 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Set Distillation: Information Diversification and Temporal Densification
Nov 28, 2024



The rapid development of AI models has led to a growing emphasis on enhancing their capabilities for complex input data such as videos. While large-scale video datasets have been introduced to support this growth, the unique challenges of reducing redundancies in video \textbf{sets} have not been explored. Compared to image datasets or individual videos, video \textbf{sets} have a two-layer nested structure, where the outer layer is the collection of individual videos, and the inner layer contains the correlations among frame-level data points to provide temporal information. Video \textbf{sets} have two dimensions of redundancies: within-sample and inter-sample redundancies. Existing methods like key frame selection, dataset pruning or dataset distillation are not addressing the unique challenge of video sets since they aimed at reducing redundancies in only one of the dimensions. In this work, we are the first to study Video Set Distillation, which synthesizes optimized video data by jointly addressing within-sample and inter-sample redundancies. Our Information Diversification and Temporal Densification (IDTD) method jointly reduces redundancies across both dimensions. This is achieved through a Feature Pool and Feature Selectors mechanism to preserve inter-sample diversity, alongside a Temporal Fusor that maintains temporal information density within synthesized videos. Our method achieves state-of-the-art results in Video Dataset Distillation, paving the way for more effective redundancy reduction and efficient AI model training on video datasets.
REHRSeg: Unleashing the Power of Self-Supervised Super-Resolution for Resource-Efficient 3D MRI Segmentation
Oct 14, 2024
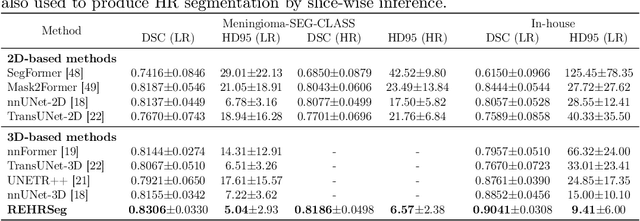
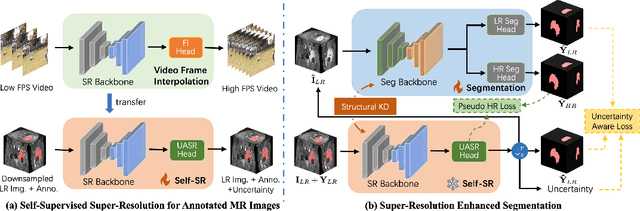
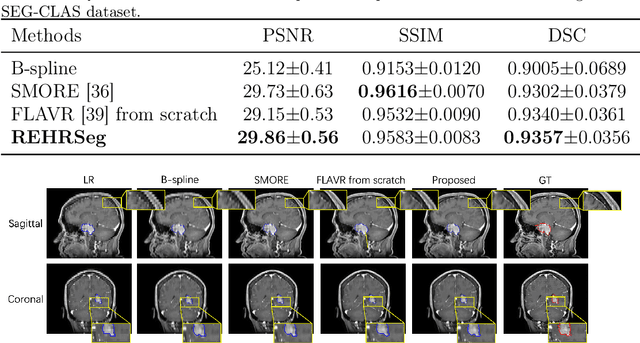
High-resolution (HR) 3D magnetic resonance imaging (MRI) can provide detailed anatomical structural information, enabling precise segmentation of regions of interest for various medical image analysis tasks. Due to the high demands of acquisition device, collection of HR images with their annotations is always impractical in clinical scenarios. Consequently, segmentation results based on low-resolution (LR) images with large slice thickness are often unsatisfactory for subsequent tasks. In this paper, we propose a novel Resource-Efficient High-Resolution Segmentation framework (REHRSeg) to address the above-mentioned challenges in real-world applications, which can achieve HR segmentation while only employing the LR images as input. REHRSeg is designed to leverage self-supervised super-resolution (self-SR) to provide pseudo supervision, therefore the relatively easier-to-acquire LR annotated images generated by 2D scanning protocols can be directly used for model training. The main contribution to ensure the effectiveness in self-SR for enhancing segmentation is three-fold: (1) We mitigate the data scarcity problem in the medical field by using pseudo-data for training the segmentation model. (2) We design an uncertainty-aware super-resolution (UASR) head in self-SR to raise the awareness of segmentation uncertainty as commonly appeared on the ROI boundaries. (3) We align the spatial features for self-SR and segmentation through structural knowledge distillation to enable a better capture of region correlations. Experimental results demonstrate that REHRSeg achieves high-quality HR segmentation without intensive supervision, while also significantly improving the baseline performance for LR segmentation.
Distortion-aware Transformer in 360° Salient Object Detection
Aug 07, 2023With the emergence of VR and AR, 360{\deg} data attracts increasing attention from the computer vision and multimedia communities. Typically, 360{\deg} data is projected into 2D ERP (equirectangular projection) images for feature extraction. However, existing methods cannot handle the distortions that result from the projection, hindering the development of 360-data-based tasks. Therefore, in this paper, we propose a Transformer-based model called DATFormer to address the distortion problem. We tackle this issue from two perspectives. Firstly, we introduce two distortion-adaptive modules. The first is a Distortion Mapping Module, which guides the model to pre-adapt to distorted features globally. The second module is a Distortion-Adaptive Attention Block that reduces local distortions on multi-scale features. Secondly, to exploit the unique characteristics of 360{\deg} data, we present a learnable relation matrix and use it as part of the positional embedding to further improve performance. Extensive experiments are conducted on three public datasets, and the results show that our model outperforms existing 2D SOD (salient object detection) and 360 SOD methods.
Towards Explainable 3D Grounded Visual Question Answering: A New Benchmark and Strong Baseline
Sep 24, 2022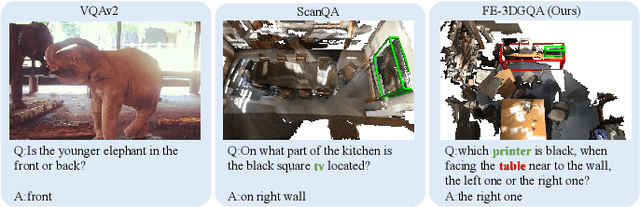
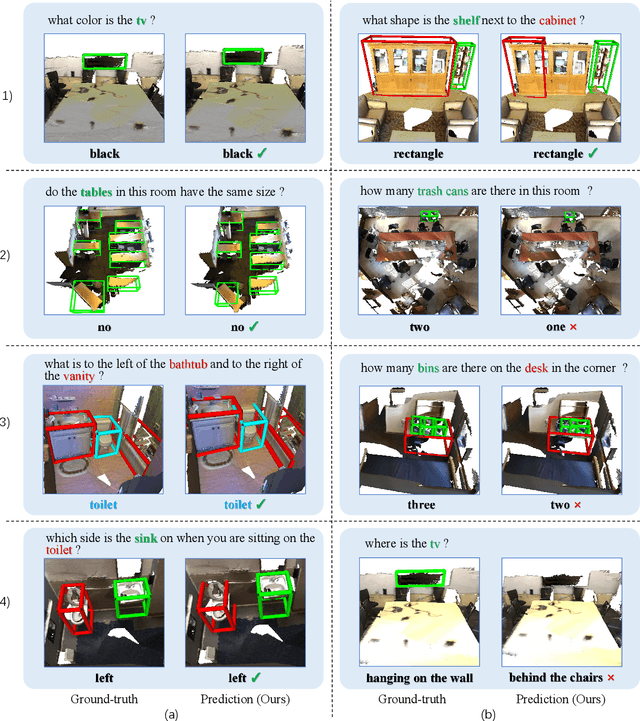
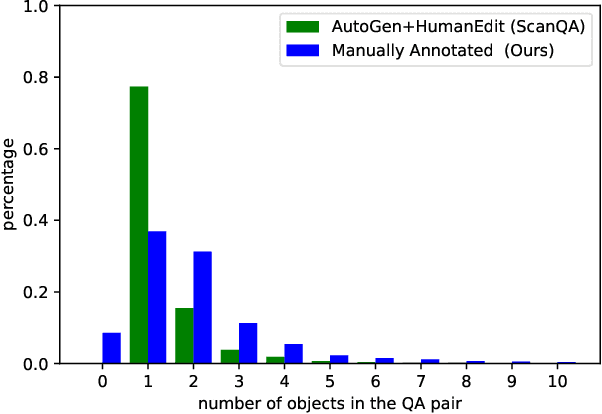

Recently, 3D vision-and-language tasks have attracted increasing research interest. Compared to other vision-and-language tasks, the 3D visual question answering (VQA) task is less exploited and is more susceptible to language priors and co-reference ambiguity. Meanwhile, a couple of recently proposed 3D VQA datasets do not well support 3D VQA task due to their limited scale and annotation methods. In this work, we formally define and address a 3D grounded VQA task by collecting a new 3D VQA dataset, referred to as FE-3DGQA, with diverse and relatively free-form question-answer pairs, as well as dense and completely grounded bounding box annotations. To achieve more explainable answers, we labelled the objects appeared in the complex QA pairs with different semantic types, including answer-grounded objects (both appeared and not appeared in the questions), and contextual objects for answer-grounded objects. We also propose a new 3D VQA framework to effectively predict the completely visually grounded and explainable answer. Extensive experiments verify that our newly collected benchmark datasets can be effectively used to evaluate various 3D VQA methods from different aspects and our newly proposed framework also achieves state-of-the-art performance on the new benchmark dataset. Both the newly collected dataset and our codes will be publicly available at http://github.com/zlccccc/3DGQA.