 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Modeling Profiles instead of Values
Paper and Code
Jul 11, 2012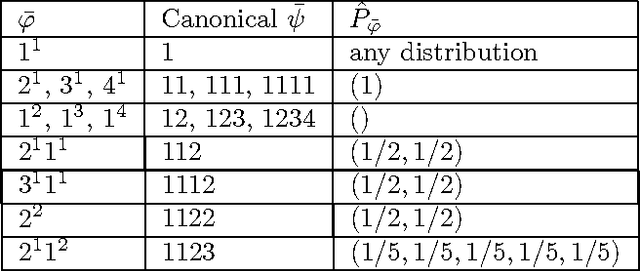
We consider the problem of estimating the distribution underlying an observed sample of data. Instead of maximum likelihood, which maximizes the probability of the ob served values, we propose a different estimate, the high-profile distribution, which maximizes the probability of the observed profile the number of symbols appearing any given number of times. We determine the high-profile distribution of several data samples, establish some of its general properties, and show that when the number of distinct symbols observed is small compared to the data size, the high-profile and maximum-likelihood distributions are roughly the same, but when the number of symbols is large, the distributions differ, and high-profile better explains the data.