 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Nov 07, 2024



In this work, we address the cooperation problem among large language model (LLM) based embodied agents, where agents must cooperate to achieve a common goal. Previous methods often execute actions extemporaneously and incoherently, without long-term strategic and cooperative planning, leading to redundant steps, failures, and even serious repercussions in complex tasks like search-and-rescue missions where discussion and cooperative plan are crucial. To solve this issue, we propose Cooperative Plan Optimization (CaPo) to enhance the cooperation efficiency of LLM-based embodied agents. Inspired by human cooperation schemes, CaPo improves cooperation efficiency with two phases: 1) meta-plan generation, and 2) progress-adaptive meta-plan and execution. In the first phase, all agents analyze the task, discuss, and cooperatively create a meta-plan that decomposes the task into subtasks with detailed steps, ensuring a long-term strategic and coherent plan for efficient coordination. In the second phase, agents execute tasks according to the meta-plan and dynamically adjust it based on their latest progress (e.g., discovering a target object) through multi-turn discussions. This progress-based adaptation eliminates redundant actions, improving the overall cooperation efficiency of agents. Experimental results on the ThreeDworld Multi-Agent Transport and Communicative Watch-And-Help tasks demonstrate that CaPo achieves much higher task completion rate and efficiency compared with state-of-the-arts.
Deep Reinforcement Learning with Explicit Context Representation
Oct 15, 2023Reinforcement learning (RL) has shown an outstanding capability for solving complex computational problems. However, most RL algorithms lack an explicit method that would allow learning from contextual information. Humans use context to identify patterns and relations among elements in the environment, along with how to avoid making wrong actions. On the other hand, what may seem like an obviously wrong decision from a human perspective could take hundreds of steps for an RL agent to learn to avoid. This paper proposes a framework for discrete environments called Iota explicit context representation (IECR). The framework involves representing each state using contextual key frames (CKFs), which can then be used to extract a function that represents the affordances of the state; in addition, two loss functions are introduced with respect to the affordances of the state. The novelty of the IECR framework lies in its capacity to extract contextual information from the environment and learn from the CKFs' representation. We validate the framework by developing four new algorithms that learn using context: Iota deep Q-network (IDQN), Iota double deep Q-network (IDDQN), Iota dueling deep Q-network (IDuDQN), and Iota dueling double deep Q-network (IDDDQN). Furthermore, we evaluate the framework and the new algorithms in five discrete environments. We show that all the algorithms, which use contextual information, converge in around 40,000 training steps of the neural networks, significantly outperforming their state-of-the-art equivalents.
Predicting Visual Context for Unsupervised Event Segmentation in Continuous Photo-streams
Aug 07, 2018



Segmenting video content into events provides semantic structures for indexing, retrieval, and summarization. Since motion cues are not available in continuous photo-streams, and annotations in lifelogging are scarce and costly, the frames are usually clustered into events by comparing the visual features between them in an unsupervised way. However, such methodologies are ineffective to deal with heterogeneous events, e.g. taking a walk, and temporary changes in the sight direction, e.g. at a meeting. To address these limitations, we propose Contextual Event Segmentation (CES), a novel segmentation paradigm that uses an LSTM-based generative network to model the photo-stream sequences, predict their visual context, and track their evolution. CES decides whether a frame is an event boundary by comparing the visual context generated from the frames in the past, to the visual context predicted from the future. We implemented CES on a new and massive lifelogging dataset consisting of more than 1.5 million images spanning over 1,723 days. Experiments on the popular EDUB-Seg dataset show that our model outperforms the state-of-the-art by over 16% in f-measure. Furthermore, CES' performance is only 3 points below that of human annotators.
CRRN: Multi-Scale Guided Concurrent Reflection Removal Network
May 30, 2018
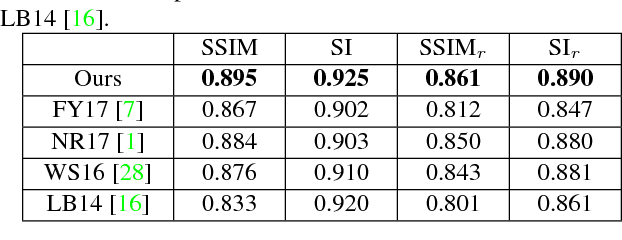

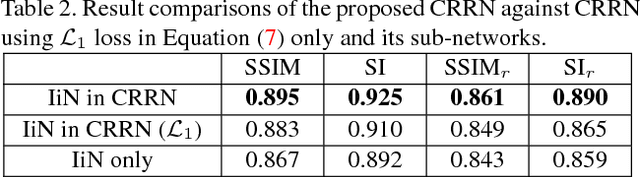
Removing the undesired reflections from images taken through the glass is of broad application to various computer vision tasks. Non-learning based methods utilize different handcrafted priors such as the separable sparse gradients caused by different levels of blurs, which often fail due to their limited description capability to the properties of real-world reflections. In this paper, we propose the Concurrent Reflection Removal Network (CRRN) to tackle this problem in a unified framework. Our proposed network integrates image appearance information and multi-scale gradient information with human perception inspired loss function, and is trained on a new dataset with 3250 reflection images taken under diverse real-world scenes. Extensive experiments on a public benchmark dataset show that the proposed method performs favorably against state-of-the-art methods.