 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionReasoner: Region-Grounded Multi-Round Visual Reasoning
Feb 03, 2026Large vision-language models have achieved remarkable progress in visual reasoning, yet most existing systems rely on single-step or text-only reasoning, limiting their ability to iteratively refine understanding across multiple visual contexts. To address this limitation, we introduce a new multi-round visual reasoning benchmark with training and test sets spanning both detection and segmentation tasks, enabling systematic evaluation under iterative reasoning scenarios. We further propose RegionReasoner, a reinforcement learning framework that enforces grounded reasoning by requiring each reasoning trace to explicitly cite the corresponding reference bounding boxes, while maintaining semantic coherence via a global-local consistency reward. This reward extracts key objects and nouns from both global scene captions and region-level captions, aligning them with the reasoning trace to ensure consistency across reasoning steps. RegionReasoner is optimized with structured rewards combining grounding fidelity and global-local semantic alignment. Experiments on detection and segmentation tasks show that RegionReasoner-7B, together with our newly introduced benchmark RegionDial-Bench, considerably improves multi-round reasoning accuracy, spatial grounding precision, and global-local consistency, establishing a strong baseline for this emerging research direction.
MetaTPT: Meta Test-time Prompt Tuning for Vision-Language Models
Dec 13, 2025Vision-language models (VLMs) such as CLIP exhibit strong zero-shot generalization but remain sensitive to domain shifts at test time. Test-time prompt tuning (TPT) mitigates this issue by adapting prompts with fixed augmentations, which may falter in more challenging settings. In this work, we propose Meta Test-Time Prompt Tuning (MetaTPT), a meta-learning framework that learns a self-supervised auxiliary task to guide test-time prompt tuning. The auxiliary task dynamically learns parameterized augmentations for each sample, enabling more expressive transformations that capture essential features in target domains. MetaTPT adopts a dual-loop optimization paradigm: an inner loop learns a self-supervised task that generates informative views, while the outer loop performs prompt tuning by enforcing consistency across these views. By coupling augmentation learning with prompt tuning, MetaTPT improves test-time adaptation under domain shifts. Extensive experiments demonstrate that MetaTPT achieves state-of-the-art performance on domain generalization and cross-dataset benchmarks.
QUOTA: Quantifying Objects with Text-to-Image Models for Any Domain
Nov 29, 2024



We tackle the problem of quantifying the number of objects by a generative text-to-image model. Rather than retraining such a model for each new image domain of interest, which leads to high computational costs and limited scalability, we are the first to consider this problem from a domain-agnostic perspective. We propose QUOTA, an optimization framework for text-to-image models that enables effective object quantification across unseen domains without retraining. It leverages a dual-loop meta-learning strategy to optimize a domain-invariant prompt. Further, by integrating prompt learning with learnable counting and domain tokens, our method captures stylistic variations and maintains accuracy, even for object classes not encountered during training. For evaluation, we adopt a new benchmark specifically designed for object quantification in domain generalization, enabling rigorous assessment of object quantification accuracy and adaptability across unseen domains in text-to-image generation. Extensive experiments demonstrate that QUOTA outperforms conventional models in both object quantification accuracy and semantic consistency, setting a new benchmark for efficient and scalable text-to-image generation for any domain.
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Nov 07, 2024



In this work, we address the cooperation problem among large language model (LLM) based embodied agents, where agents must cooperate to achieve a common goal. Previous methods often execute actions extemporaneously and incoherently, without long-term strategic and cooperative planning, leading to redundant steps, failures, and even serious repercussions in complex tasks like search-and-rescue missions where discussion and cooperative plan are crucial. To solve this issue, we propose Cooperative Plan Optimization (CaPo) to enhance the cooperation efficiency of LLM-based embodied agents. Inspired by human cooperation schemes, CaPo improves cooperation efficiency with two phases: 1) meta-plan generation, and 2) progress-adaptive meta-plan and execution. In the first phase, all agents analyze the task, discuss, and cooperatively create a meta-plan that decomposes the task into subtasks with detailed steps, ensuring a long-term strategic and coherent plan for efficient coordination. In the second phase, agents execute tasks according to the meta-plan and dynamically adjust it based on their latest progress (e.g., discovering a target object) through multi-turn discussions. This progress-based adaptation eliminates redundant actions, improving the overall cooperation efficiency of agents. Experimental results on the ThreeDworld Multi-Agent Transport and Communicative Watch-And-Help tasks demonstrate that CaPo achieves much higher task completion rate and efficiency compared with state-of-the-arts.
Prompt Diffusion Robustifies Any-Modality Prompt Learning
Oct 26, 2024



Foundation models enable prompt-based classifiers for zero-shot and few-shot learning. Nonetheless, the conventional method of employing fixed prompts suffers from distributional shifts that negatively impact generalizability to unseen samples. This paper introduces prompt diffusion, which uses a diffusion model to gradually refine the prompts to obtain a customized prompt for each sample. Specifically, we first optimize a collection of prompts to obtain over-fitted prompts per sample. Then, we propose a prompt diffusion model within the prompt space, enabling the training of a generative transition process from a random prompt to its overfitted prompt. As we cannot access the label of a test image during inference, our model gradually generates customized prompts solely from random prompts using our trained, prompt diffusion. Our prompt diffusion is generic, flexible, and modality-agnostic, making it a simple plug-and-play module seamlessly embedded into existing prompt learning methods for textual, visual, or multi-modal prompt learning. Our diffusion model uses a fast ODE-based sampling strategy to optimize test sample prompts in just five steps, offering a good trade-off between performance improvement and computational efficiency. For all prompt learning methods tested, adding prompt diffusion yields more robust results for base-to-new generalization, cross-dataset generalization, and domain generalization in classification tasks tested over 15 diverse datasets.
IPO: Interpretable Prompt Optimization for Vision-Language Models
Oct 20, 2024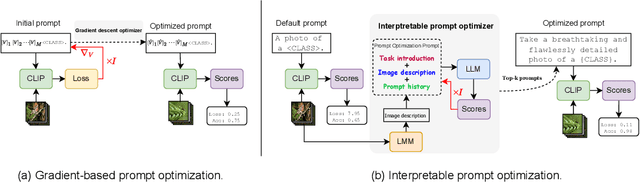
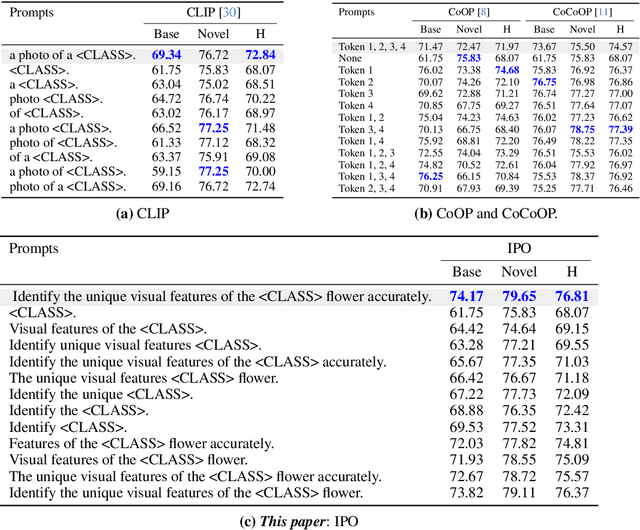
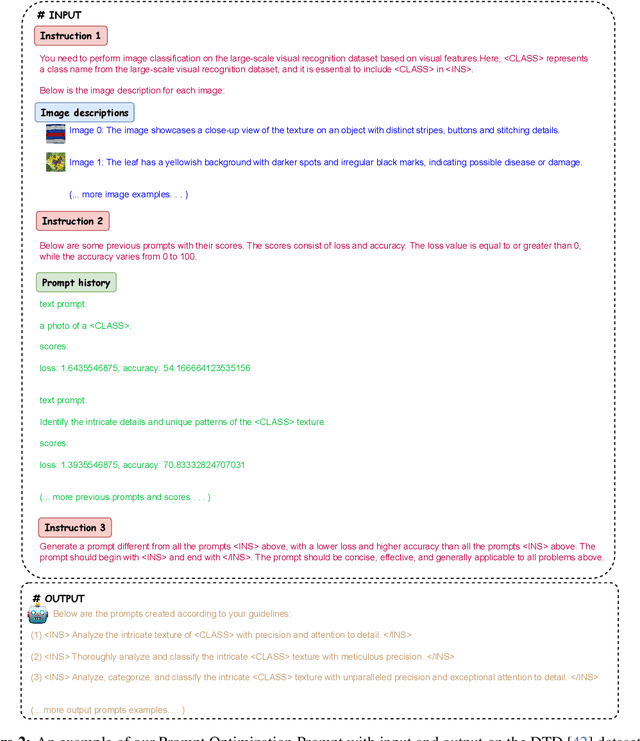

Pre-trained vision-language models like CLIP have remarkably adapted to various downstream tasks. Nonetheless, their performance heavily depends on the specificity of the input text prompts, which requires skillful prompt template engineering. Instead, current approaches to prompt optimization learn the prompts through gradient descent, where the prompts are treated as adjustable parameters. However, these methods tend to lead to overfitting of the base classes seen during training and produce prompts that are no longer understandable by humans. This paper introduces a simple but interpretable prompt optimizer (IPO), that utilizes large language models (LLMs) to generate textual prompts dynamically. We introduce a Prompt Optimization Prompt that not only guides LLMs in creating effective prompts but also stores past prompts with their performance metrics, providing rich in-context information. Additionally, we incorporate a large multimodal model (LMM) to condition on visual content by generating image descriptions, which enhance the interaction between textual and visual modalities. This allows for thae creation of dataset-specific prompts that improve generalization performance, while maintaining human comprehension. Extensive testing across 11 datasets reveals that IPO not only improves the accuracy of existing gradient-descent-based prompt learning methods but also considerably enhances the interpretability of the generated prompts. By leveraging the strengths of LLMs, our approach ensures that the prompts remain human-understandable, thereby facilitating better transparency and oversight for vision-language models.
Training-Free Semantic Segmentation via LLM-Supervision
Mar 31, 2024



Recent advancements in open vocabulary models, like CLIP, have notably advanced zero-shot classification and segmentation by utilizing natural language for class-specific embeddings. However, most research has focused on improving model accuracy through prompt engineering, prompt learning, or fine-tuning with limited labeled data, thereby overlooking the importance of refining the class descriptors. This paper introduces a new approach to text-supervised semantic segmentation using supervision by a large language model (LLM) that does not require extra training. Our method starts from an LLM, like GPT-3, to generate a detailed set of subclasses for more accurate class representation. We then employ an advanced text-supervised semantic segmentation model to apply the generated subclasses as target labels, resulting in diverse segmentation results tailored to each subclass's unique characteristics. Additionally, we propose an assembly that merges the segmentation maps from the various subclass descriptors to ensure a more comprehensive representation of the different aspects in the test images. Through comprehensive experiments on three standard benchmarks, our method outperforms traditional text-supervised semantic segmentation methods by a marked margin.
EMO: Episodic Memory Optimization for Few-Shot Meta-Learning
Jun 26, 2023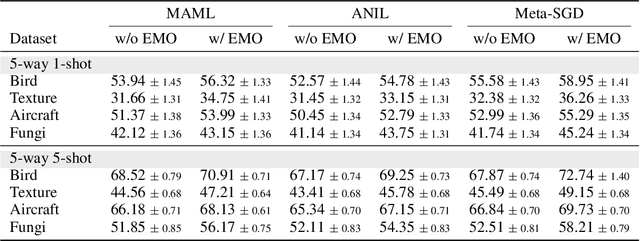
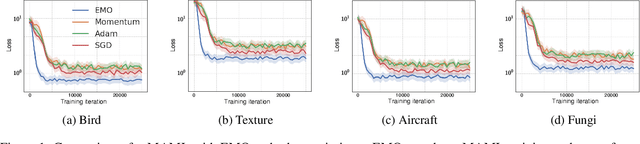
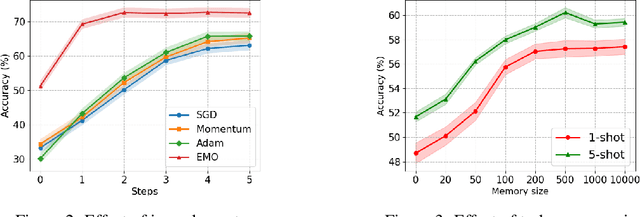

Few-shot meta-learning presents a challenge for gradient descent optimization due to the limited number of training samples per task. To address this issue, we propose an episodic memory optimization for meta-learning, we call EMO, which is inspired by the human ability to recall past learning experiences from the brain's memory. EMO retains the gradient history of past experienced tasks in external memory, enabling few-shot learning in a memory-augmented way. By learning to retain and recall the learning process of past training tasks, EMO nudges parameter updates in the right direction, even when the gradients provided by a limited number of examples are uninformative. We prove theoretically that our algorithm converges for smooth, strongly convex objectives. EMO is generic, flexible, and model-agnostic, making it a simple plug-and-play optimizer that can be seamlessly embedded into existing optimization-based few-shot meta-learning approaches. Empirical results show that EMO scales well with most few-shot classification benchmarks and improves the performance of optimization-based meta-learning methods, resulting in accelerated convergence.
ProtoDiff: Learning to Learn Prototypical Networks by Task-Guided Diffusion
Jun 26, 2023



Prototype-based meta-learning has emerged as a powerful technique for addressing few-shot learning challenges. However, estimating a deterministic prototype using a simple average function from a limited number of examples remains a fragile process. To overcome this limitation, we introduce ProtoDiff, a novel framework that leverages a task-guided diffusion model during the meta-training phase to gradually generate prototypes, thereby providing efficient class representations. Specifically, a set of prototypes is optimized to achieve per-task prototype overfitting, enabling accurately obtaining the overfitted prototypes for individual tasks. Furthermore, we introduce a task-guided diffusion process within the prototype space, enabling the meta-learning of a generative process that transitions from a vanilla prototype to an overfitted prototype. ProtoDiff gradually generates task-specific prototypes from random noise during the meta-test stage, conditioned on the limited samples available for the new task. Furthermore, to expedite training and enhance ProtoDiff's performance, we propose the utilization of residual prototype learning, which leverages the sparsity of the residual prototype. We conduct thorough ablation studies to demonstrate its ability to accurately capture the underlying prototype distribution and enhance generalization. The new state-of-the-art performance on within-domain, cross-domain, and few-task few-shot classification further substantiates the benefit of ProtoDiff.
Multi-Label Meta Weighting for Long-Tailed Dynamic Scene Graph Generation
Jun 16, 2023



This paper investigates the problem of scene graph generation in videos with the aim of capturing semantic relations between subjects and objects in the form of $\langle$subject, predicate, object$\rangle$ triplets. Recognizing the predicate between subject and object pairs is imbalanced and multi-label in nature, ranging from ubiquitous interactions such as spatial relationships (\eg \emph{in front of}) to rare interactions such as \emph{twisting}. In widely-used benchmarks such as Action Genome and VidOR, the imbalance ratio between the most and least frequent predicates reaches 3,218 and 3,408, respectively, surpassing even benchmarks specifically designed for long-tailed recognition. Due to the long-tailed distributions and label co-occurrences, recent state-of-the-art methods predominantly focus on the most frequently occurring predicate classes, ignoring those in the long tail. In this paper, we analyze the limitations of current approaches for scene graph generation in videos and identify a one-to-one correspondence between predicate frequency and recall performance. To make the step towards unbiased scene graph generation in videos, we introduce a multi-label meta-learning framework to deal with the biased predicate distribution. Our meta-learning framework learns a meta-weight network for each training sample over all possible label losses. We evaluate our approach on the Action Genome and VidOR benchmarks by building upon two current state-of-the-art methods for each benchmark. The experiments demonstrate that the multi-label meta-weight network improves the performance for predicates in the long tail without compromising performance for head classes, resulting in better overall performance and favorable generalizability. Code: \url{https://github.com/shanshuo/ML-MWN}.