 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Deliberation: Concept Deliberation for Subjective Visual Classification
Dec 11, 2025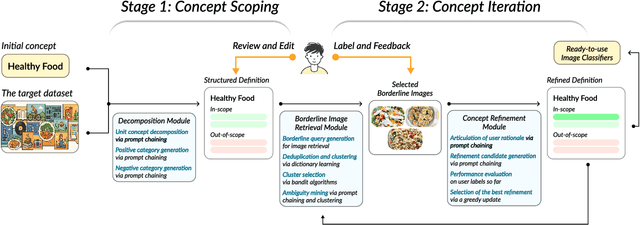
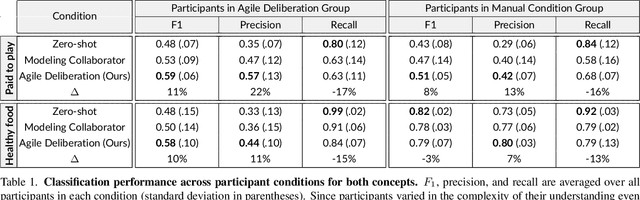
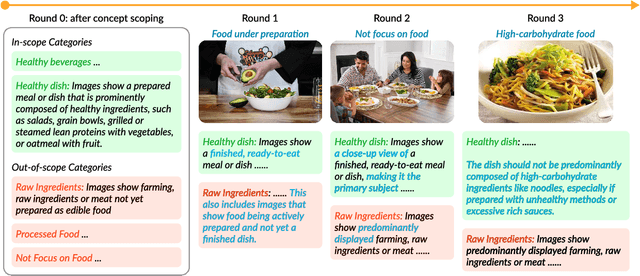
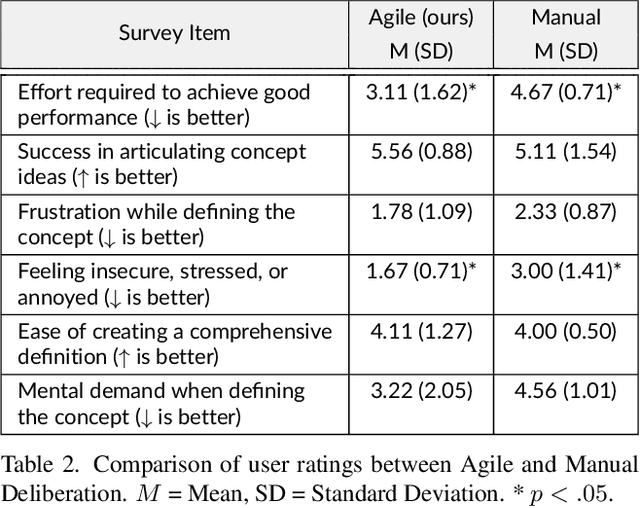
From content moderation to content curation, applications requiring vision classifiers for visual concepts are rapidly expanding. Existing human-in-the-loop approaches typically assume users begin with a clear, stable concept understanding to be able to provide high-quality supervision. In reality, users often start with a vague idea and must iteratively refine it through "concept deliberation", a practice we uncovered through structured interviews with content moderation experts. We operationalize the common strategies in deliberation used by real content moderators into a human-in-the-loop framework called "Agile Deliberation" that explicitly supports evolving and subjective concepts. The system supports users in defining the concept for themselves by exposing them to borderline cases. The system does this with two deliberation stages: (1) concept scoping, which decomposes the initial concept into a structured hierarchy of sub-concepts, and (2) concept iteration, which surfaces semantically borderline examples for user reflection and feedback to iteratively align an image classifier with the user's evolving intent. Since concept deliberation is inherently subjective and interactive, we painstakingly evaluate the framework through 18 user sessions, each 1.5h long, rather than standard benchmarking datasets. We find that Agile Deliberation achieves 7.5% higher F1 scores than automated decomposition baselines and more than 3% higher than manual deliberation, while participants reported clearer conceptual understanding and lower cognitive effort.
Zero-Shot Image Moderation in Google Ads with LLM-Assisted Textual Descriptions and Cross-modal Co-embeddings
Dec 18, 2024

We present a scalable and agile approach for ads image content moderation at Google, addressing the challenges of moderating massive volumes of ads with diverse content and evolving policies. The proposed method utilizes human-curated textual descriptions and cross-modal text-image co-embeddings to enable zero-shot classification of policy violating ads images, bypassing the need for extensive supervised training data and human labeling. By leveraging large language models (LLMs) and user expertise, the system generates and refines a comprehensive set of textual descriptions representing policy guidelines. During inference, co-embedding similarity between incoming images and the textual descriptions serves as a reliable signal for policy violation detection, enabling efficient and adaptable ads content moderation. Evaluation results demonstrate the efficacy of this framework in significantly boosting the detection of policy violating content.
Why Fine-grained Labels in Pretraining Benefit Generalization?
Oct 30, 2024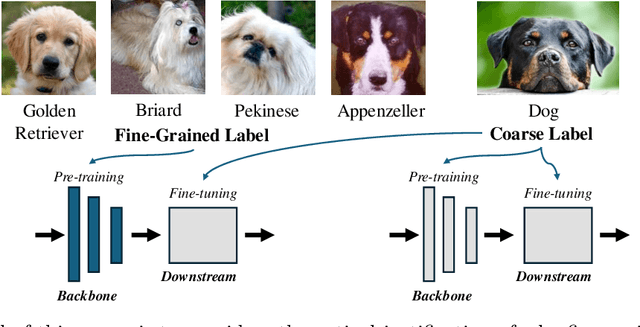

Recent studies show that pretraining a deep neural network with fine-grained labeled data, followed by fine-tuning on coarse-labeled data for downstream tasks, often yields better generalization than pretraining with coarse-labeled data. While there is ample empirical evidence supporting this, the theoretical justification remains an open problem. This paper addresses this gap by introducing a "hierarchical multi-view" structure to confine the input data distribution. Under this framework, we prove that: 1) coarse-grained pretraining only allows a neural network to learn the common features well, while 2) fine-grained pretraining helps the network learn the rare features in addition to the common ones, leading to improved accuracy on hard downstream test samples.
Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
Mar 05, 2024From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Scaling Up LLM Reviews for Google Ads Content Moderation
Feb 07, 2024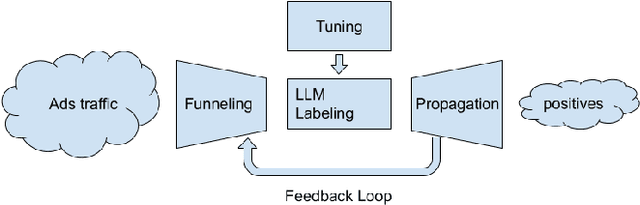
Large language models (LLMs) are powerful tools for content moderation, but their inference costs and latency make them prohibitive for casual use on large datasets, such as the Google Ads repository. This study proposes a method for scaling up LLM reviews for content moderation in Google Ads. First, we use heuristics to select candidates via filtering and duplicate removal, and create clusters of ads for which we select one representative ad per cluster. We then use LLMs to review only the representative ads. Finally, we propagate the LLM decisions for the representative ads back to their clusters. This method reduces the number of reviews by more than 3 orders of magnitude while achieving a 2x recall compared to a baseline non-LLM model. The success of this approach is a strong function of the representations used in clustering and label propagation; we found that cross-modal similarity representations yield better results than uni-modal representations.
Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models
Dec 05, 2023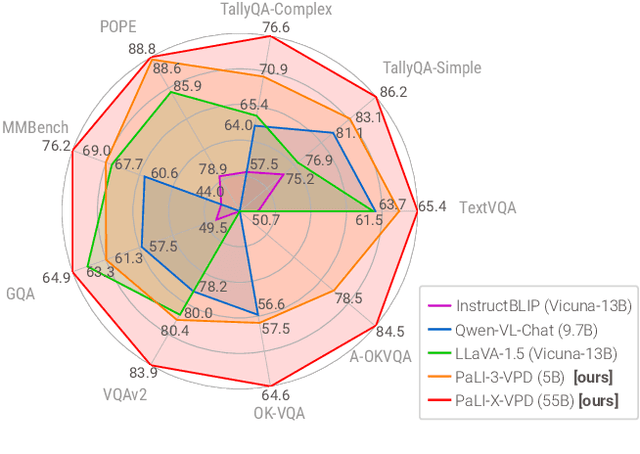
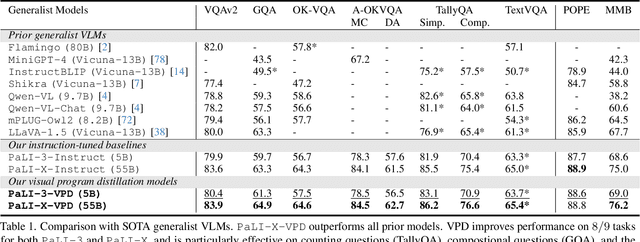
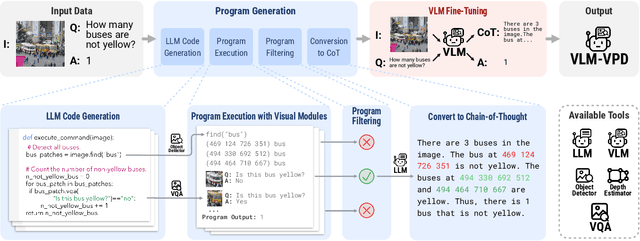
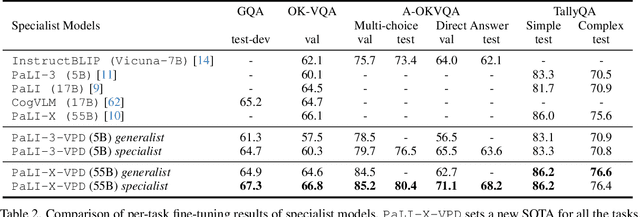
Solving complex visual tasks such as "Who invented the musical instrument on the right?" involves a composition of skills: understanding space, recognizing instruments, and also retrieving prior knowledge. Recent work shows promise by decomposing such tasks using a large language model (LLM) into an executable program that invokes specialized vision models. However, generated programs are error-prone: they omit necessary steps, include spurious ones, and are unable to recover when the specialized models give incorrect outputs. Moreover, they require loading multiple models, incurring high latency and computation costs. We propose Visual Program Distillation (VPD), an instruction tuning framework that produces a vision-language model (VLM) capable of solving complex visual tasks with a single forward pass. VPD distills the reasoning ability of LLMs by using them to sample multiple candidate programs, which are then executed and verified to identify a correct one. It translates each correct program into a language description of the reasoning steps, which are then distilled into a VLM. Extensive experiments show that VPD improves the VLM's ability to count, understand spatial relations, and reason compositionally. Our VPD-trained PaLI-X outperforms all prior VLMs, achieving state-of-the-art performance across complex vision tasks, including MMBench, OK-VQA, A-OKVQA, TallyQA, POPE, and Hateful Memes. An evaluation with human annotators also confirms that VPD improves model response factuality and consistency. Finally, experiments on content moderation demonstrate that VPD is also helpful for adaptation to real-world applications with limited data.
Towards Understanding the Effect of Pretraining Label Granularity
Mar 29, 2023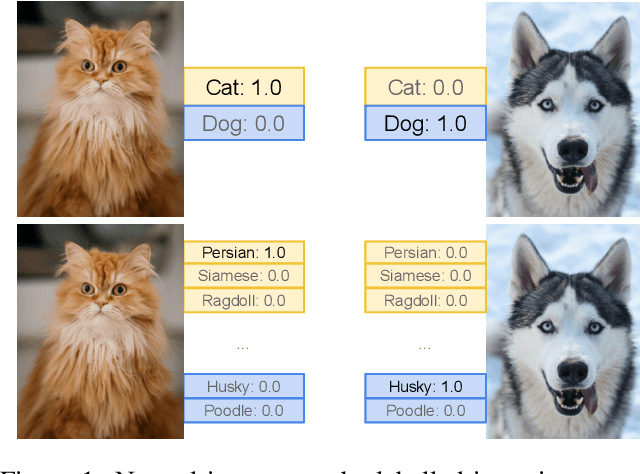
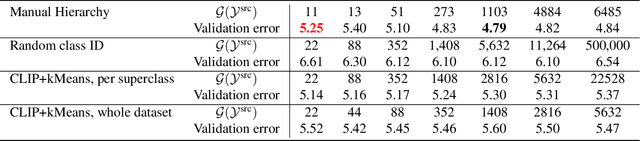
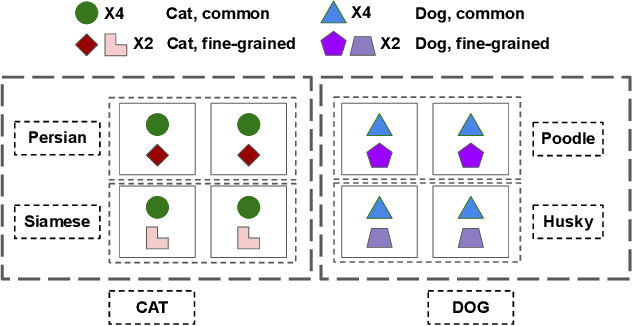
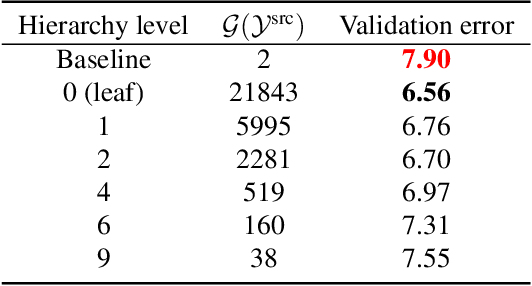
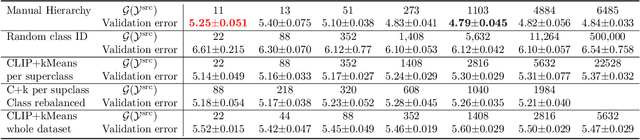
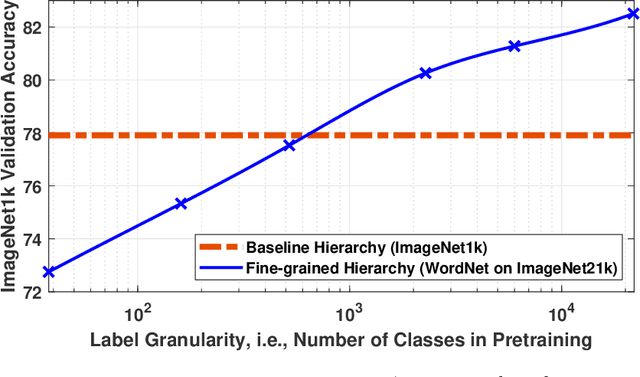
In this paper, we study how pretraining label granularity affects the generalization of deep neural networks in image classification tasks. We focus on the "fine-to-coarse" transfer learning setting where the pretraining label is more fine-grained than that of the target problem. We experiment with this method using the label hierarchy of iNaturalist 2021, and observe a 8.76% relative improvement of the error rate over the baseline. We find the following conditions are key for the improvement: 1) the pretraining dataset has a strong and meaningful label hierarchy, 2) its label function strongly aligns with that of the target task, and most importantly, 3) an appropriate level of pretraining label granularity is chosen. The importance of pretraining label granularity is further corroborated by our transfer learning experiments on ImageNet. Most notably, we show that pretraining at the leaf labels of ImageNet21k produces better transfer results on ImageNet1k than pretraining at other coarser granularity levels, which supports the common practice. Theoretically, through an analysis on a two-layer convolutional ReLU network, we prove that: 1) models trained on coarse-grained labels only respond strongly to the common or "easy-to-learn" features; 2) with the dataset satisfying the right conditions, fine-grained pretraining encourages the model to also learn rarer or "harder-to-learn" features well, thus improving the model's generalization.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

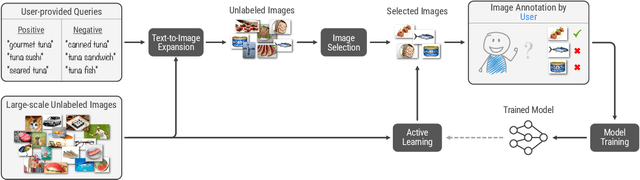
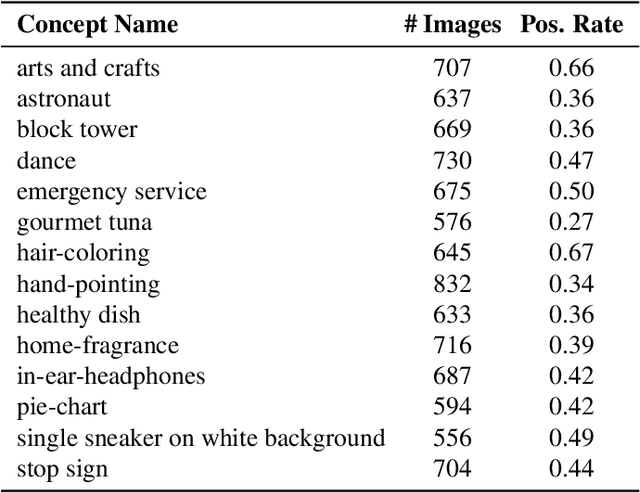
Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
Benchmarking Robustness to Adversarial Image Obfuscations
Jan 30, 2023



Automated content filtering and moderation is an important tool that allows online platforms to build striving user communities that facilitate cooperation and prevent abuse. Unfortunately, resourceful actors try to bypass automated filters in a bid to post content that violate platform policies and codes of conduct. To reach this goal, these malicious actors may obfuscate policy violating images (e.g. overlay harmful images by carefully selected benign images or visual patterns) to prevent machine learning models from reaching the correct decision. In this paper, we invite researchers to tackle this specific issue and present a new image benchmark. This benchmark, based on ImageNet, simulates the type of obfuscations created by malicious actors. It goes beyond ImageNet-$\textrm{C}$ and ImageNet-$\bar{\textrm{C}}$ by proposing general, drastic, adversarial modifications that preserve the original content intent. It aims to tackle a more common adversarial threat than the one considered by $\ell_p$-norm bounded adversaries. We evaluate 33 pretrained models on the benchmark and train models with different augmentations, architectures and training methods on subsets of the obfuscations to measure generalization. We hope this benchmark will encourage researchers to test their models and methods and try to find new approaches that are more robust to these obfuscations.
CARLS: Cross-platform Asynchronous Representation Learning System
May 26, 2021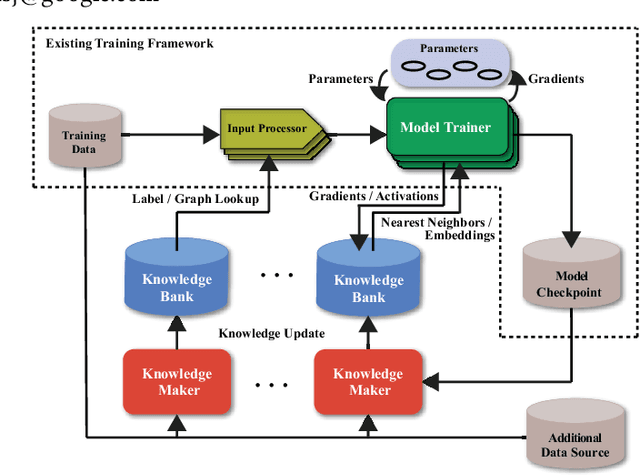
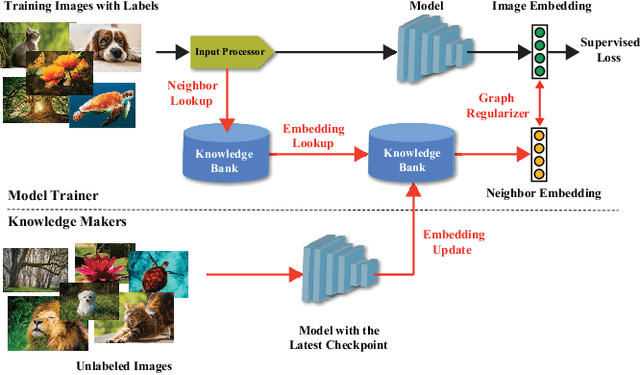
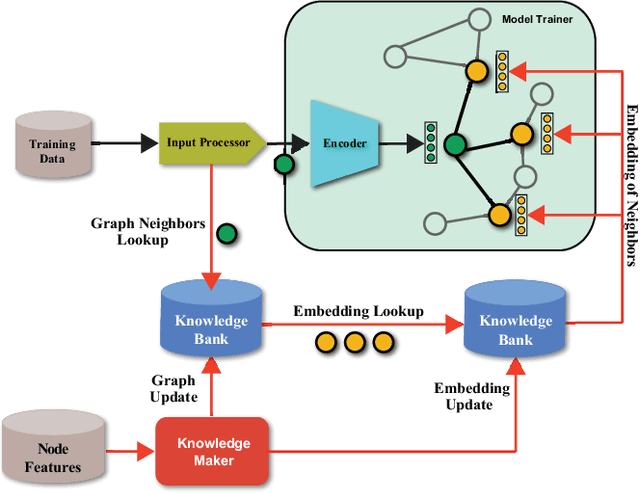
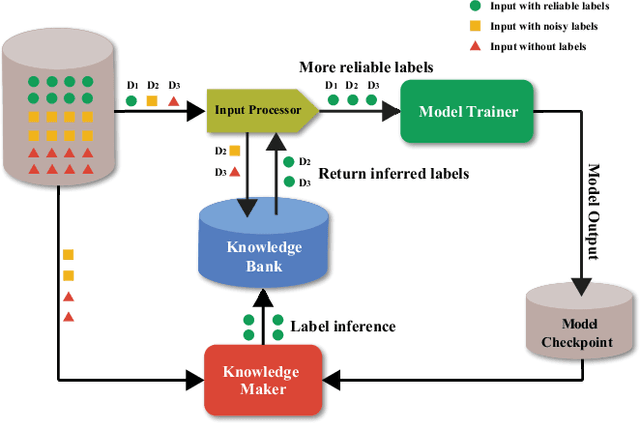
In this work, we propose CARLS, a novel framework for augmenting the capacity of existing deep learning frameworks by enabling multiple components -- model trainers, knowledge makers and knowledge banks -- to concertedly work together in an asynchronous fashion across hardware platforms. The proposed CARLS is particularly suitable for learning paradigms where model training benefits from additional knowledge inferred or discovered during training, such as node embeddings for graph neural networks or reliable pseudo labels from model predictions. We also describe three learning paradigms -- semi-supervised learning, curriculum learning and multimodal learning -- as examples that can be scaled up efficiently by CARLS. One version of CARLS has been open-sourced and available for download at: https://github.com/tensorflow/neural-structured-learning/tree/master/research/carls