 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Reading-Induced Confusion Using EEG and Eye Tracking
Aug 20, 2025



Humans regularly navigate an overwhelming amount of information via text media, whether reading articles, browsing social media, or interacting with chatbots. Confusion naturally arises when new information conflicts with or exceeds a reader's comprehension or prior knowledge, posing a challenge for learning. In this study, we present a multimodal investigation of reading-induced confusion using EEG and eye tracking. We collected neural and gaze data from 11 adult participants as they read short paragraphs sampled from diverse, real-world sources. By isolating the N400 event-related potential (ERP), a well-established neural marker of semantic incongruence, and integrating behavioral markers from eye tracking, we provide a detailed analysis of the neural and behavioral correlates of confusion during naturalistic reading. Using machine learning, we show that multimodal (EEG + eye tracking) models improve classification accuracy by 4-22% over unimodal baselines, reaching an average weighted participant accuracy of 77.3% and a best accuracy of 89.6%. Our results highlight the dominance of the brain's temporal regions in these neural signatures of confusion, suggesting avenues for wearable, low-electrode brain-computer interfaces (BCI) for real-time monitoring. These findings lay the foundation for developing adaptive systems that dynamically detect and respond to user confusion, with potential applications in personalized learning, human-computer interaction, and accessibility.
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Feb 23, 2016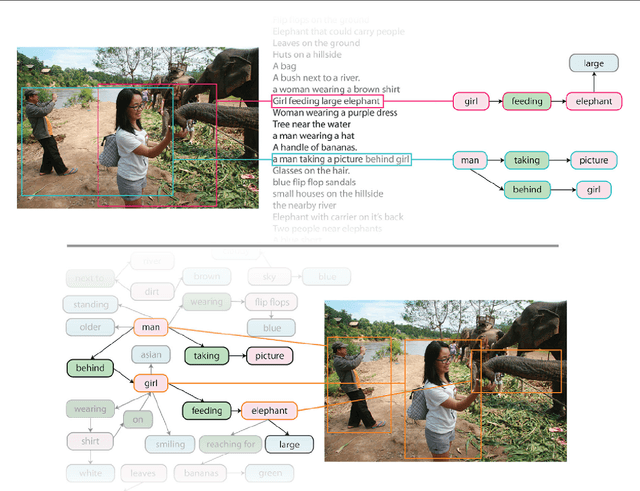
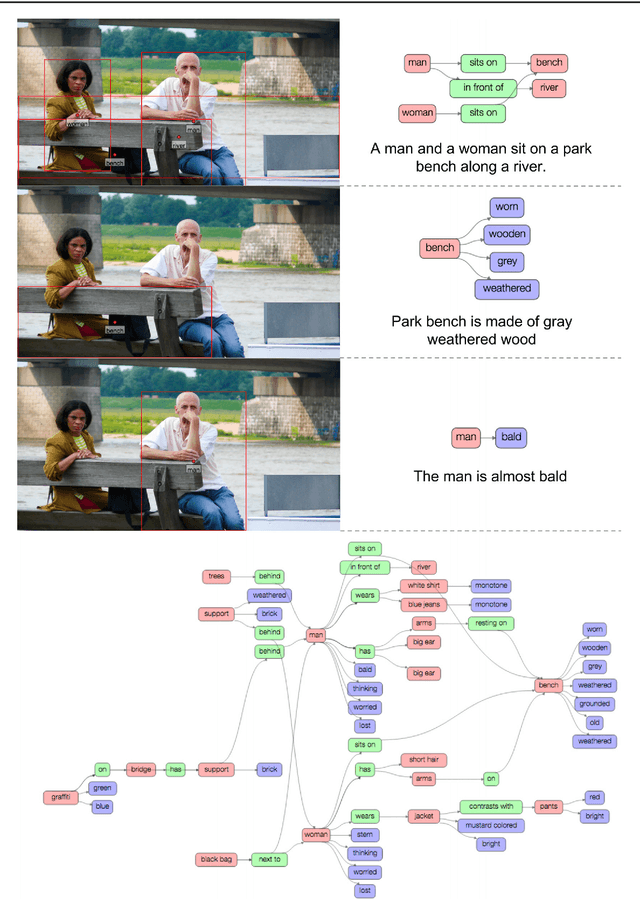

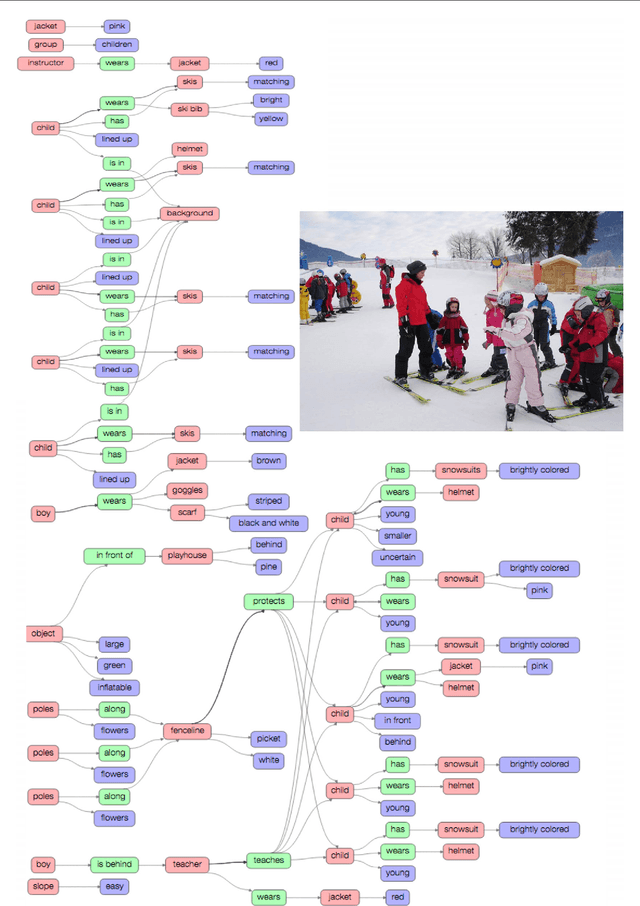
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked "What vehicle is the person riding?", computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) in order to answer correctly that "the person is riding a horse-drawn carriage". In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 100K images where each image has an average of 21 objects, 18 attributes, and 18 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answers.
Embracing Error to Enable Rapid Crowdsourcing
Feb 14, 2016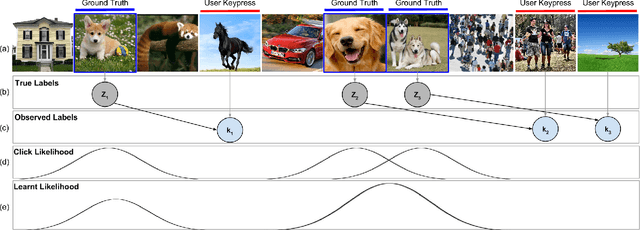


Microtask crowdsourcing has enabled dataset advances in social science and machine learning, but existing crowdsourcing schemes are too expensive to scale up with the expanding volume of data. To scale and widen the applicability of crowdsourcing, we present a technique that produces extremely rapid judgments for binary and categorical labels. Rather than punishing all errors, which causes workers to proceed slowly and deliberately, our technique speeds up workers' judgments to the point where errors are acceptable and even expected. We demonstrate that it is possible to rectify these errors by randomizing task order and modeling response latency. We evaluate our technique on a breadth of common labeling tasks such as image verification, word similarity, sentiment analysis and topic classification. Where prior work typically achieves a 0.25x to 1x speedup over fixed majority vote, our approach often achieves an order of magnitude (10x) speedup.