 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Effect of Pretraining Label Granularity
Paper and Code
Mar 29, 2023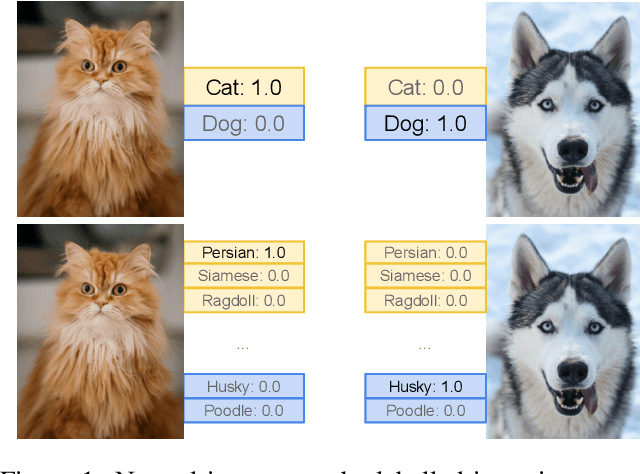
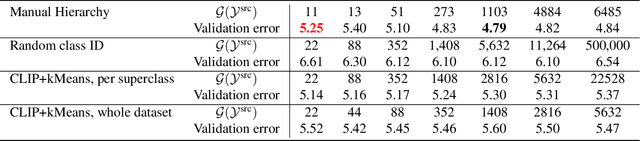
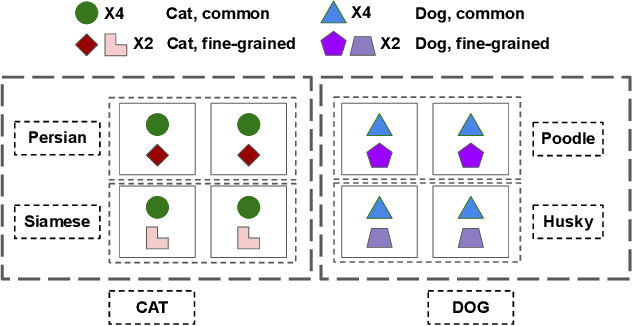
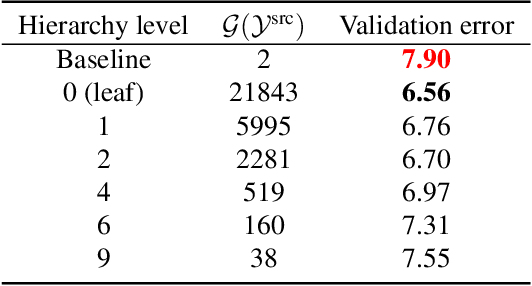
In this paper, we study how pretraining label granularity affects the generalization of deep neural networks in image classification tasks. We focus on the "fine-to-coarse" transfer learning setting where the pretraining label is more fine-grained than that of the target problem. We experiment with this method using the label hierarchy of iNaturalist 2021, and observe a 8.76% relative improvement of the error rate over the baseline. We find the following conditions are key for the improvement: 1) the pretraining dataset has a strong and meaningful label hierarchy, 2) its label function strongly aligns with that of the target task, and most importantly, 3) an appropriate level of pretraining label granularity is chosen. The importance of pretraining label granularity is further corroborated by our transfer learning experiments on ImageNet. Most notably, we show that pretraining at the leaf labels of ImageNet21k produces better transfer results on ImageNet1k than pretraining at other coarser granularity levels, which supports the common practice. Theoretically, through an analysis on a two-layer convolutional ReLU network, we prove that: 1) models trained on coarse-grained labels only respond strongly to the common or "easy-to-learn" features; 2) with the dataset satisfying the right conditions, fine-grained pretraining encourages the model to also learn rarer or "harder-to-learn" features well, thus improving the model's generalization.