 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
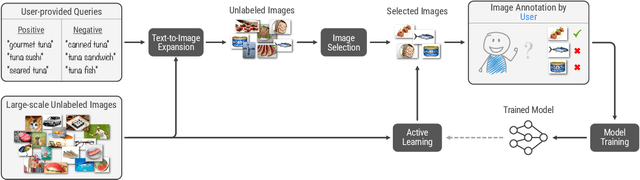
Mar 05, 2024From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.