 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Missing Modality in Multimodal Egocentric Datasets
Jan 21, 2024



Multimodal video understanding is crucial for analyzing egocentric videos, where integrating multiple sensory signals significantly enhances action recognition and moment localization. However, practical applications often grapple with incomplete modalities due to factors like privacy concerns, efficiency demands, or hardware malfunctions. Addressing this, our study delves into the impact of missing modalities on egocentric action recognition, particularly within transformer-based models. We introduce a novel concept -Missing Modality Token (MMT)-to maintain performance even when modalities are absent, a strategy that proves effective in the Ego4D, Epic-Kitchens, and Epic-Sounds datasets. Our method mitigates the performance loss, reducing it from its original $\sim 30\%$ drop to only $\sim 10\%$ when half of the test set is modal-incomplete. Through extensive experimentation, we demonstrate the adaptability of MMT to different training scenarios and its superiority in handling missing modalities compared to current methods. Our research contributes a comprehensive analysis and an innovative approach, opening avenues for more resilient multimodal systems in real-world settings.
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
Nov 23, 2020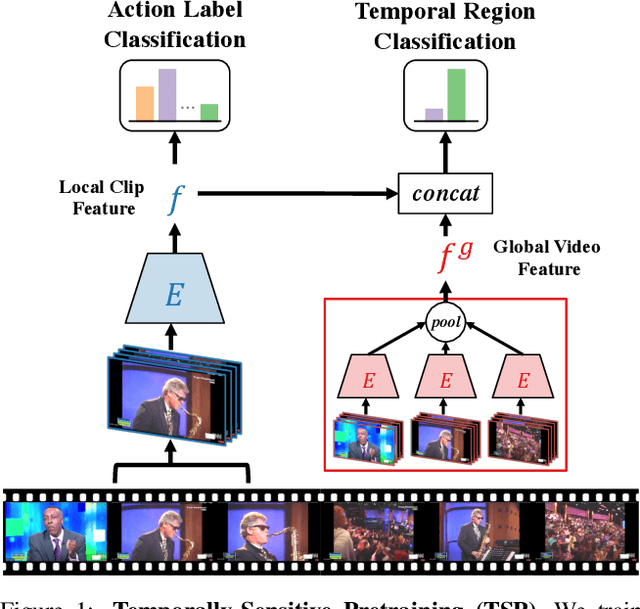


Understanding videos is challenging in computer vision. In particular, the large memory footprint of an untrimmed video makes most tasks infeasible to train end-to-end without dropping part of the input data. To cope with the memory limitation of commodity GPUs, current video localization models encode videos in an offline fashion. Even though these encoders are learned, they are typically trained for action classification tasks at the frame- or clip-level. Since it is difficult to finetune these encoders for other video tasks, they might be sub-optimal for temporal localization tasks. In this work, we propose a novel, supervised pretraining paradigm for clip-level video representation that does not only train to classify activities, but also considers background clips and global video information to gain temporal sensitivity. Extensive experiments show that features extracted by clip-level encoders trained with our novel pretraining task are more discriminative for several temporal localization tasks. Specifically, we show that using our newly trained features with state-of-the-art methods significantly improves performance on three tasks: Temporal Action Localization (+1.72% in average mAP on ActivityNet and +4.4% in mAP@0.5 on THUMOS14), Action Proposal Generation (+1.94% in AUC on ActivityNet), and Dense Video Captioning (+0.31% in average METEOR on ActivityNet Captions). We believe video feature encoding is an important building block for many video algorithms, and extracting meaningful features should be of paramount importance in the effort to build more accurate models.
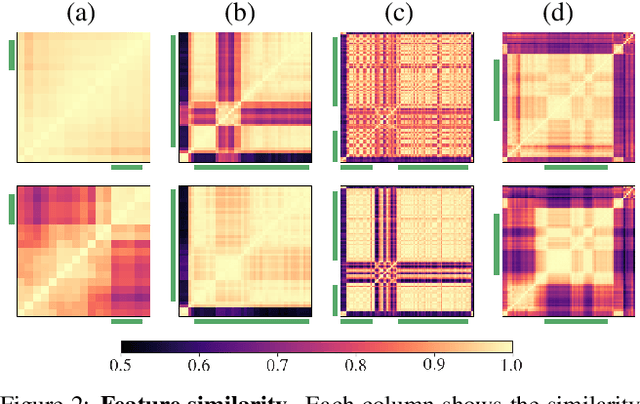
Self-Supervised Learning by Cross-Modal Audio-Video Clustering
Nov 28, 2019
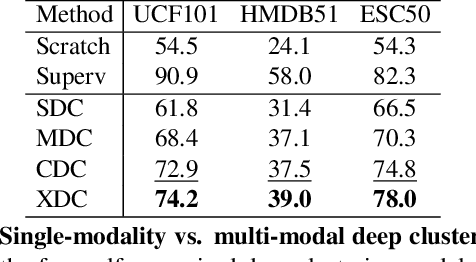

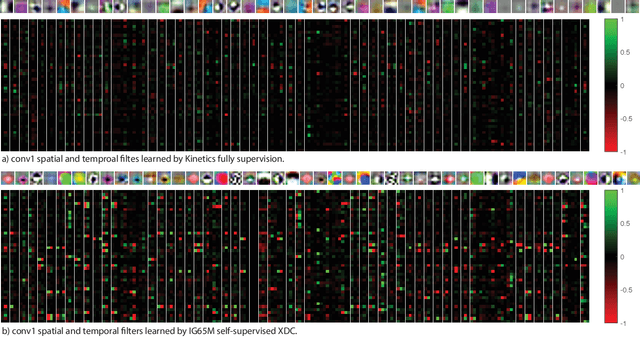
The visual and audio modalities are highly correlated yet they contain different information. Their strong correlation makes it possible to predict the semantics of one from the other with good accuracy. Their intrinsic differences make cross-modal prediction a potentially more rewarding pretext task for self-supervised learning of video and audio representations compared to within-modality learning. Based on this intuition, we propose Cross-Modal Deep Clustering (XDC), a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). This cross-modal supervision helps XDC utilize the semantic correlation and the differences between the two modalities. Our experiments show that XDC significantly outperforms single-modality clustering and other multi-modal variants. Our XDC achieves state-of-the-art accuracy among self-supervised methods on several video and audio benchmarks including HMDB51, UCF101, ESC50, and DCASE. Most importantly, the video model pretrained with XDC significantly outperforms the same model pretrained with full-supervision on both ImageNet and Kinetics in action recognition on HMDB51 and UCF101. To the best of our knowledge, XDC is the first method to demonstrate that self-supervision outperforms large-scale full-supervision in representation learning for action recognition.
MortonNet: Self-Supervised Learning of Local Features in 3D Point Clouds
Mar 30, 2019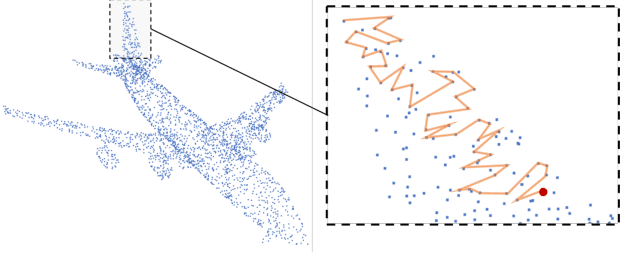
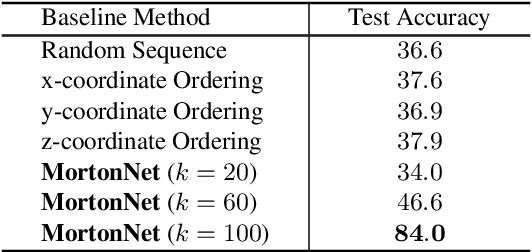
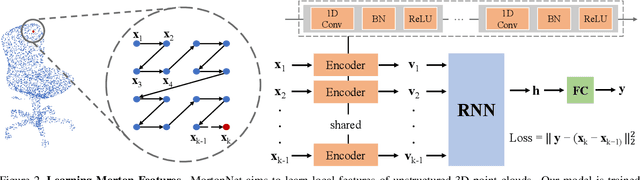
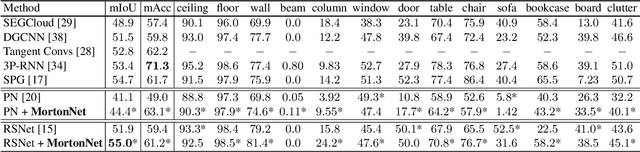
We present a self-supervised task on point clouds, in order to learn meaningful point-wise features that encode local structure around each point. Our self-supervised network, named MortonNet, operates directly on unstructured/unordered point clouds. Using a multi-layer RNN, MortonNet predicts the next point in a point sequence created by a popular and fast Space Filling Curve, the Morton-order curve. The final RNN state (coined Morton feature) is versatile and can be used in generic 3D tasks on point clouds. In fact, we show how Morton features can be used to significantly improve performance (+3% for 2 popular semantic segmentation algorithms) in the task of semantic segmentation of point clouds on the challenging and large-scale S3DIS dataset. We also show how MortonNet trained on S3DIS transfers well to another large-scale dataset, vKITTI, leading to an improvement over state-of-the-art of 3.8%. Finally, we use Morton features to train a much simpler and more stable model for part segmentation in ShapeNet. Our results show how our self-supervised task results in features that are useful for 3D segmentation tasks, and generalize well to other datasets.
RefineLoc: Iterative Refinement for Weakly-Supervised Action Localization
Mar 30, 2019
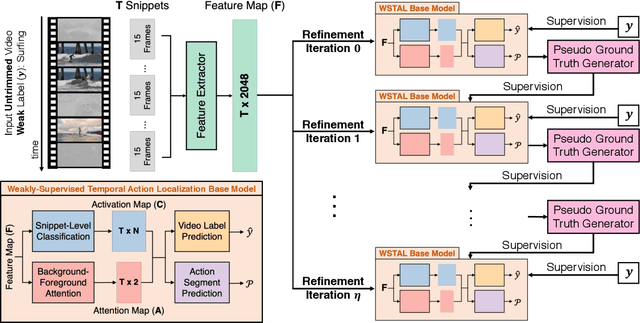


Video action detectors are usually trained using video datasets with fully supervised temporal annotations. Building such video datasets is a heavily expensive task. To alleviate this problem, recent algorithms leverage weak labelling where videos are untrimmed and only a video-level label is available. In this paper, we propose RefineLoc, a new method for weakly-supervised temporal action localization. RefineLoc uses an iterative refinement approach by estimating and training on snippet-level pseudo ground truth at every iteration. We show the benefit of using such an iterative approach and present an extensive analysis of different pseudo ground truth generators. We show the effectiveness of our model on two standard action datasets, ActivityNet v1.2 and THUMOS14. RefineLoc equipped with a segment prediction-based pseudo ground truth generator improves the state-of-the-art in weakly-supervised temporal localization on the challenging and large-scale ActivityNet dataset by 4.2% and achieves comparable performance with state-of-the-art on THUMOS14.
The ActivityNet Large-Scale Activity Recognition Challenge 2018 Summary
Aug 23, 2018



The 3rd annual installment of the ActivityNet Large- Scale Activity Recognition Challenge, held as a full-day workshop in CVPR 2018, focused on the recognition of daily life, high-level, goal-oriented activities from user-generated videos as those found in internet video portals. The 2018 challenge hosted six diverse tasks which aimed to push the limits of semantic visual understanding of videos as well as bridge visual content with human captions. Three out of the six tasks were based on the ActivityNet dataset, which was introduced in CVPR 2015 and organized hierarchically in a semantic taxonomy. These tasks focused on tracing evidence of activities in time in the form of proposals, class labels, and captions. In this installment of the challenge, we hosted three guest tasks to enrich the understanding of visual information in videos. The guest tasks focused on complementary aspects of the activity recognition problem at large scale and involved three challenging and recently compiled datasets: the Kinetics-600 dataset from Google DeepMind, the AVA dataset from Berkeley and Google, and the Moments in Time dataset from MIT and IBM Research.
Action Search: Spotting Actions in Videos and Its Application to Temporal Action Localization
Jul 27, 2018
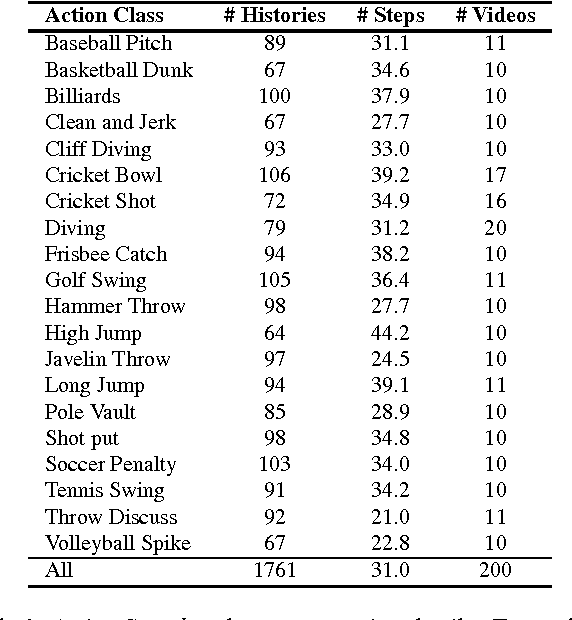
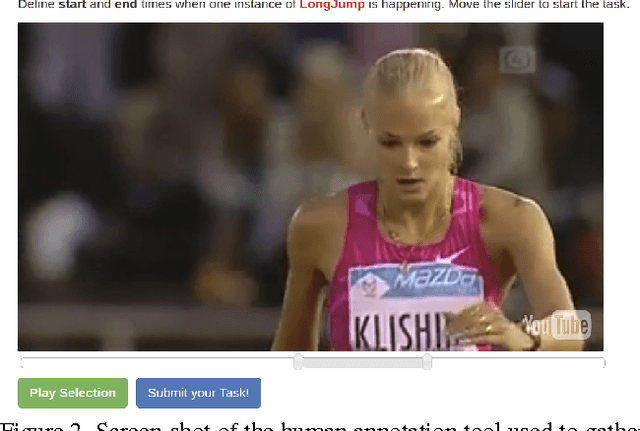

State-of-the-art temporal action detectors inefficiently search the entire video for specific actions. Despite the encouraging progress these methods achieve, it is crucial to design automated approaches that only explore parts of the video which are the most relevant to the actions being searched for. To address this need, we propose the new problem of action spotting in video, which we define as finding a specific action in a video while observing a small portion of that video. Inspired by the observation that humans are extremely efficient and accurate in spotting and finding action instances in video, we propose Action Search, a novel Recurrent Neural Network approach that mimics the way humans spot actions. Moreover, to address the absence of data recording the behavior of human annotators, we put forward the Human Searches dataset, which compiles the search sequences employed by human annotators spotting actions in the AVA and THUMOS14 datasets. We consider temporal action localization as an application of the action spotting problem. Experiments on the THUMOS14 dataset reveal that our model is not only able to explore the video efficiently (observing on average 17.3% of the video) but it also accurately finds human activities with 30.8% mAP.
Diagnosing Error in Temporal Action Detectors
Jul 27, 2018



Despite the recent progress in video understanding and the continuous rate of improvement in temporal action localization throughout the years, it is still unclear how far (or close?) we are to solving the problem. To this end, we introduce a new diagnostic tool to analyze the performance of temporal action detectors in videos and compare different methods beyond a single scalar metric. We exemplify the use of our tool by analyzing the performance of the top rewarded entries in the latest ActivityNet action localization challenge. Our analysis shows that the most impactful areas to work on are: strategies to better handle temporal context around the instances, improving the robustness w.r.t. the instance absolute and relative size, and strategies to reduce the localization errors. Moreover, our experimental analysis finds the lack of agreement among annotator is not a major roadblock to attain progress in the field. Our diagnostic tool is publicly available to keep fueling the minds of other researchers with additional insights about their algorithms.
ActivityNet Challenge 2017 Summary
Oct 22, 2017



The ActivityNet Large Scale Activity Recognition Challenge 2017 Summary: results and challenge participants papers.