 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models in Medical Imaging -- A Review and Outlook
Jun 10, 2025Foundation models (FMs) are changing the way medical images are analyzed by learning from large collections of unlabeled data. Instead of relying on manually annotated examples, FMs are pre-trained to learn general-purpose visual features that can later be adapted to specific clinical tasks with little additional supervision. In this review, we examine how FMs are being developed and applied in pathology, radiology, and ophthalmology, drawing on evidence from over 150 studies. We explain the core components of FM pipelines, including model architectures, self-supervised learning methods, and strategies for downstream adaptation. We also review how FMs are being used in each imaging domain and compare design choices across applications. Finally, we discuss key challenges and open questions to guide future research.
ECTIL: Label-efficient Computational Tumour Infiltrating Lymphocyte (TIL) assessment in breast cancer: Multicentre validation in 2,340 patients with breast cancer
Jan 24, 2025



The level of tumour-infiltrating lymphocytes (TILs) is a prognostic factor for patients with (triple-negative) breast cancer (BC). Computational TIL assessment (CTA) has the potential to assist pathologists in this labour-intensive task, but current CTA models rely heavily on many detailed annotations. We propose and validate a fundamentally simpler deep learning based CTA that can be trained in only ten minutes on hundredfold fewer pathologist annotations. We collected whole slide images (WSIs) with TILs scores and clinical data of 2,340 patients with BC from six cohorts including three randomised clinical trials. Morphological features were extracted from whole slide images (WSIs) using a pathology foundation model. Our label-efficient Computational stromal TIL assessment model (ECTIL) directly regresses the TILs score from these features. ECTIL trained on only a few hundred samples (ECTIL-TCGA) showed concordance with the pathologist over five heterogeneous external cohorts (r=0.54-0.74, AUROC=0.80-0.94). Training on all slides of five cohorts (ECTIL-combined) improved results on a held-out test set (r=0.69, AUROC=0.85). Multivariable Cox regression analyses indicated that every 10% increase of ECTIL scores was associated with improved overall survival independent of clinicopathological variables (HR 0.86, p<0.01), similar to the pathologist score (HR 0.87, p<0.001). We demonstrate that ECTIL is highly concordant with an expert pathologist and obtains a similar hazard ratio. ECTIL has a fundamentally simpler design than existing methods and can be trained on orders of magnitude fewer annotations. Such a CTA may be used to pre-screen patients for, e.g., immunotherapy clinical trial inclusion, or as a tool to assist clinicians in the diagnostic work-up of patients with BC. Our model is available under an open source licence (https://github.com/nki-ai/ectil).
Sparse-Shot Learning for Extremely Many Localisations
Apr 21, 2021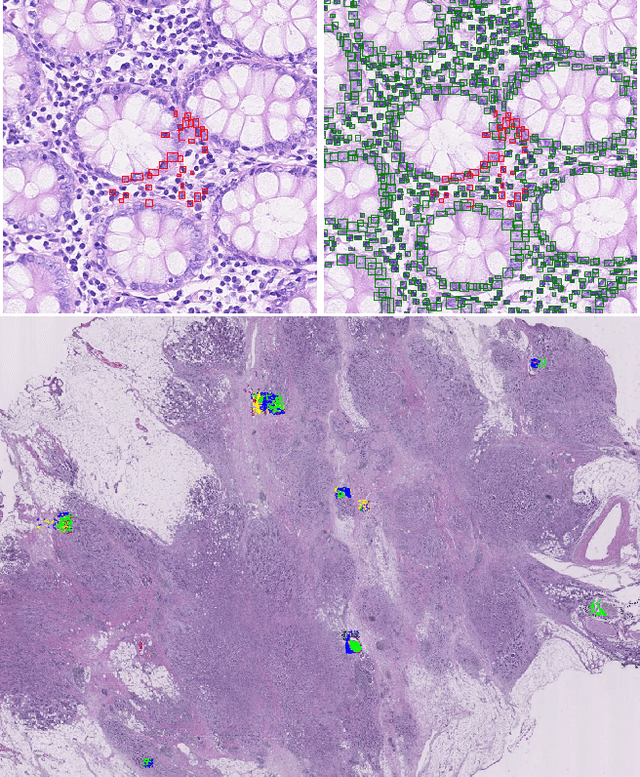

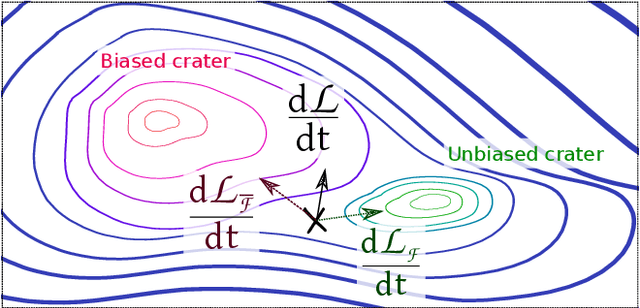
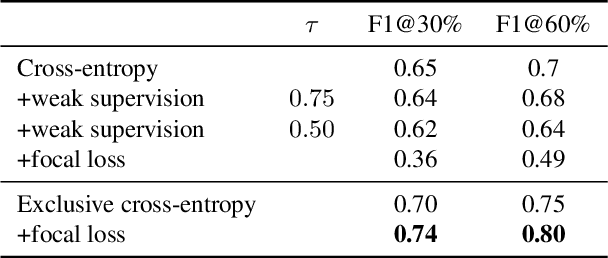
Object localisation is typically considered in the context of regular images, for instance depicting objects like people or cars. In these images there is typically a relatively small number of instances per image per class, which usually is manageable to annotate. However, outside the realm of regular images we are often confronted with a different situation. In computational pathology digitised tissue sections are extremely large images, whose dimensions quickly exceed 250'000x250'000 pixels, where relevant objects, such as tumour cells or lymphocytes can quickly number in the millions. Annotating them all is practically impossible and annotating sparsely a few, out of many more, is the only possibility. Unfortunately, learning from sparse annotations, or sparse-shot learning, clashes with standard supervised learning because what is not annotated is treated as a negative. However, assigning negative labels to what are true positives leads to confusion in the gradients and biased learning. To this end, we present exclusive cross entropy, which slows down the biased learning by examining the second-order loss derivatives in order to drop the loss terms corresponding to likely biased terms. Experiments on nine datasets and two different localisation tasks, detection with YOLLO and segmentation with Unet, show that we obtain considerable improvements compared to cross entropy or focal loss, while often reaching the best possible performance for the model with only 10-40 of annotations.