 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ActivityNet Large-Scale Activity Recognition Challenge 2018 Summary
Aug 23, 2018



The 3rd annual installment of the ActivityNet Large- Scale Activity Recognition Challenge, held as a full-day workshop in CVPR 2018, focused on the recognition of daily life, high-level, goal-oriented activities from user-generated videos as those found in internet video portals. The 2018 challenge hosted six diverse tasks which aimed to push the limits of semantic visual understanding of videos as well as bridge visual content with human captions. Three out of the six tasks were based on the ActivityNet dataset, which was introduced in CVPR 2015 and organized hierarchically in a semantic taxonomy. These tasks focused on tracing evidence of activities in time in the form of proposals, class labels, and captions. In this installment of the challenge, we hosted three guest tasks to enrich the understanding of visual information in videos. The guest tasks focused on complementary aspects of the activity recognition problem at large scale and involved three challenging and recently compiled datasets: the Kinetics-600 dataset from Google DeepMind, the AVA dataset from Berkeley and Google, and the Moments in Time dataset from MIT and IBM Research.
Robustness Analysis of Visual QA Models by Basic Questions
May 26, 2018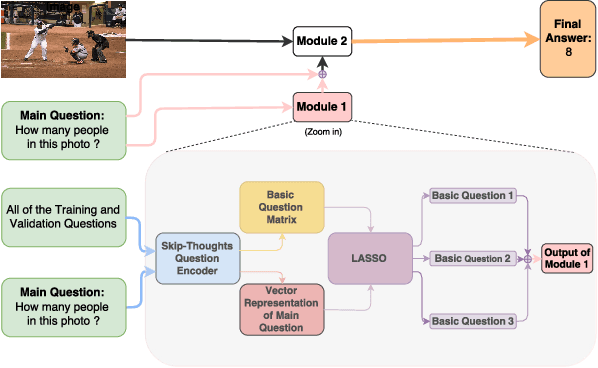
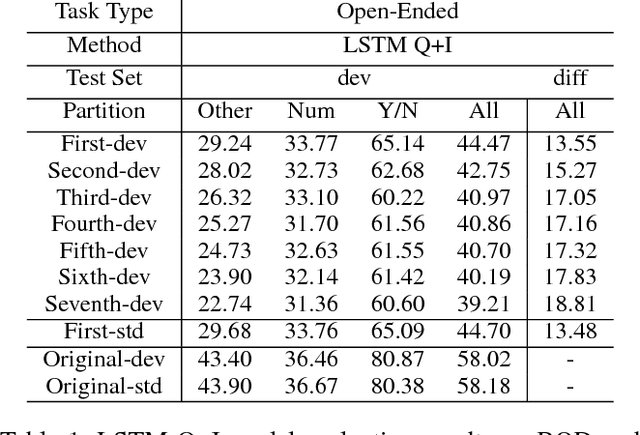
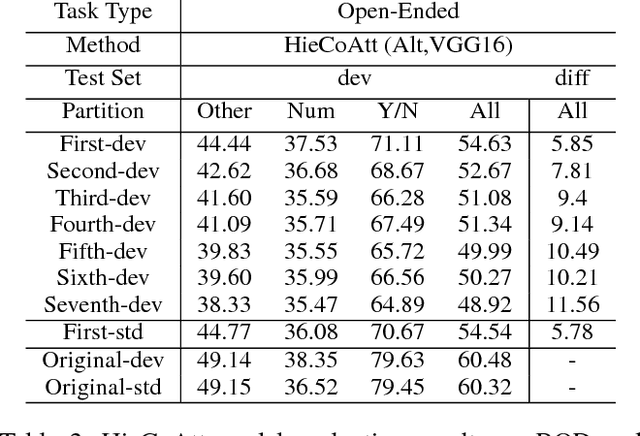
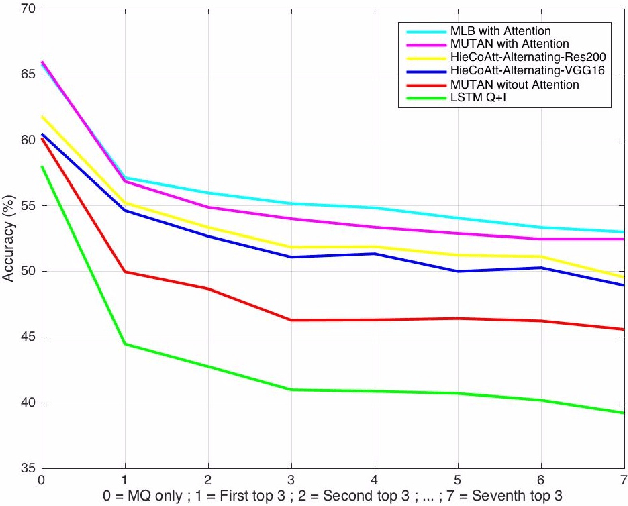
Visual Question Answering (VQA) models should have both high robustness and accuracy. Unfortunately, most of the current VQA research only focuses on accuracy because there is a lack of proper methods to measure the robustness of VQA models. There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the ranked basic questions, with similarity scores, of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question about the given image. We claim that a robust VQA model is one, whose performance is not changed much when related basic questions as also made available to it as input. We formulate the basic questions generation problem as a LASSO optimization, and also propose a large scale Basic Question Dataset (BQD) and Rscore (novel robustness measure), for analyzing the robustness of VQA models. We hope our BQD will be used as a benchmark for to evaluate the robustness of VQA models, so as to help the community build more robust and accurate VQA models.
A Novel Framework for Robustness Analysis of Visual QA Models
Nov 19, 2017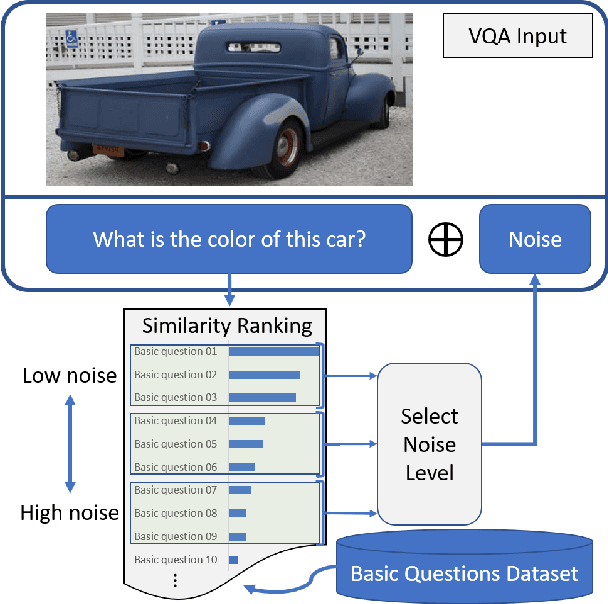
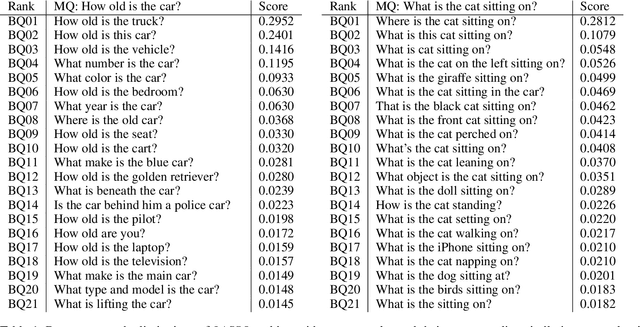
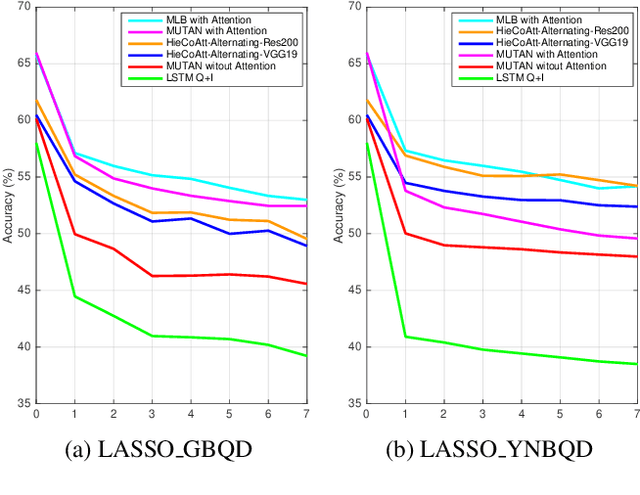
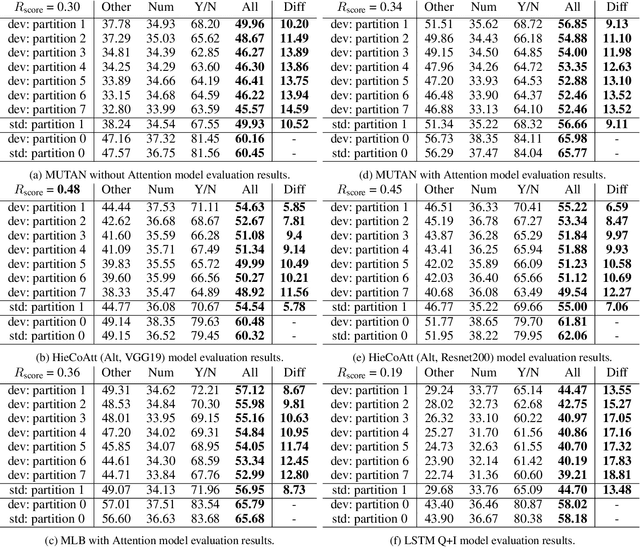
Deep neural networks have been playing an essential role in many computer vision tasks including Visual Question Answering (VQA). Until recently, the study of their accuracy has been the main focus of research and now there is a huge trend toward assessing the robustness of these models against adversarial attacks by evaluating the accuracy of these models under increasing levels of noisiness. In VQA, the attack can target the image and/or the proposed main question and yet there is a lack of proper analysis of this aspect of VQA. In this work, we propose a new framework that uses semantically relevant questions, dubbed basic questions, acting as noise to evaluate the robustness of VQA models. We hypothesize that as the similarity of a basic question to the main question decreases, the level of noise increases. So, to generate a reasonable noise level for a given main question, we rank a pool of basic questions based on their similarity with this main question. We cast this ranking problem as a LASSO optimization problem. We also propose a novel robustness measure R_score and two large-scale question datasets, General Basic Question Dataset and Yes/No Basic Question Dataset in order to standardize robustness analysis of VQA models. We analyze the robustness of several state-of-the-art VQA models and show that attention-based VQA models are more robust than other methods in general. The main goal of this framework is to serve as a benchmark to help the community in building more accurate and robust VQA models.