 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up LLM Reviews for Google Ads Content Moderation
Feb 07, 2024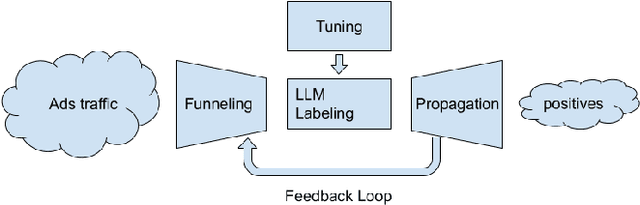
Large language models (LLMs) are powerful tools for content moderation, but their inference costs and latency make them prohibitive for casual use on large datasets, such as the Google Ads repository. This study proposes a method for scaling up LLM reviews for content moderation in Google Ads. First, we use heuristics to select candidates via filtering and duplicate removal, and create clusters of ads for which we select one representative ad per cluster. We then use LLMs to review only the representative ads. Finally, we propagate the LLM decisions for the representative ads back to their clusters. This method reduces the number of reviews by more than 3 orders of magnitude while achieving a 2x recall compared to a baseline non-LLM model. The success of this approach is a strong function of the representations used in clustering and label propagation; we found that cross-modal similarity representations yield better results than uni-modal representations.
DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data
Nov 27, 2022Generative adversarial nets (GANs) have been remarkably successful at learning to sample from distributions specified by a given dataset, particularly if the given dataset is reasonably large compared to its dimensionality. However, given limited data, classical GANs have struggled, and strategies like output-regularization, data-augmentation, use of pre-trained models and pruning have been shown to lead to improvements. Notably, the applicability of these strategies is 1) often constrained to particular settings, e.g., availability of a pretrained GAN; or 2) increases training time, e.g., when using pruning. In contrast, we propose a Discriminator gradIent Gap regularized GAN (DigGAN) formulation which can be added to any existing GAN. DigGAN augments existing GANs by encouraging to narrow the gap between the norm of the gradient of a discriminator's prediction w.r.t.\ real images and w.r.t.\ the generated samples. We observe this formulation to avoid bad attractors within the GAN loss landscape, and we find DigGAN to significantly improve the results of GAN training when limited data is available. Code is available at \url{https://github.com/AilsaF/DigGAN}.
Towards a Better Global Loss Landscape of GANs
Nov 10, 2020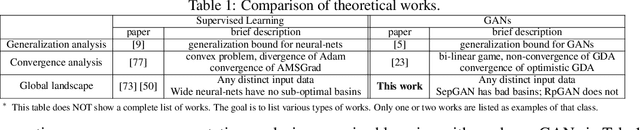
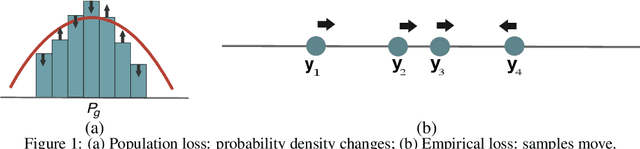
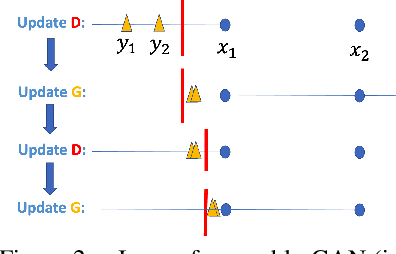
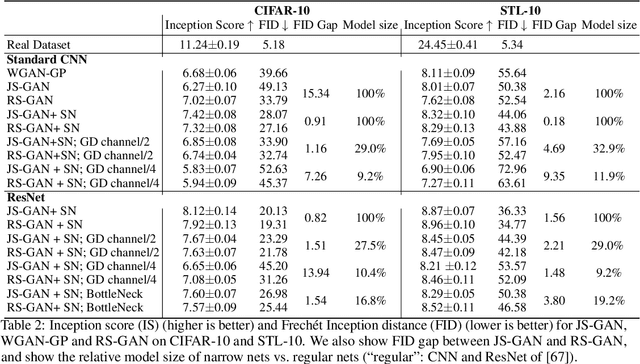
Understanding of GAN training is still very limited. One major challenge is its non-convex-non-concave min-max objective, which may lead to sub-optimal local minima. In this work, we perform a global landscape analysis of the empirical loss of GANs. We prove that a class of separable-GAN, including the original JS-GAN, has exponentially many bad basins which are perceived as mode-collapse. We also study the relativistic pairing GAN (RpGAN) loss which couples the generated samples and the true samples. We prove that RpGAN has no bad basins. Experiments on synthetic data show that the predicted bad basin can indeed appear in training. We also perform experiments to support our theory that RpGAN has a better landscape than separable-GAN. For instance, we empirically show that RpGAN performs better than separable-GAN with relatively narrow neural nets. The code is available at https://github.com/AilsaF/RS-GAN.
Co-Generation with GANs using AIS based HMC
Oct 31, 2019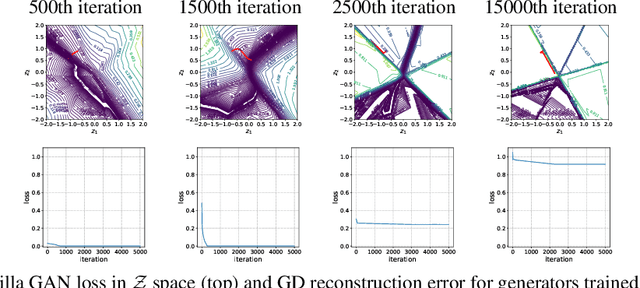
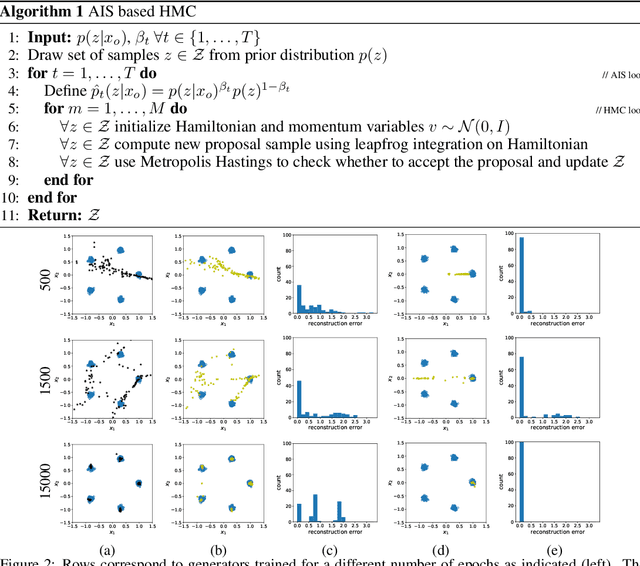
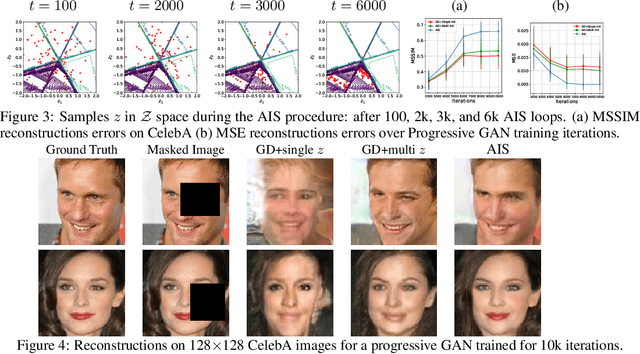

Inferring the most likely configuration for a subset of variables of a joint distribution given the remaining ones - which we refer to as co-generation - is an important challenge that is computationally demanding for all but the simplest settings. This task has received a considerable amount of attention, particularly for classical ways of modeling distributions like structured prediction. In contrast, almost nothing is known about this task when considering recently proposed techniques for modeling high-dimensional distributions, particularly generative adversarial nets (GANs). Therefore, in this paper, we study the occurring challenges for co-generation with GANs. To address those challenges we develop an annealed importance sampling based Hamiltonian Monte Carlo co-generation algorithm. The presented approach significantly outperforms classical gradient based methods on a synthetic and on the CelebA and LSUN datasets.