 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Fine-grained Labels in Pretraining Benefit Generalization?
Oct 30, 2024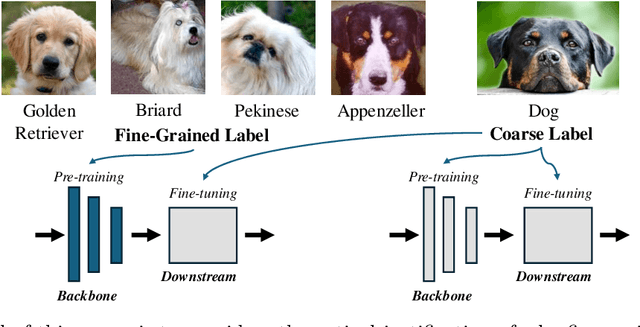
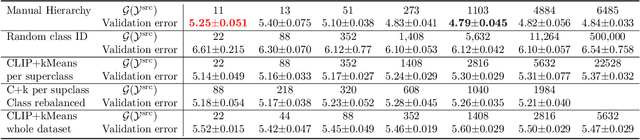
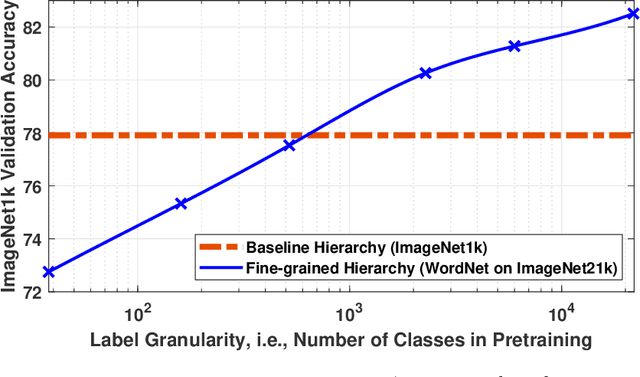

Recent studies show that pretraining a deep neural network with fine-grained labeled data, followed by fine-tuning on coarse-labeled data for downstream tasks, often yields better generalization than pretraining with coarse-labeled data. While there is ample empirical evidence supporting this, the theoretical justification remains an open problem. This paper addresses this gap by introducing a "hierarchical multi-view" structure to confine the input data distribution. Under this framework, we prove that: 1) coarse-grained pretraining only allows a neural network to learn the common features well, while 2) fine-grained pretraining helps the network learn the rare features in addition to the common ones, leading to improved accuracy on hard downstream test samples.