 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECTIL: Label-efficient Computational Tumour Infiltrating Lymphocyte (TIL) assessment in breast cancer: Multicentre validation in 2,340 patients with breast cancer
Jan 24, 2025



The level of tumour-infiltrating lymphocytes (TILs) is a prognostic factor for patients with (triple-negative) breast cancer (BC). Computational TIL assessment (CTA) has the potential to assist pathologists in this labour-intensive task, but current CTA models rely heavily on many detailed annotations. We propose and validate a fundamentally simpler deep learning based CTA that can be trained in only ten minutes on hundredfold fewer pathologist annotations. We collected whole slide images (WSIs) with TILs scores and clinical data of 2,340 patients with BC from six cohorts including three randomised clinical trials. Morphological features were extracted from whole slide images (WSIs) using a pathology foundation model. Our label-efficient Computational stromal TIL assessment model (ECTIL) directly regresses the TILs score from these features. ECTIL trained on only a few hundred samples (ECTIL-TCGA) showed concordance with the pathologist over five heterogeneous external cohorts (r=0.54-0.74, AUROC=0.80-0.94). Training on all slides of five cohorts (ECTIL-combined) improved results on a held-out test set (r=0.69, AUROC=0.85). Multivariable Cox regression analyses indicated that every 10% increase of ECTIL scores was associated with improved overall survival independent of clinicopathological variables (HR 0.86, p<0.01), similar to the pathologist score (HR 0.87, p<0.001). We demonstrate that ECTIL is highly concordant with an expert pathologist and obtains a similar hazard ratio. ECTIL has a fundamentally simpler design than existing methods and can be trained on orders of magnitude fewer annotations. Such a CTA may be used to pre-screen patients for, e.g., immunotherapy clinical trial inclusion, or as a tool to assist clinicians in the diagnostic work-up of patients with BC. Our model is available under an open source licence (https://github.com/nki-ai/ectil).
WeakSTIL: Weak whole-slide image level stromal tumor infiltrating lymphocyte scores are all you need
Sep 13, 2021
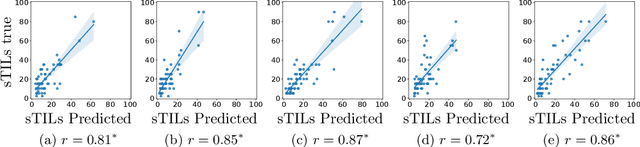
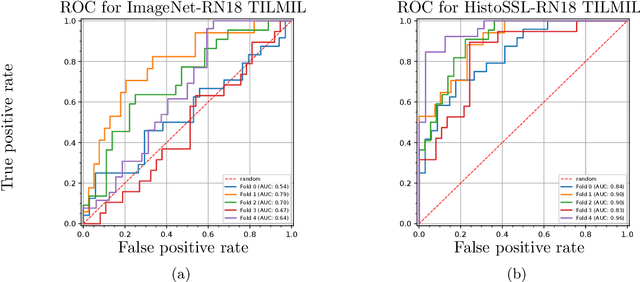
We present WeakSTIL, an interpretable two-stage weak label deep learning pipeline for scoring the percentage of stromal tumor infiltrating lymphocytes (sTIL%) in H&E-stained whole-slide images (WSIs) of breast cancer tissue. The sTIL% score is a prognostic and predictive biomarker for many solid tumor types. However, due to the high labeling efforts and high intra- and interobserver variability within and between expert annotators, this biomarker is currently not used in routine clinical decision making. WeakSTIL compresses tiles of a WSI using a feature extractor pre-trained with self-supervised learning on unlabeled histopathology data and learns to predict precise sTIL% scores for each tile in the tumor bed by using a multiple instance learning regressor that only requires a weak WSI-level label. By requiring only a weak label, we overcome the large annotation efforts required to train currently existing TIL detection methods. We show that WeakSTIL is at least as good as other TIL detection methods when predicting the WSI-level sTIL% score, reaching a coefficient of determination of $0.45\pm0.15$ when compared to scores generated by an expert pathologist, and an AUC of $0.89\pm0.05$ when treating it as the clinically interesting sTIL-high vs sTIL-low classification task. Additionally, we show that the intermediate tile-level predictions of WeakSTIL are highly interpretable, which suggests that WeakSTIL pays attention to latent features related to the number of TILs and the tissue type. In the future, WeakSTIL may be used to provide consistent and interpretable sTIL% predictions to stratify breast cancer patients into targeted therapy arms.
DeepSMILE: Self-supervised heterogeneity-aware multiple instance learning for DNA damage response defect classification directly from H&E whole-slide images
Jul 28, 2021

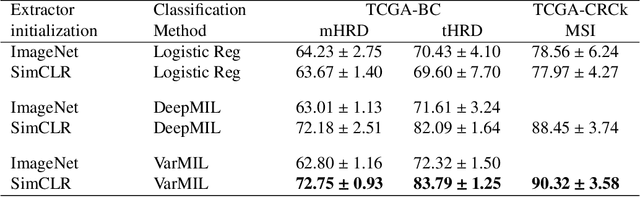
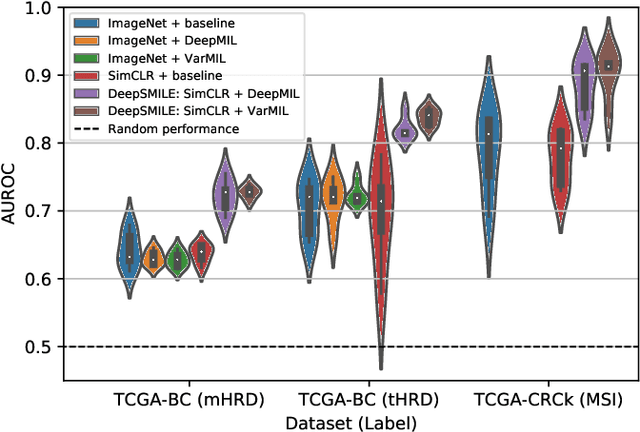
We propose a Deep learning-based weak label learning method for analysing whole slide images (WSIs) of Hematoxylin and Eosin (H&E) stained tumorcells not requiring pixel-level or tile-level annotations using Self-supervised pre-training and heterogeneity-aware deep Multiple Instance LEarning (DeepSMILE). We apply DeepSMILE to the task of Homologous recombination deficiency (HRD) and microsatellite instability (MSI) prediction. We utilize contrastive self-supervised learning to pre-train a feature extractor on histopathology tiles of cancer tissue. Additionally, we use variability-aware deep multiple instance learning to learn the tile feature aggregation function while modeling tumor heterogeneity. Compared to state-of-the-art genomic label classification methods, DeepSMILE improves classification performance for HRD from $70.43\pm4.10\%$ to $83.79\pm1.25\%$ AUC and MSI from $78.56\pm6.24\%$ to $90.32\pm3.58\%$ AUC in a multi-center breast and colorectal cancer dataset, respectively. These improvements suggest we can improve genomic label classification performance without collecting larger datasets. In the future, this may reduce the need for expensive genome sequencing techniques, provide personalized therapy recommendations based on widely available WSIs of cancer tissue, and improve patient care with quicker treatment decisions - also in medical centers without access to genome sequencing resources.