 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Deliberation: Concept Deliberation for Subjective Visual Classification
Dec 11, 2025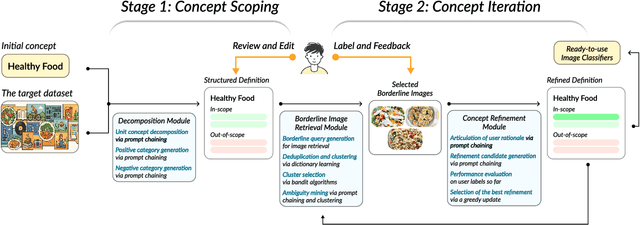
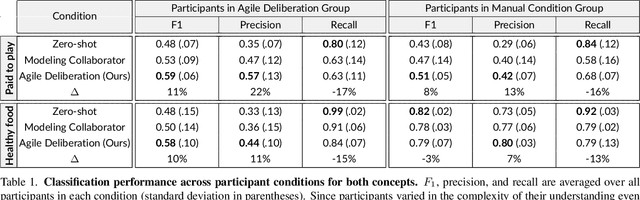
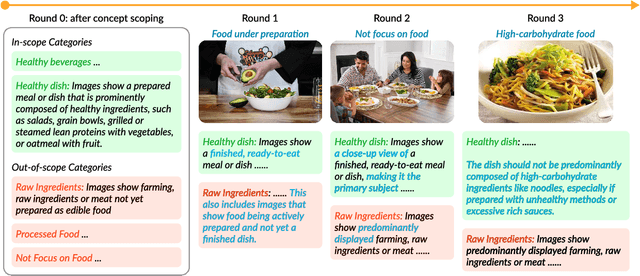
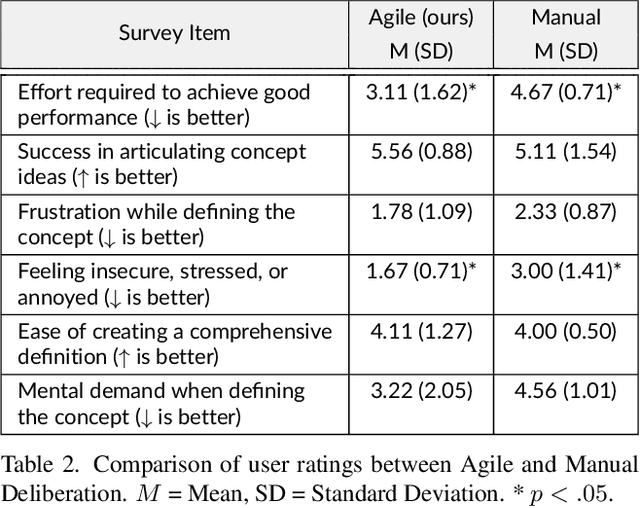
From content moderation to content curation, applications requiring vision classifiers for visual concepts are rapidly expanding. Existing human-in-the-loop approaches typically assume users begin with a clear, stable concept understanding to be able to provide high-quality supervision. In reality, users often start with a vague idea and must iteratively refine it through "concept deliberation", a practice we uncovered through structured interviews with content moderation experts. We operationalize the common strategies in deliberation used by real content moderators into a human-in-the-loop framework called "Agile Deliberation" that explicitly supports evolving and subjective concepts. The system supports users in defining the concept for themselves by exposing them to borderline cases. The system does this with two deliberation stages: (1) concept scoping, which decomposes the initial concept into a structured hierarchy of sub-concepts, and (2) concept iteration, which surfaces semantically borderline examples for user reflection and feedback to iteratively align an image classifier with the user's evolving intent. Since concept deliberation is inherently subjective and interactive, we painstakingly evaluate the framework through 18 user sessions, each 1.5h long, rather than standard benchmarking datasets. We find that Agile Deliberation achieves 7.5% higher F1 scores than automated decomposition baselines and more than 3% higher than manual deliberation, while participants reported clearer conceptual understanding and lower cognitive effort.
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
Dec 05, 2023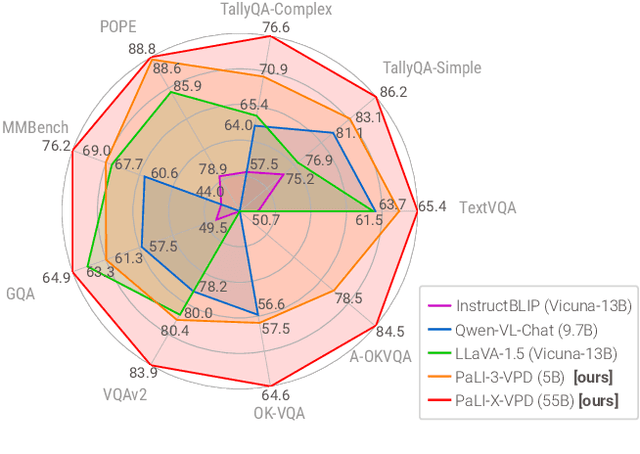
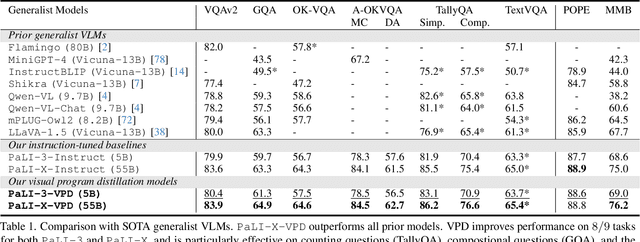
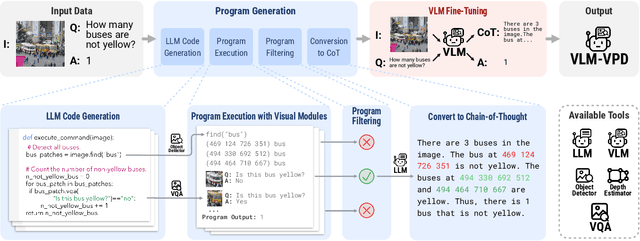
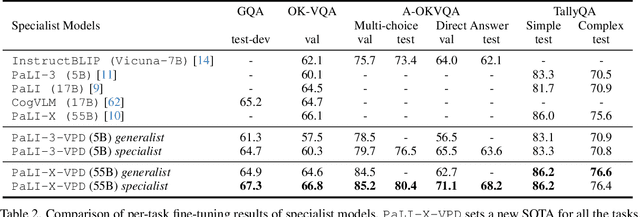
Solving complex visual tasks such as "Who invented the musical instrument on the right?" involves a composition of skills: understanding space, recognizing instruments, and also retrieving prior knowledge. Recent work shows promise by decomposing such tasks using a large language model (LLM) into an executable program that invokes specialized vision models. However, generated programs are error-prone: they omit necessary steps, include spurious ones, and are unable to recover when the specialized models give incorrect outputs. Moreover, they require loading multiple models, incurring high latency and computation costs. We propose Visual Program Distillation (VPD), an instruction tuning framework that produces a vision-language model (VLM) capable of solving complex visual tasks with a single forward pass. VPD distills the reasoning ability of LLMs by using them to sample multiple candidate programs, which are then executed and verified to identify a correct one. It translates each correct program into a language description of the reasoning steps, which are then distilled into a VLM. Extensive experiments show that VPD improves the VLM's ability to count, understand spatial relations, and reason compositionally. Our VPD-trained PaLI-X outperforms all prior VLMs, achieving state-of-the-art performance across complex vision tasks, including MMBench, OK-VQA, A-OKVQA, TallyQA, POPE, and Hateful Memes. An evaluation with human annotators also confirms that VPD improves model response factuality and consistency. Finally, experiments on content moderation demonstrate that VPD is also helpful for adaptation to real-world applications with limited data.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

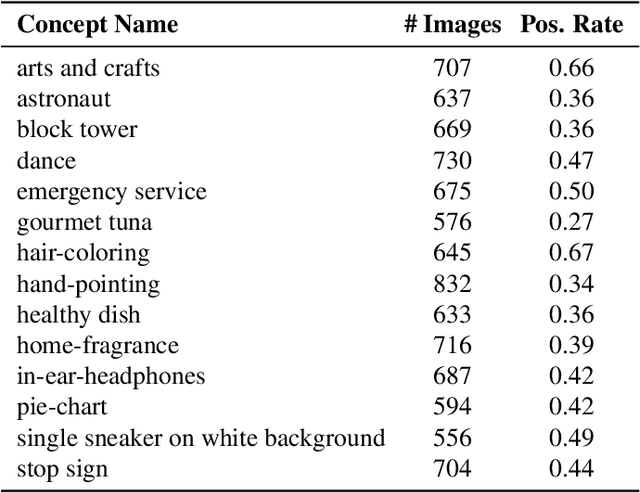
Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
On Modeling Profiles instead of Values
Jul 11, 2012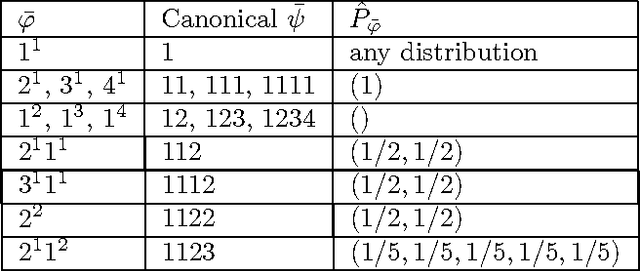
We consider the problem of estimating the distribution underlying an observed sample of data. Instead of maximum likelihood, which maximizes the probability of the ob served values, we propose a different estimate, the high-profile distribution, which maximizes the probability of the observed profile the number of symbols appearing any given number of times. We determine the high-profile distribution of several data samples, establish some of its general properties, and show that when the number of distinct symbols observed is small compared to the data size, the high-profile and maximum-likelihood distributions are roughly the same, but when the number of symbols is large, the distributions differ, and high-profile better explains the data.