 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterMoE: Individual-Specific 3D Human Interaction Generation via Dynamic Temporal-Selective MoE
Nov 17, 2025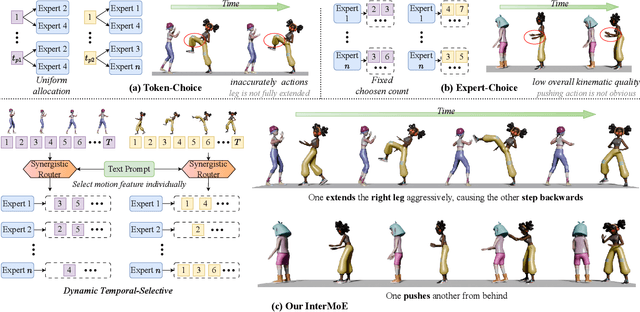
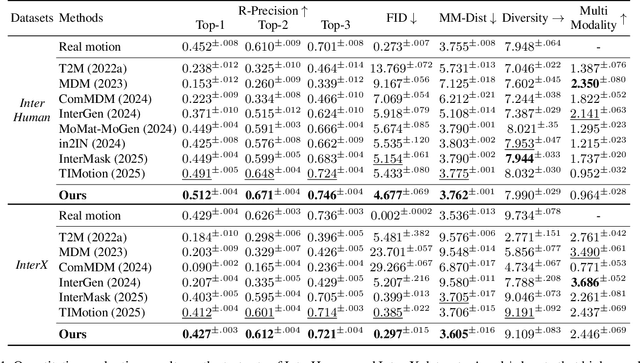
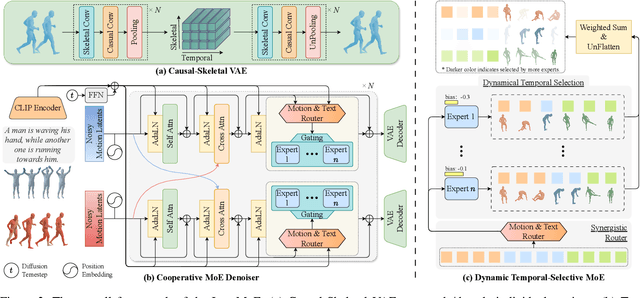
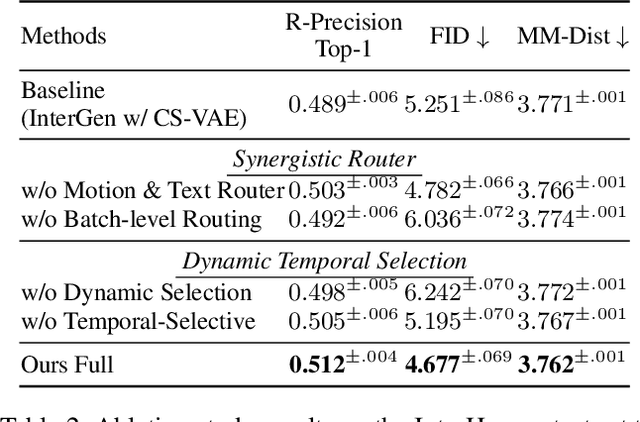
Generating high-quality human interactions holds significant value for applications like virtual reality and robotics. However, existing methods often fail to preserve unique individual characteristics or fully adhere to textual descriptions. To address these challenges, we introduce InterMoE, a novel framework built on a Dynamic Temporal-Selective Mixture of Experts. The core of InterMoE is a routing mechanism that synergistically uses both high-level text semantics and low-level motion context to dispatch temporal motion features to specialized experts. This allows experts to dynamically determine the selection capacity and focus on critical temporal features, thereby preserving specific individual characteristic identities while ensuring high semantic fidelity. Extensive experiments show that InterMoE achieves state-of-the-art performance in individual-specific high-fidelity 3D human interaction generation, reducing FID scores by 9% on the InterHuman dataset and 22% on InterX.
From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation
Apr 23, 2024Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask information from the reference human images, allowing for the precise selection of any part. Extensive experiments demonstrate the superiority of our approach over existing alternatives, offering advanced capabilities for multi-part controllable human image customization. See our project page at https://huanngzh.github.io/Parts2Whole/.
Towards Explainable 3D Grounded Visual Question Answering: A New Benchmark and Strong Baseline
Sep 24, 2022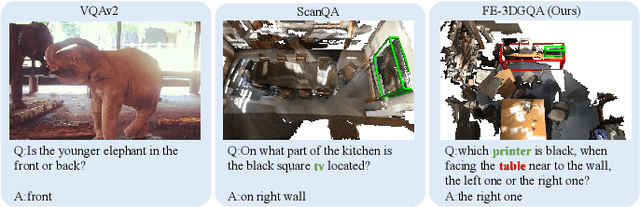
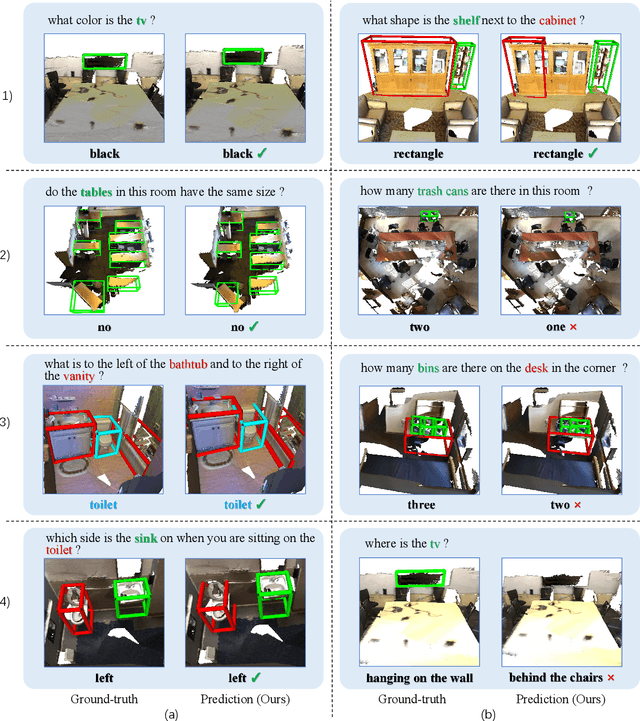
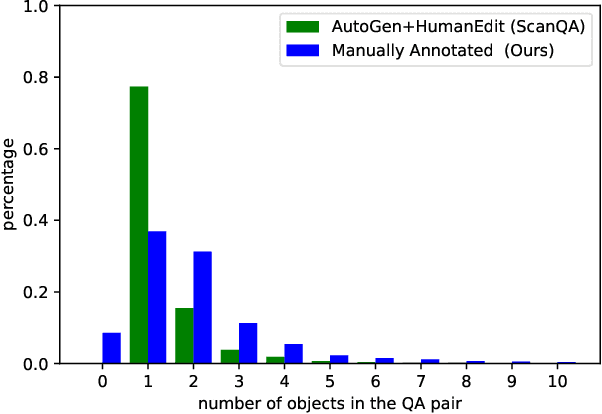

Recently, 3D vision-and-language tasks have attracted increasing research interest. Compared to other vision-and-language tasks, the 3D visual question answering (VQA) task is less exploited and is more susceptible to language priors and co-reference ambiguity. Meanwhile, a couple of recently proposed 3D VQA datasets do not well support 3D VQA task due to their limited scale and annotation methods. In this work, we formally define and address a 3D grounded VQA task by collecting a new 3D VQA dataset, referred to as FE-3DGQA, with diverse and relatively free-form question-answer pairs, as well as dense and completely grounded bounding box annotations. To achieve more explainable answers, we labelled the objects appeared in the complex QA pairs with different semantic types, including answer-grounded objects (both appeared and not appeared in the questions), and contextual objects for answer-grounded objects. We also propose a new 3D VQA framework to effectively predict the completely visually grounded and explainable answer. Extensive experiments verify that our newly collected benchmark datasets can be effectively used to evaluate various 3D VQA methods from different aspects and our newly proposed framework also achieves state-of-the-art performance on the new benchmark dataset. Both the newly collected dataset and our codes will be publicly available at http://github.com/zlccccc/3DGQA.
Sensoring and Application of Multimodal Data for the Detection of Freezing of Gait in Parkinson's Disease
Oct 09, 2021
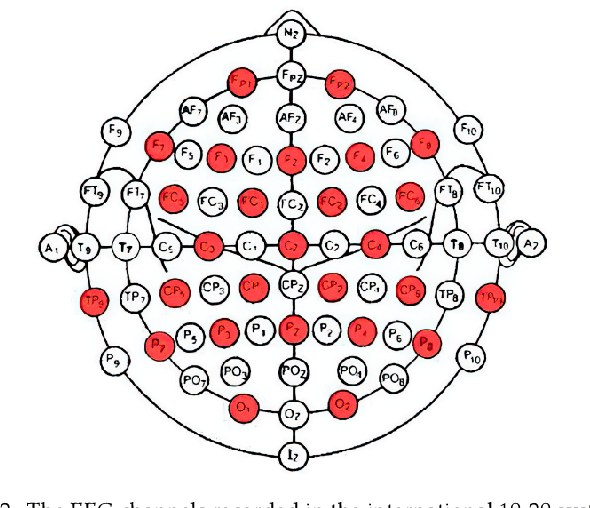

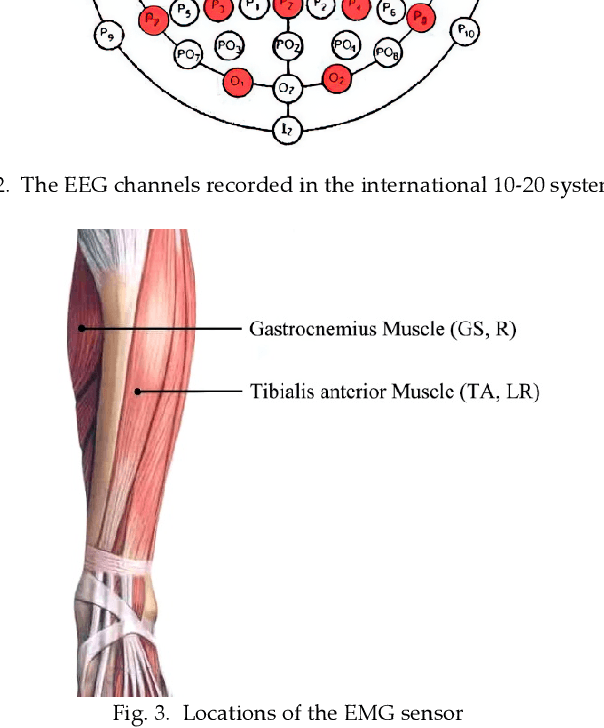
The accurate and reliable detection or prediction of freezing of gaits (FOG) is important for fall prevention in Parkinson's Disease (PD) and studying the physiological transitions during the occurrence of FOG. Integrating both commercial and self-designed sensors, a protocal has been designed to acquire multimodal physical and physiological information during FOG, including gait acceleration (ACC), electroencephalogram (EEG), electromyogram (EMG), and skin conductance (SC). Two tasks were designed to trigger FOG, including gait initiation failure and FOG during walking. A total number of 12 PD patients completed the experiments and produced a total length of 3 hours and 42 minutes of valid data. The FOG episodes were labeled by two qualified physicians. Each unimodal data and combinations have been used to detect FOG. Results showed that multimodal data benefit the detection of FOG. Among unimodal data, EEG had better discriminative ability than ACC and EMG. However, the acquisition of EEG are more complicated. Multimodal motional and electrophysiological data can also be used to study the physiological transition process during the occurrence of FOG and provide personalised interventions.