 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transformers Solve Propositional Logic Problems: A Mechanistic Analysis
Nov 07, 2024



Large language models (LLMs) have shown amazing performance on tasks that require planning and reasoning. Motivated by this, we investigate the internal mechanisms that underpin a network's ability to perform complex logical reasoning. We first construct a synthetic propositional logic problem that serves as a concrete test-bed for network training and evaluation. Crucially, this problem demands nontrivial planning to solve, but we can train a small transformer to achieve perfect accuracy. Building on our set-up, we then pursue an understanding of precisely how a three-layer transformer, trained from scratch, solves this problem. We are able to identify certain "planning" and "reasoning" circuits in the network that necessitate cooperation between the attention blocks to implement the desired logic. To expand our findings, we then study a larger model, Mistral 7B. Using activation patching, we characterize internal components that are critical in solving our logic problem. Overall, our work systemically uncovers novel aspects of small and large transformers, and continues the study of how they plan and reason.
Why Fine-grained Labels in Pretraining Benefit Generalization?
Oct 30, 2024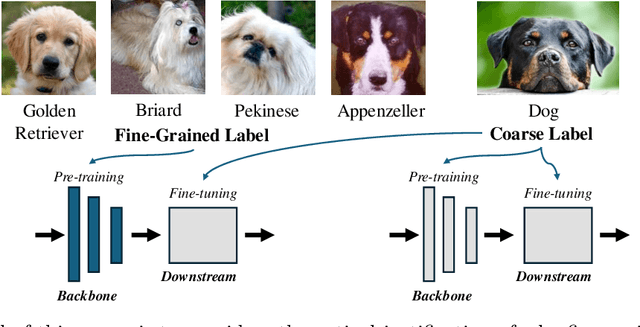

Recent studies show that pretraining a deep neural network with fine-grained labeled data, followed by fine-tuning on coarse-labeled data for downstream tasks, often yields better generalization than pretraining with coarse-labeled data. While there is ample empirical evidence supporting this, the theoretical justification remains an open problem. This paper addresses this gap by introducing a "hierarchical multi-view" structure to confine the input data distribution. Under this framework, we prove that: 1) coarse-grained pretraining only allows a neural network to learn the common features well, while 2) fine-grained pretraining helps the network learn the rare features in addition to the common ones, leading to improved accuracy on hard downstream test samples.
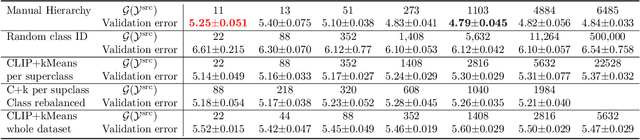
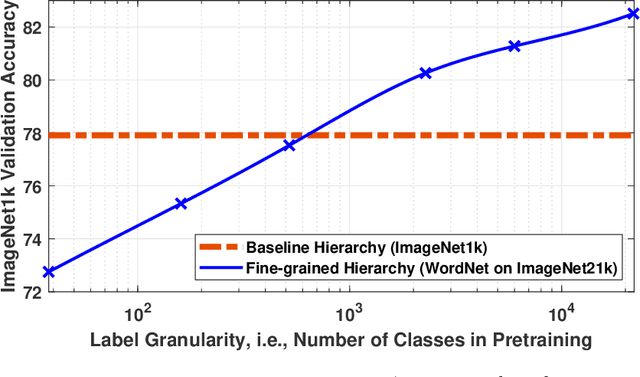
Towards Understanding the Effect of Pretraining Label Granularity
Mar 29, 2023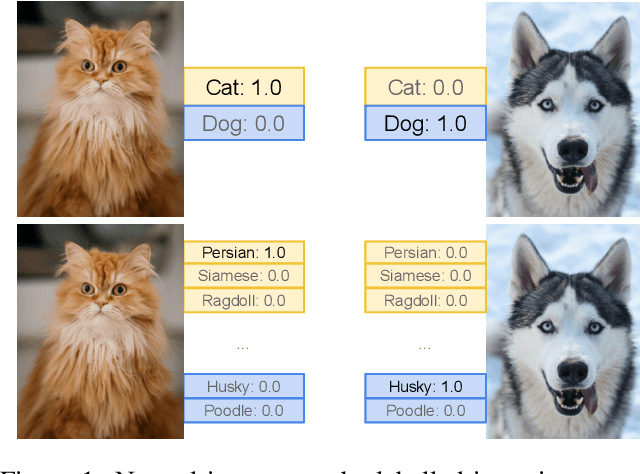
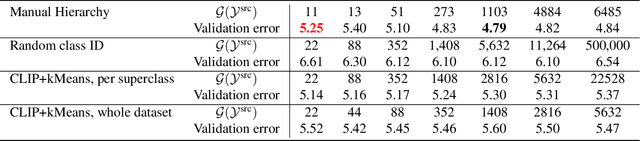
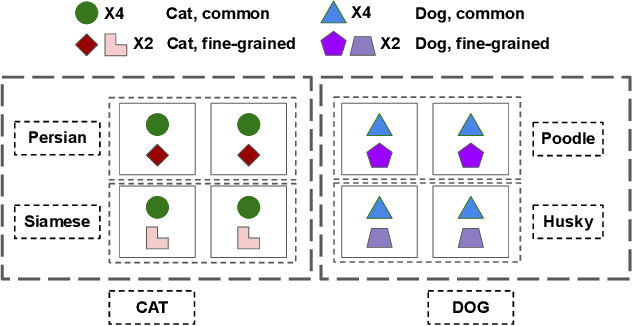
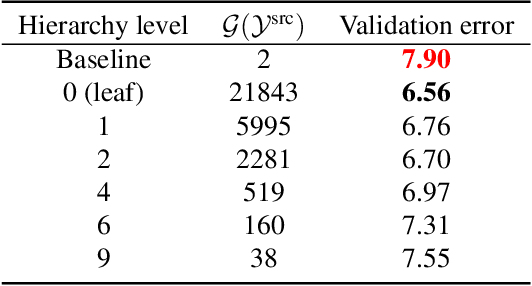
In this paper, we study how pretraining label granularity affects the generalization of deep neural networks in image classification tasks. We focus on the "fine-to-coarse" transfer learning setting where the pretraining label is more fine-grained than that of the target problem. We experiment with this method using the label hierarchy of iNaturalist 2021, and observe a 8.76% relative improvement of the error rate over the baseline. We find the following conditions are key for the improvement: 1) the pretraining dataset has a strong and meaningful label hierarchy, 2) its label function strongly aligns with that of the target task, and most importantly, 3) an appropriate level of pretraining label granularity is chosen. The importance of pretraining label granularity is further corroborated by our transfer learning experiments on ImageNet. Most notably, we show that pretraining at the leaf labels of ImageNet21k produces better transfer results on ImageNet1k than pretraining at other coarser granularity levels, which supports the common practice. Theoretically, through an analysis on a two-layer convolutional ReLU network, we prove that: 1) models trained on coarse-grained labels only respond strongly to the common or "easy-to-learn" features; 2) with the dataset satisfying the right conditions, fine-grained pretraining encourages the model to also learn rarer or "harder-to-learn" features well, thus improving the model's generalization.