 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models in Medical Imaging -- A Review and Outlook
Jun 10, 2025Foundation models (FMs) are changing the way medical images are analyzed by learning from large collections of unlabeled data. Instead of relying on manually annotated examples, FMs are pre-trained to learn general-purpose visual features that can later be adapted to specific clinical tasks with little additional supervision. In this review, we examine how FMs are being developed and applied in pathology, radiology, and ophthalmology, drawing on evidence from over 150 studies. We explain the core components of FM pipelines, including model architectures, self-supervised learning methods, and strategies for downstream adaptation. We also review how FMs are being used in each imaging domain and compare design choices across applications. Finally, we discuss key challenges and open questions to guide future research.
Order-preserving Consistency Regularization for Domain Adaptation and Generalization
Sep 23, 2023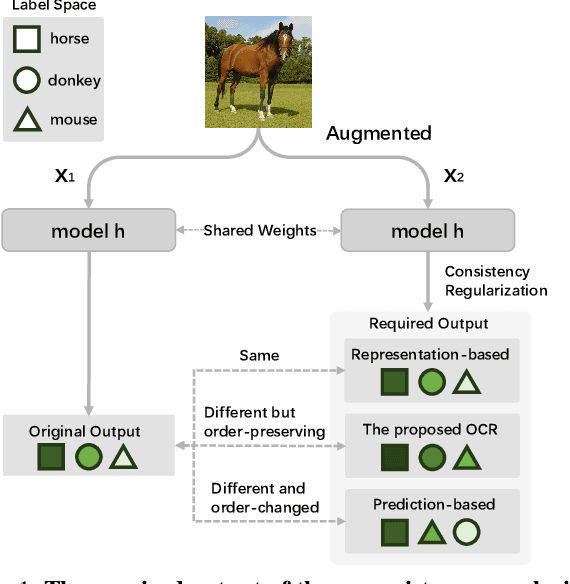

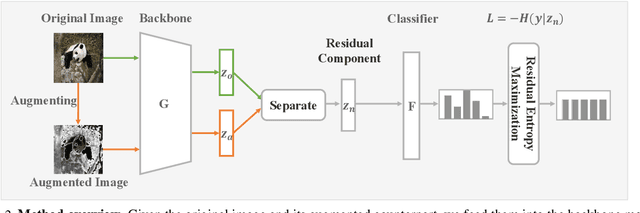

Deep learning models fail on cross-domain challenges if the model is oversensitive to domain-specific attributes, e.g., lightning, background, camera angle, etc. To alleviate this problem, data augmentation coupled with consistency regularization are commonly adopted to make the model less sensitive to domain-specific attributes. Consistency regularization enforces the model to output the same representation or prediction for two views of one image. These constraints, however, are either too strict or not order-preserving for the classification probabilities. In this work, we propose the Order-preserving Consistency Regularization (OCR) for cross-domain tasks. The order-preserving property for the prediction makes the model robust to task-irrelevant transformations. As a result, the model becomes less sensitive to the domain-specific attributes. The comprehensive experiments show that our method achieves clear advantages on five different cross-domain tasks.
ProtoDiff: Learning to Learn Prototypical Networks by Task-Guided Diffusion
Jun 26, 2023



Prototype-based meta-learning has emerged as a powerful technique for addressing few-shot learning challenges. However, estimating a deterministic prototype using a simple average function from a limited number of examples remains a fragile process. To overcome this limitation, we introduce ProtoDiff, a novel framework that leverages a task-guided diffusion model during the meta-training phase to gradually generate prototypes, thereby providing efficient class representations. Specifically, a set of prototypes is optimized to achieve per-task prototype overfitting, enabling accurately obtaining the overfitted prototypes for individual tasks. Furthermore, we introduce a task-guided diffusion process within the prototype space, enabling the meta-learning of a generative process that transitions from a vanilla prototype to an overfitted prototype. ProtoDiff gradually generates task-specific prototypes from random noise during the meta-test stage, conditioned on the limited samples available for the new task. Furthermore, to expedite training and enhance ProtoDiff's performance, we propose the utilization of residual prototype learning, which leverages the sparsity of the residual prototype. We conduct thorough ablation studies to demonstrate its ability to accurately capture the underlying prototype distribution and enhance generalization. The new state-of-the-art performance on within-domain, cross-domain, and few-task few-shot classification further substantiates the benefit of ProtoDiff.
Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization
Mar 20, 2023
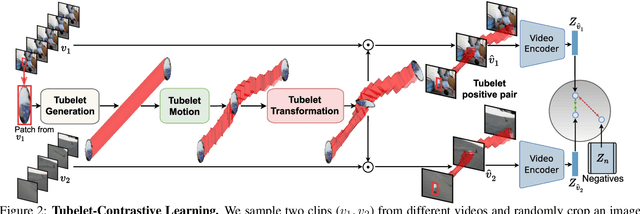
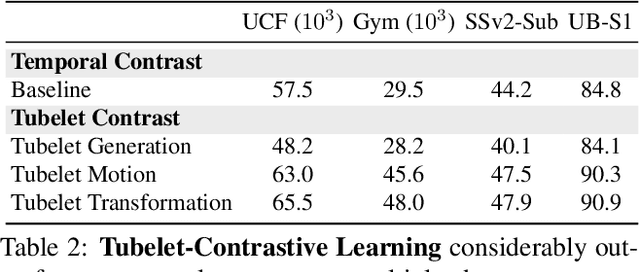
We propose a self-supervised method for learning motion-focused video representations. Existing approaches minimize distances between temporally augmented videos, which maintain high spatial similarity. We instead propose to learn similarities between videos with identical local motion dynamics but an otherwise different appearance. We do so by adding synthetic motion trajectories to videos which we refer to as tubelets. By simulating different tubelet motions and applying transformations, such as scaling and rotation, we introduce motion patterns beyond what is present in the pretraining data. This allows us to learn a video representation that is remarkably data-efficient: our approach maintains performance when using only 25% of the pretraining videos. Experiments on 10 diverse downstream settings demonstrate our competitive performance and generalizability to new domains and fine-grained actions.
How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?
Mar 27, 2022
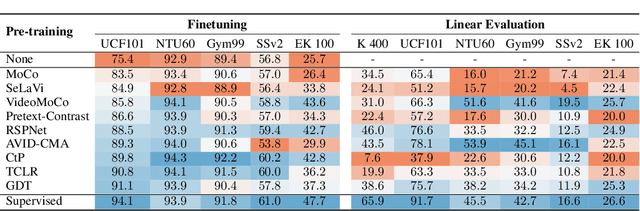
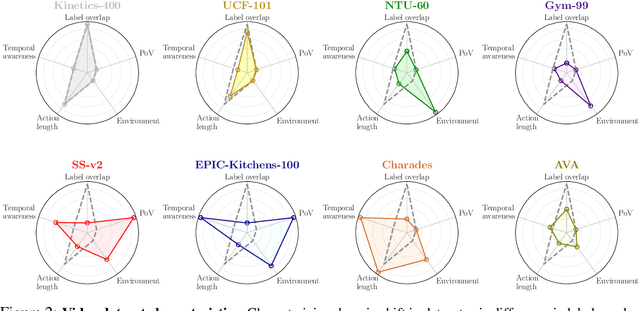
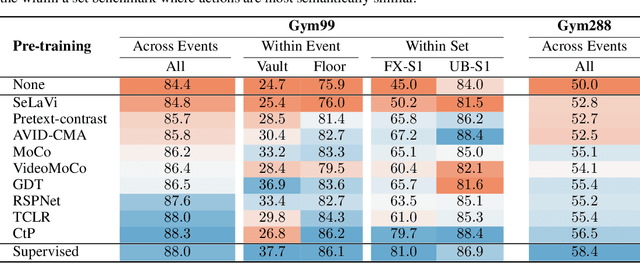
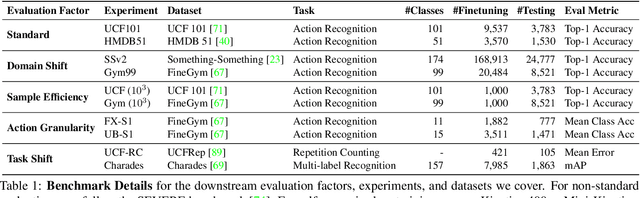
Despite the recent success of video self-supervised learning, there is much still to be understood about their generalization capability. In this paper, we investigate how sensitive video self-supervised learning is to the currently used benchmark convention and whether methods generalize beyond the canonical evaluation setting. We do this across four different factors of sensitivity: domain, samples, actions and task. Our comprehensive set of over 500 experiments, which encompasses 7 video datasets, 9 self-supervised methods and 6 video understanding tasks, reveals that current benchmarks in video self-supervised learning are not a good indicator of generalization along these sensitivity factors. Further, we find that self-supervised methods considerably lag behind vanilla supervised pre-training, especially when domain shift is large and the amount of available downstream samples are low. From our analysis we distill the SEVERE-benchmark, a subset of our experiments, and discuss its implication for evaluating the generalizability of representations obtained by existing and future self-supervised video learning methods.
Frequency-Supervised MR-to-CT Image Synthesis
Jul 19, 2021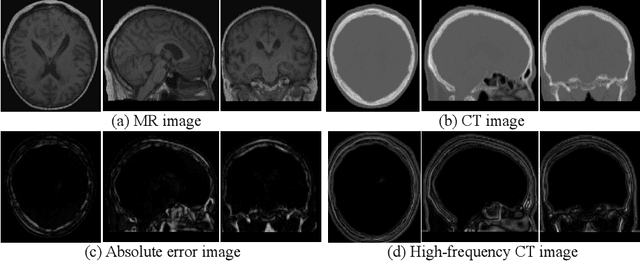

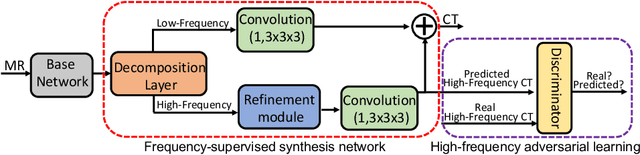

This paper strives to generate a synthetic computed tomography (CT) image from a magnetic resonance (MR) image. The synthetic CT image is valuable for radiotherapy planning when only an MR image is available. Recent approaches have made large strides in solving this challenging synthesis problem with convolutional neural networks that learn a mapping from MR inputs to CT outputs. In this paper, we find that all existing approaches share a common limitation: reconstruction breaks down in and around the high-frequency parts of CT images. To address this common limitation, we introduce frequency-supervised deep networks to explicitly enhance high-frequency MR-to-CT image reconstruction. We propose a frequency decomposition layer that learns to decompose predicted CT outputs into low- and high-frequency components, and we introduce a refinement module to improve high-frequency reconstruction through high-frequency adversarial learning. Experimental results on a new dataset with 45 pairs of 3D MR-CT brain images show the effectiveness and potential of the proposed approach. Code is available at \url{https://github.com/shizenglin/Frequency-Supervised-MR-to-CT-Image-Synthesis}.
Learning to Learn Kernels with Variational Random Features
Jun 11, 2020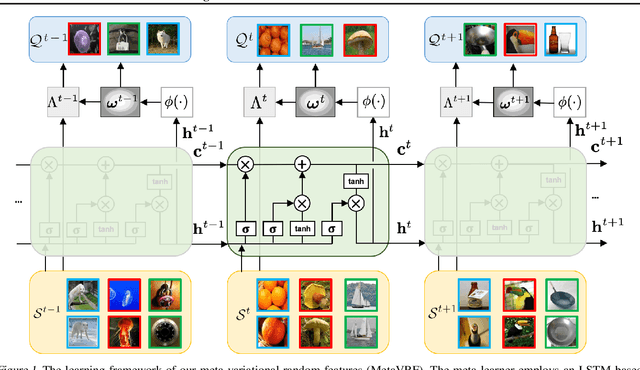


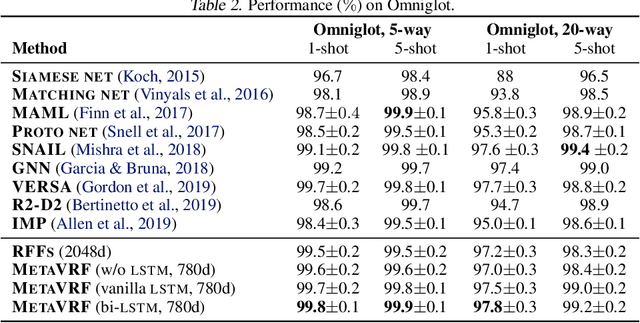
In this work, we introduce kernels with random Fourier features in the meta-learning framework to leverage their strong few-shot learning ability. We propose meta variational random features (MetaVRF) to learn adaptive kernels for the base-learner, which is developed in a latent variable model by treating the random feature basis as the latent variable. We formulate the optimization of MetaVRF as a variational inference problem by deriving an evidence lower bound under the meta-learning framework. To incorporate shared knowledge from related tasks, we propose a context inference of the posterior, which is established by an LSTM architecture. The LSTM-based inference network can effectively integrate the context information of previous tasks with task-specific information, generating informative and adaptive features. The learned MetaVRF can produce kernels of high representational power with a relatively low spectral sampling rate and also enables fast adaptation to new tasks. Experimental results on a variety of few-shot regression and classification tasks demonstrate that MetaVRF delivers much better, or at least competitive, performance compared to existing meta-learning alternatives.
The ActivityNet Large-Scale Activity Recognition Challenge 2018 Summary
Aug 23, 2018



The 3rd annual installment of the ActivityNet Large- Scale Activity Recognition Challenge, held as a full-day workshop in CVPR 2018, focused on the recognition of daily life, high-level, goal-oriented activities from user-generated videos as those found in internet video portals. The 2018 challenge hosted six diverse tasks which aimed to push the limits of semantic visual understanding of videos as well as bridge visual content with human captions. Three out of the six tasks were based on the ActivityNet dataset, which was introduced in CVPR 2015 and organized hierarchically in a semantic taxonomy. These tasks focused on tracing evidence of activities in time in the form of proposals, class labels, and captions. In this installment of the challenge, we hosted three guest tasks to enrich the understanding of visual information in videos. The guest tasks focused on complementary aspects of the activity recognition problem at large scale and involved three challenging and recently compiled datasets: the Kinetics-600 dataset from Google DeepMind, the AVA dataset from Berkeley and Google, and the Moments in Time dataset from MIT and IBM Research.
Guess Where? Actor-Supervision for Spatiotemporal Action Localization
Apr 05, 2018
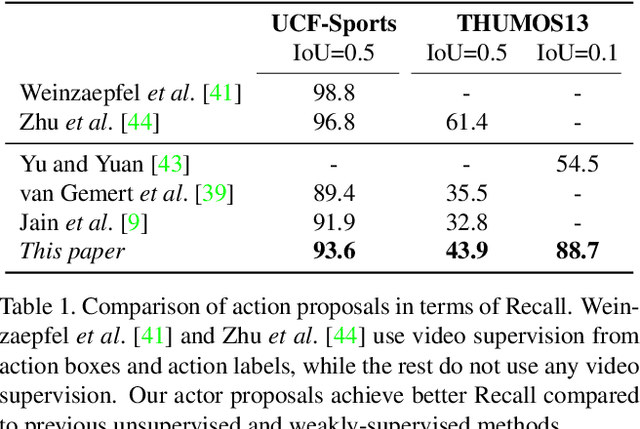
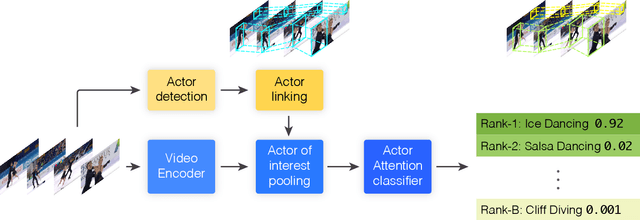

This paper addresses the problem of spatiotemporal localization of actions in videos. Compared to leading approaches, which all learn to localize based on carefully annotated boxes on training video frames, we adhere to a weakly-supervised solution that only requires a video class label. We introduce an actor-supervised architecture that exploits the inherent compositionality of actions in terms of actor transformations, to localize actions. We make two contributions. First, we propose actor proposals derived from a detector for human and non-human actors intended for images, which is linked over time by Siamese similarity matching to account for actor deformations. Second, we propose an actor-based attention mechanism that enables the localization of the actions from action class labels and actor proposals and is end-to-end trainable. Experiments on three human and non-human action datasets show actor supervision is state-of-the-art for weakly-supervised action localization and is even competitive to some fully-supervised alternatives.
ActivityNet Challenge 2017 Summary
Oct 22, 2017



The ActivityNet Large Scale Activity Recognition Challenge 2017 Summary: results and challenge participants papers.