 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Machine Learning for Integrating Heterogeneous Analytical Systems
Jan 31, 2026Understanding structure-property relationships in complex materials requires integrating complementary measurements across multiple length scales. Here we propose an interpretable "multimodal" machine learning framework that unifies heterogeneous analytical systems for end-to-end characterization, demonstrated on carbon nanotube (CNT) films whose properties are highly sensitive to microstructural variations. Quantitative morphology descriptors are extracted from SEM images via binarization, skeletonization, and network analysis, capturing curvature, orientation, intersection density, and void geometry. These SEM-derived features are fused with Raman indicators of crystallinity/defect states, specific surface area from gas adsorption, and electrical surface resistivity. Multi-dimensional visualization using radar plots and UMAP reveals clear clustering of CNT films according to crystallinity and entanglements. Regression models trained on the multimodal feature set show that nonlinear approaches, particularly XGBoost, achieve the best predictive accuracy under leave-one-out cross-validation. Feature-importance analysis further provides physically meaningful interpretations: surface resistivity is primarily governed by junction-to-junction transport length scales, crystallinity/defect-related metrics, and network connectivity, whereas specific surface area is dominated by intersection density and void size. The proposed multimodal machine learning framework offers a general strategy for data-driven, explainable characterization of complex materials.
Real-time Autonomous Control of a Continuous Macroscopic Process as Demonstrated by Plastic Forming
Dec 14, 2023


To meet the demands for more adaptable and expedient approaches to augment both research and manufacturing, we report an autonomous system using real-time in-situ characterization and an autonomous, decision-making processer based on an active learning algorithm. This system was applied to a plastic film forming system to highlight its efficiency and accuracy in determining the process conditions for specified target film dimensions, importantly, without any human intervention. Application of this system towards nine distinct film dimensions demonstrated the system ability to quickly determine the appropriate and stable process conditions (average 11 characterization-adjustment iterations, 19 minutes) and the ability to avoid traps, such as repetitive over-correction. Furthermore, comparison of the achieved film dimensions to the target values showed a high accuracy (R2 = 0.87, 0.90) for film width and thickness, respectively. In addition, the use of an active learning algorithm afforded our system to proceed optimization with zero initial training data, which was unavailable due to the complex relationships between the control factors (material supply rate, applied force, material viscosity) within the plastic forming process. As our system is intrinsically general and can be applied to any most material processes, these results have significant implications in accelerating both research and industrial processes.
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
Dec 05, 2023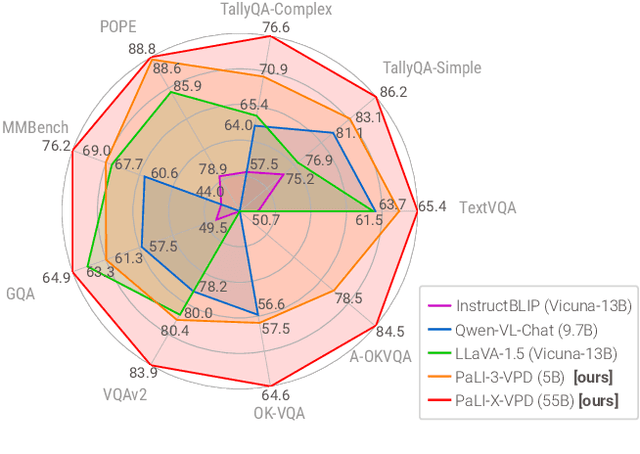
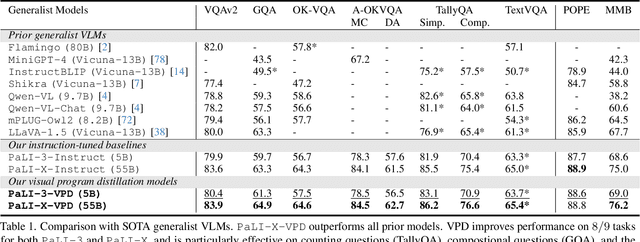
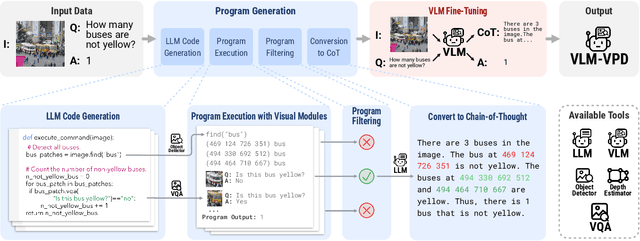
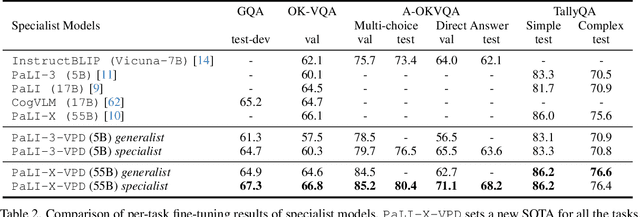
Solving complex visual tasks such as "Who invented the musical instrument on the right?" involves a composition of skills: understanding space, recognizing instruments, and also retrieving prior knowledge. Recent work shows promise by decomposing such tasks using a large language model (LLM) into an executable program that invokes specialized vision models. However, generated programs are error-prone: they omit necessary steps, include spurious ones, and are unable to recover when the specialized models give incorrect outputs. Moreover, they require loading multiple models, incurring high latency and computation costs. We propose Visual Program Distillation (VPD), an instruction tuning framework that produces a vision-language model (VLM) capable of solving complex visual tasks with a single forward pass. VPD distills the reasoning ability of LLMs by using them to sample multiple candidate programs, which are then executed and verified to identify a correct one. It translates each correct program into a language description of the reasoning steps, which are then distilled into a VLM. Extensive experiments show that VPD improves the VLM's ability to count, understand spatial relations, and reason compositionally. Our VPD-trained PaLI-X outperforms all prior VLMs, achieving state-of-the-art performance across complex vision tasks, including MMBench, OK-VQA, A-OKVQA, TallyQA, POPE, and Hateful Memes. An evaluation with human annotators also confirms that VPD improves model response factuality and consistency. Finally, experiments on content moderation demonstrate that VPD is also helpful for adaptation to real-world applications with limited data.
Learning to Detect Touches on Cluttered Tables
Apr 10, 2023
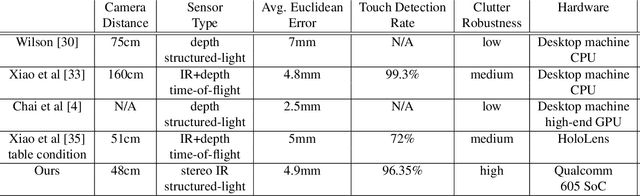

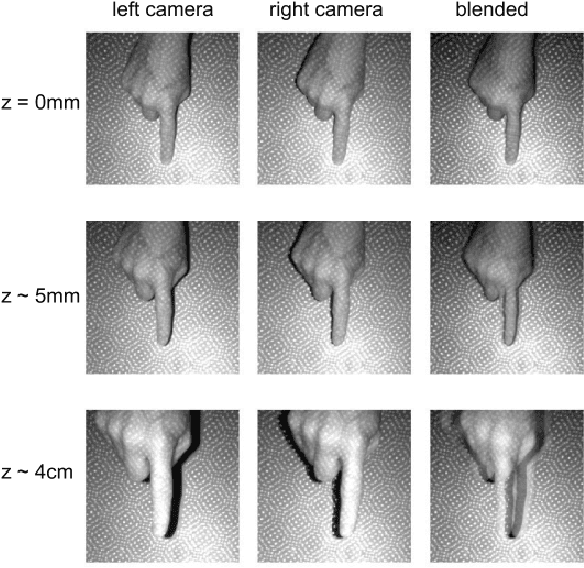
We present a novel self-contained camera-projector tabletop system with a lamp form-factor that brings digital intelligence to our tables. We propose a real-time, on-device, learning-based touch detection algorithm that makes any tabletop interactive. The top-down configuration and learning-based algorithm makes our method robust to the presence of clutter, a main limitation of existing camera-projector tabletop systems. Our research prototype enables a set of experiences that combine hand interactions and objects present on the table. A video can be found at https://youtu.be/hElC_c25Fg8.
A Comprehensive and Versatile Multimodal Deep Learning Approach for Predicting Diverse Properties of Advanced Materials
Mar 29, 2023We present a multimodal deep learning (MDL) framework for predicting physical properties of a 10-dimensional acrylic polymer composite material by merging physical attributes and chemical data. Our MDL model comprises four modules, including three generative deep learning models for material structure characterization and a fourth model for property prediction. Our approach handles an 18-dimensional complexity, with 10 compositional inputs and 8 property outputs, successfully predicting 913,680 property data points across 114,210 composition conditions. This level of complexity is unprecedented in computational materials science, particularly for materials with undefined structures. We propose a framework to analyze the high-dimensional information space for inverse material design, demonstrating flexibility and adaptability to various materials and scales, provided sufficient data is available. This study advances future research on different materials and the development of more sophisticated models, drawing us closer to the ultimate goal of predicting all properties of all materials.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

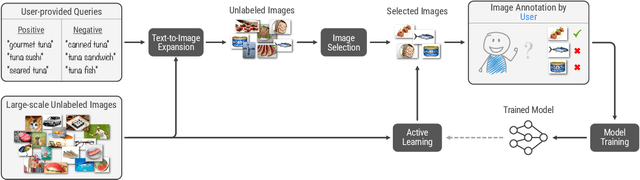
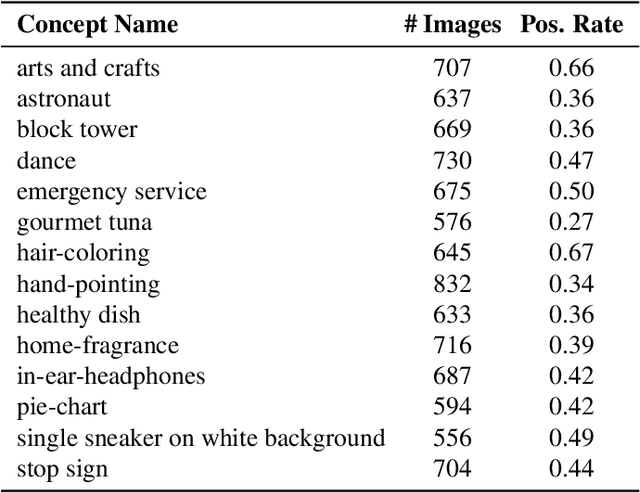
Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
Towards Fairness in Visual Recognition: Effective Strategies for Bias Mitigation
Nov 26, 2019
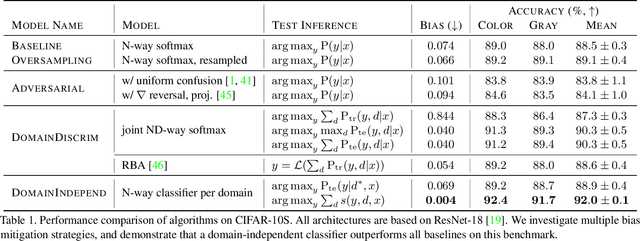

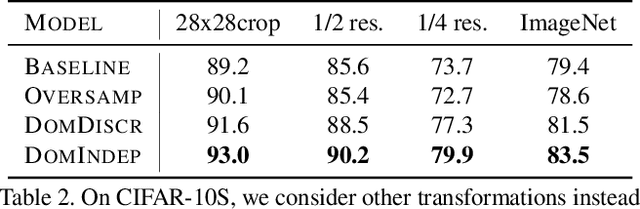
Computer vision models learn to perform a task by capturing relevant statistics from training data. It has been shown that models learn spurious age, gender, and race correlations when trained for seemingly unrelated tasks like activity recognition or image captioning. Various mitigation techniques have been presented to prevent models from utilizing or learning such biases. However, there has been little systematic comparison between these techniques. We design a simple but surprisingly effective visual recognition benchmark for studying bias mitigation. Using this benchmark, we provide a thorough analysis of a wide range of techniques. We highlight the shortcomings of popular adversarial training approaches for bias mitigation, propose a simple but similarly effective alternative to the inference-time Reducing Bias Amplification method of Zhao et al., and design a domain-independent training technique that outperforms all other methods. Finally, we validate our findings on the attribute classification task in the CelebA dataset, where attribute presence is known to be correlated with the gender of people in the image, and demonstrate that the proposed technique is effective at mitigating real-world gender bias.
ActivityNet Challenge 2017 Summary
Oct 22, 2017



The ActivityNet Large Scale Activity Recognition Challenge 2017 Summary: results and challenge participants papers.
Dense-Captioning Events in Videos
May 02, 2017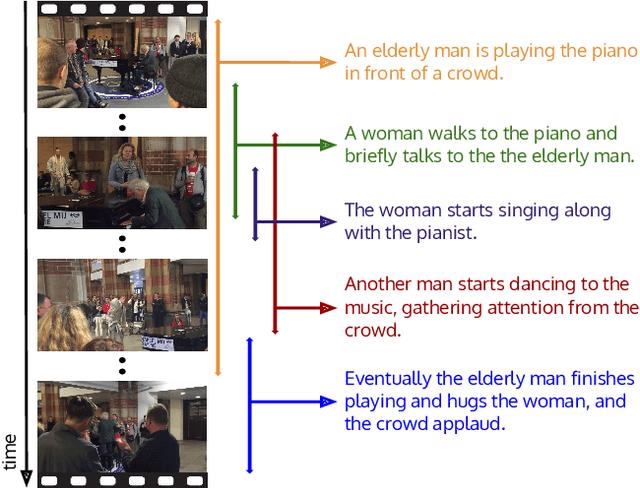
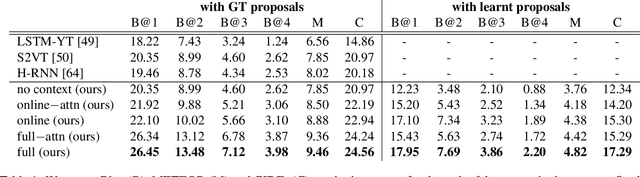
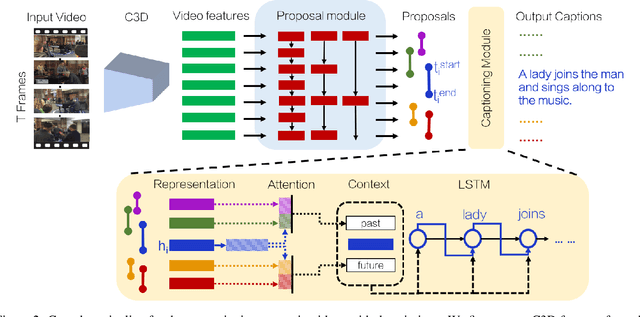
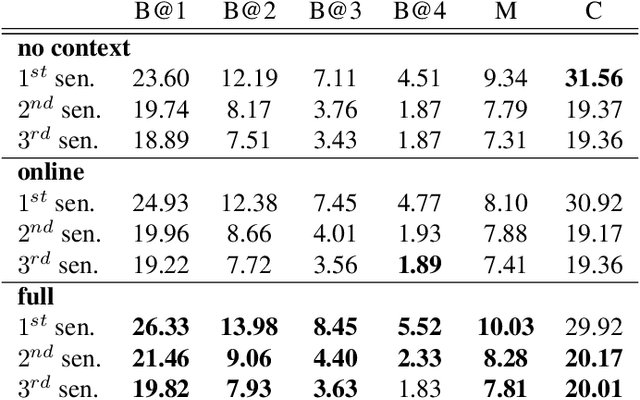
Most natural videos contain numerous events. For example, in a video of a "man playing a piano", the video might also contain "another man dancing" or "a crowd clapping". We introduce the task of dense-captioning events, which involves both detecting and describing events in a video. We propose a new model that is able to identify all events in a single pass of the video while simultaneously describing the detected events with natural language. Our model introduces a variant of an existing proposal module that is designed to capture both short as well as long events that span minutes. To capture the dependencies between the events in a video, our model introduces a new captioning module that uses contextual information from past and future events to jointly describe all events. We also introduce ActivityNet Captions, a large-scale benchmark for dense-captioning events. ActivityNet Captions contains 20k videos amounting to 849 video hours with 100k total descriptions, each with it's unique start and end time. Finally, we report performances of our model for dense-captioning events, video retrieval and localization.
A Glimpse Far into the Future: Understanding Long-term Crowd Worker Quality
Nov 01, 2016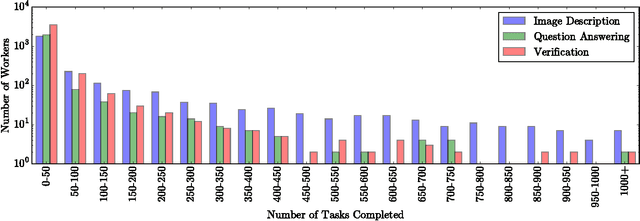

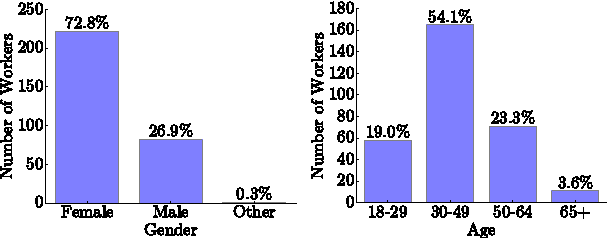
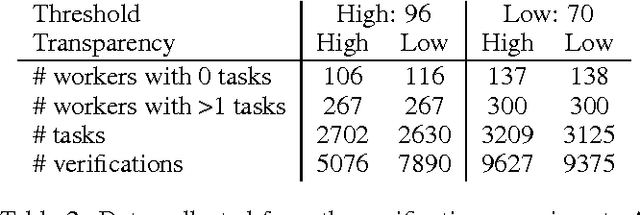
Microtask crowdsourcing is increasingly critical to the creation of extremely large datasets. As a result, crowd workers spend weeks or months repeating the exact same tasks, making it necessary to understand their behavior over these long periods of time. We utilize three large, longitudinal datasets of nine million annotations collected from Amazon Mechanical Turk to examine claims that workers fatigue or satisfice over these long periods, producing lower quality work. We find that, contrary to these claims, workers are extremely stable in their quality over the entire period. To understand whether workers set their quality based on the task's requirements for acceptance, we then perform an experiment where we vary the required quality for a large crowdsourcing task. Workers did not adjust their quality based on the acceptance threshold: workers who were above the threshold continued working at their usual quality level, and workers below the threshold self-selected themselves out of the task. Capitalizing on this consistency, we demonstrate that it is possible to predict workers' long-term quality using just a glimpse of their quality on the first five tasks.