research works, most of them only use the directional and orientation features of the palmprint with transformation processing, yielding unsatisfactory protection and identification performance. Thus, this paper proposes a palmprint template protection-oriented operator that has a fixed length and is ordered in nature, by fusing point features and orientation features. Firstly, double orientations are extracted with more accuracy based on MFRAT. Then key points of SURF are extracted and converted to be fixed-length and ordered features. Finally, composite features that fuse up the double orientations and SURF points are transformed using the irreversible transformation of IOM to generate the revocable palmprint template. Experiments show that the EER after irreversible transformation on the PolyU and CASIA databases are 0.17% and 0.19% respectively, and the absolute precision loss is 0.08% and 0.07%, respectively, which proves the advantage of our method.