 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgiATM: A Physics-Guided Plug-and-Play Model for Deep Learning-Based Smoke Removal in Laparoscopic Surgery
Nov 07, 2025During laparoscopic surgery, smoke generated by tissue cauterization can significantly degrade the visual quality of endoscopic frames, increasing the risk of surgical errors and hindering both clinical decision-making and computer-assisted visual analysis. Consequently, removing surgical smoke is critical to ensuring patient safety and maintaining operative efficiency. In this study, we propose the Surgical Atmospheric Model (SurgiATM) for surgical smoke removal. SurgiATM statistically bridges a physics-based atmospheric model and data-driven deep learning models, combining the superior generalizability of the former with the high accuracy of the latter. Furthermore, SurgiATM is designed as a lightweight, plug-and-play module that can be seamlessly integrated into diverse surgical desmoking architectures to enhance their accuracy and stability, better meeting clinical requirements. It introduces only two hyperparameters and no additional trainable weights, preserving the original network architecture with minimal computational and modification overhead. We conduct extensive experiments on three public surgical datasets with ten desmoking methods, involving multiple network architectures and covering diverse procedures, including cholecystectomy, partial nephrectomy, and diaphragm dissection. The results demonstrate that incorporating SurgiATM commonly reduces the restoration errors of existing models and relatively enhances their generalizability, without adding any trainable layers or weights. This highlights the convenience, low cost, effectiveness, and generalizability of the proposed method. The code for SurgiATM is released at https://github.com/MingyuShengSMY/SurgiATM.
$μ$NeuFMT: Optical-Property-Adaptive Fluorescence Molecular Tomography via Implicit Neural Representation
Nov 06, 2025Fluorescence Molecular Tomography (FMT) is a promising technique for non-invasive 3D visualization of fluorescent probes, but its reconstruction remains challenging due to the inherent ill-posedness and reliance on inaccurate or often-unknown tissue optical properties. While deep learning methods have shown promise, their supervised nature limits generalization beyond training data. To address these problems, we propose $\mu$NeuFMT, a self-supervised FMT reconstruction framework that integrates implicit neural-based scene representation with explicit physical modeling of photon propagation. Its key innovation lies in jointly optimize both the fluorescence distribution and the optical properties ($\mu$) during reconstruction, eliminating the need for precise prior knowledge of tissue optics or pre-conditioned training data. We demonstrate that $\mu$NeuFMT robustly recovers accurate fluorophore distributions and optical coefficients even with severely erroneous initial values (0.5$\times$ to 2$\times$ of ground truth). Extensive numerical, phantom, and in vivo validations show that $\mu$NeuFMT outperforms conventional and supervised deep learning approaches across diverse heterogeneous scenarios. Our work establishes a new paradigm for robust and accurate FMT reconstruction, paving the way for more reliable molecular imaging in complex clinically related scenarios, such as fluorescence guided surgery.
REHRSeg: Unleashing the Power of Self-Supervised Super-Resolution for Resource-Efficient 3D MRI Segmentation
Oct 14, 2024
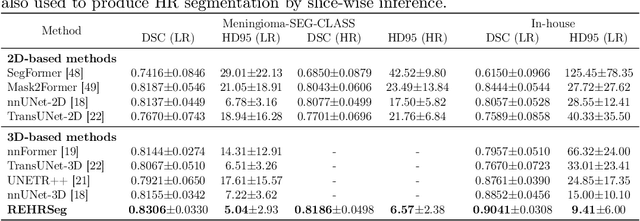
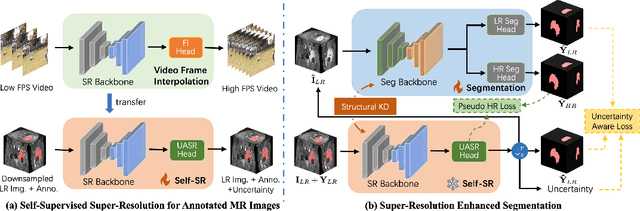
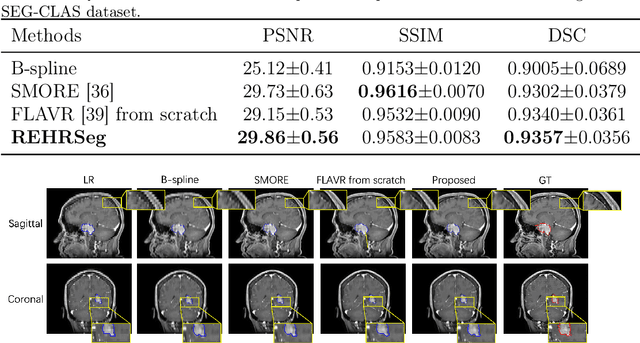
High-resolution (HR) 3D magnetic resonance imaging (MRI) can provide detailed anatomical structural information, enabling precise segmentation of regions of interest for various medical image analysis tasks. Due to the high demands of acquisition device, collection of HR images with their annotations is always impractical in clinical scenarios. Consequently, segmentation results based on low-resolution (LR) images with large slice thickness are often unsatisfactory for subsequent tasks. In this paper, we propose a novel Resource-Efficient High-Resolution Segmentation framework (REHRSeg) to address the above-mentioned challenges in real-world applications, which can achieve HR segmentation while only employing the LR images as input. REHRSeg is designed to leverage self-supervised super-resolution (self-SR) to provide pseudo supervision, therefore the relatively easier-to-acquire LR annotated images generated by 2D scanning protocols can be directly used for model training. The main contribution to ensure the effectiveness in self-SR for enhancing segmentation is three-fold: (1) We mitigate the data scarcity problem in the medical field by using pseudo-data for training the segmentation model. (2) We design an uncertainty-aware super-resolution (UASR) head in self-SR to raise the awareness of segmentation uncertainty as commonly appeared on the ROI boundaries. (3) We align the spatial features for self-SR and segmentation through structural knowledge distillation to enable a better capture of region correlations. Experimental results demonstrate that REHRSeg achieves high-quality HR segmentation without intensive supervision, while also significantly improving the baseline performance for LR segmentation.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024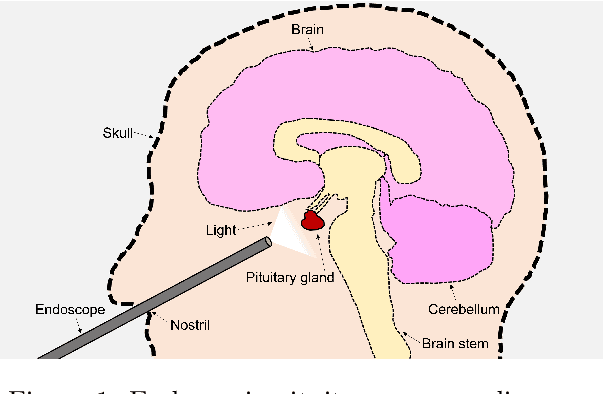

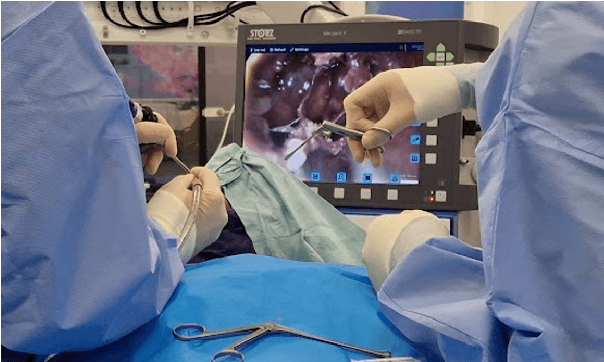
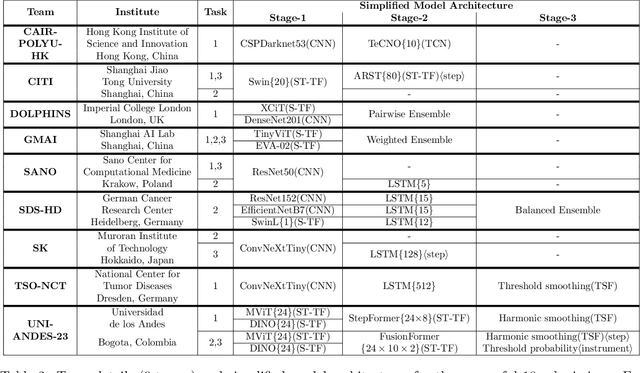
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
C$^3$PS: Context-aware Conditional Cross Pseudo Supervision for Semi-supervised Medical Image Segmentation
Jun 14, 2023



Semi-supervised learning (SSL) methods, which can leverage a large amount of unlabeled data for improved performance, has attracted increasing attention recently. In this paper, we introduce a novel Context-aware Conditional Cross Pseudo Supervision method (referred as C$^3$PS) for semi-supervised medical image segmentation. Unlike previously published Cross Pseudo Supervision (CPS) works, this paper introduces a novel Conditional Cross Pseudo Supervision (CCPS) mechanism where the cross pseudo supervision is conditioned on a given class label. Context-awareness is further introduced in the CCPS to improve the quality of pseudo-labels for cross pseudo supervision. The proposed method has the additional advantage that in the later training stage, it can focus on the learning of hard organs. Validated on two typical yet challenging medical image segmentation tasks, our method demonstrates superior performance over the state-of-the-art methods.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023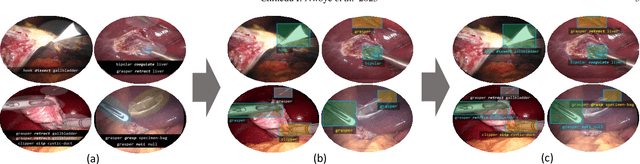
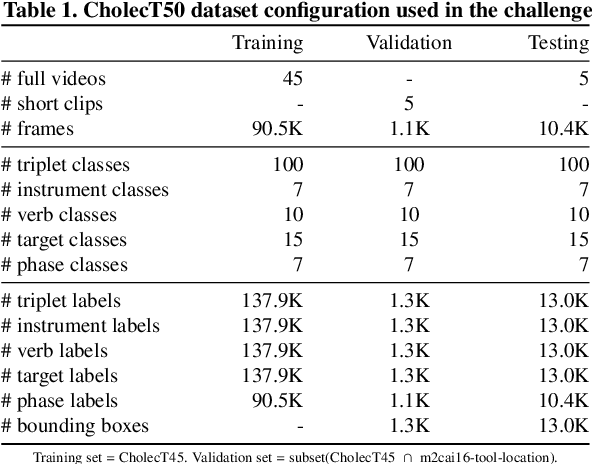
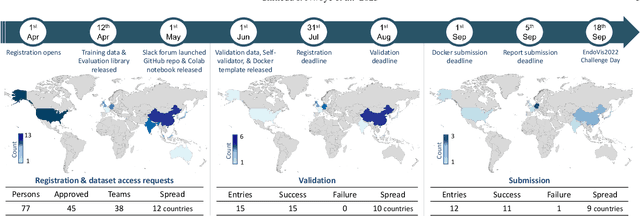
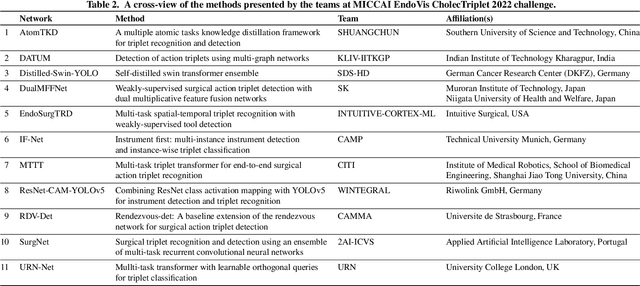
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
ARST: Auto-Regressive Surgical Transformer for Phase Recognition from Laparoscopic Videos
Sep 02, 2022


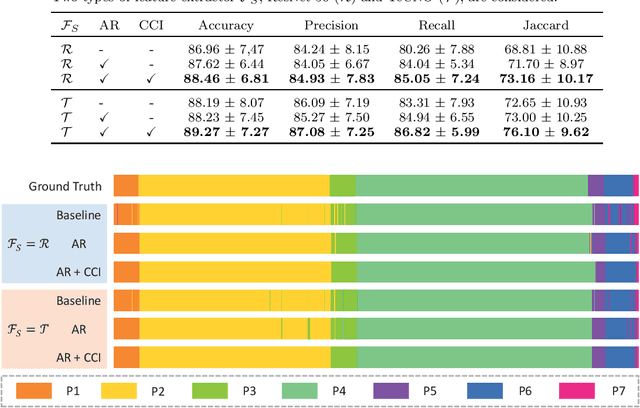
Phase recognition plays an essential role for surgical workflow analysis in computer assisted intervention. Transformer, originally proposed for sequential data modeling in natural language processing, has been successfully applied to surgical phase recognition. Existing works based on transformer mainly focus on modeling attention dependency, without introducing auto-regression. In this work, an Auto-Regressive Surgical Transformer, referred as ARST, is first proposed for on-line surgical phase recognition from laparoscopic videos, modeling the inter-phase correlation implicitly by conditional probability distribution. To reduce inference bias and to enhance phase consistency, we further develop a consistency constraint inference strategy based on auto-regression. We conduct comprehensive validations on a well-known public dataset Cholec80. Experimental results show that our method outperforms the state-of-the-art methods both quantitatively and qualitatively, and achieves an inference rate of 66 frames per second (fps).
KiPA22 Report: U-Net with Contour Regularization for Renal Structures Segmentation
Aug 10, 2022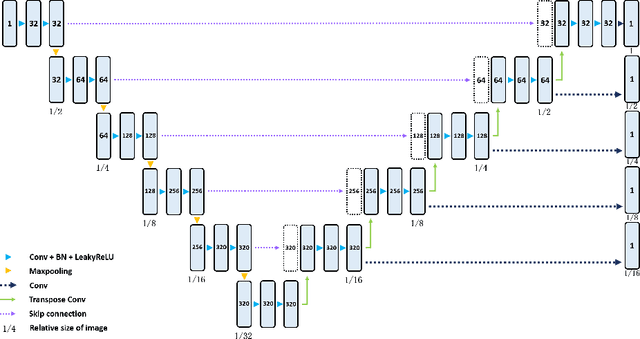
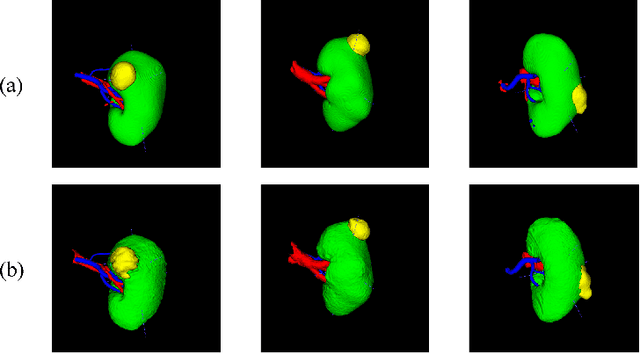

Three-dimensional (3D) integrated renal structures (IRS) segmentation is important in clinical practice. With the advancement of deep learning techniques, many powerful frameworks focusing on medical image segmentation are proposed. In this challenge, we utilized the nnU-Net framework, which is the state-of-the-art method for medical image segmentation. To reduce the outlier prediction for the tumor label, we combine contour regularization (CR) loss of the tumor label with Dice loss and cross-entropy loss to improve this phenomenon.
Calibrating Label Distribution for Class-Imbalanced Barely-Supervised Knee Segmentation
May 07, 2022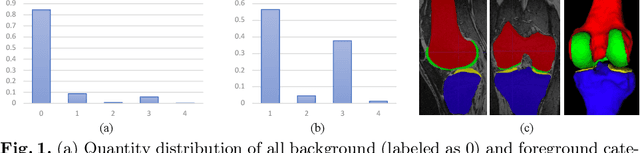
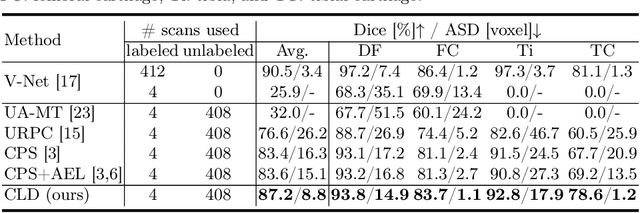
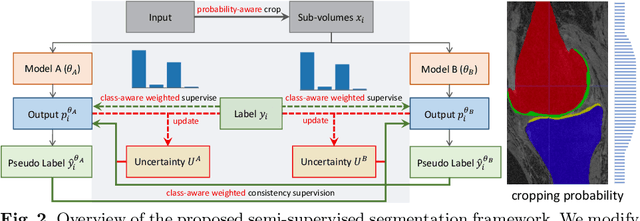
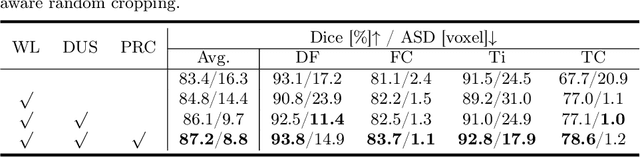
Segmentation of 3D knee MR images is important for the assessment of osteoarthritis. Like other medical data, the volume-wise labeling of knee MR images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL), particularly barely-supervised learning, is highly desirable for training with insufficient labeled data. We observed that the class imbalance problem is severe in the knee MR images as the cartilages only occupy 6% of foreground volumes, and the situation becomes worse without sufficient labeled data. To address the above problem, we present a novel framework for barely-supervised knee segmentation with noisy and imbalanced labels. Our framework leverages label distribution to encourage the network to put more effort into learning cartilage parts. Specifically, we utilize 1.) label quantity distribution for modifying the objective loss function to a class-aware weighted form and 2.) label position distribution for constructing a cropping probability mask to crop more sub-volumes in cartilage areas from both labeled and unlabeled inputs. In addition, we design dual uncertainty-aware sampling supervision to enhance the supervision of low-confident categories for efficient unsupervised learning. Experiments show that our proposed framework brings significant improvements by incorporating the unlabeled data and alleviating the problem of class imbalance. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting.