 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025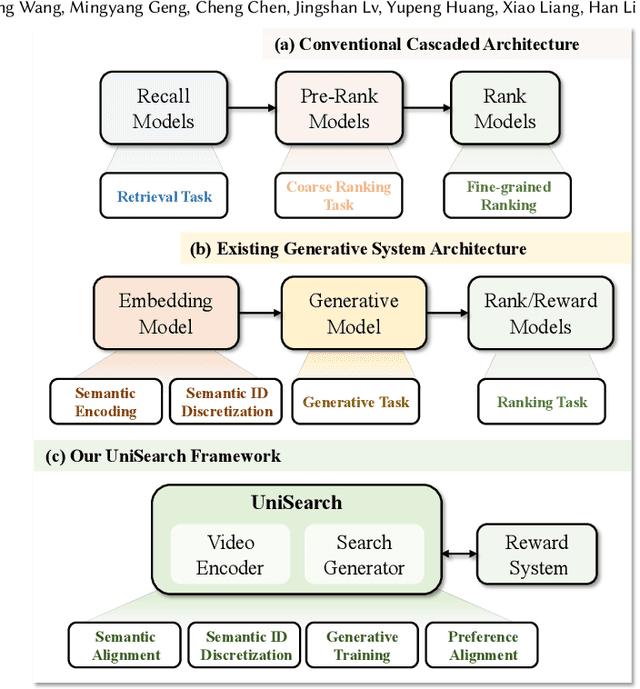
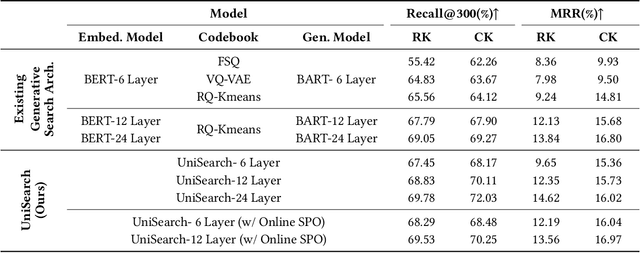
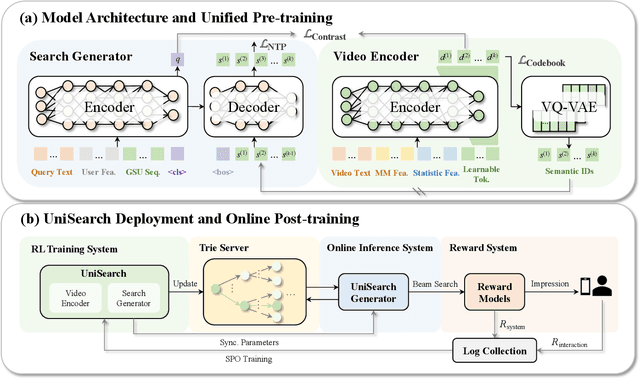
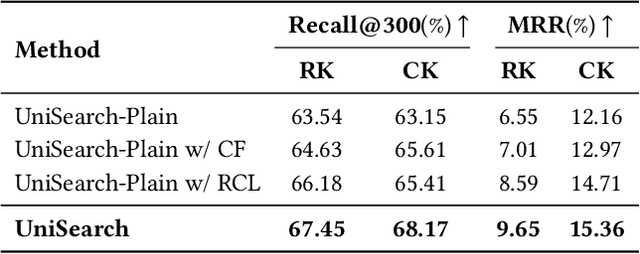
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Analytic Subspace Routing: How Recursive Least Squares Works in Continual Learning of Large Language Model
Mar 17, 2025



Large Language Models (LLMs) possess encompassing capabilities that can process diverse language-related tasks. However, finetuning on LLMs will diminish this general skills and continual finetuning will further cause severe degradation on accumulated knowledge. Recently, Continual Learning (CL) in Large Language Models (LLMs) arises which aims to continually adapt the LLMs to new tasks while maintaining previously learned knowledge and inheriting general skills. Existing techniques either leverage previous data to replay, leading to extra computational costs, or utilize a single parameter-efficient module to learn the downstream task, constraining new knowledge absorption with interference between different tasks. Toward these issues, this paper proposes Analytic Subspace Routing(ASR) to address these challenges. For each task, we isolate the learning within a subspace of deep layers' features via low-rank adaptation, eliminating knowledge interference between different tasks. Additionally, we propose an analytic routing mechanism to properly utilize knowledge learned in different subspaces. Our approach employs Recursive Least Squares to train a multi-task router model, allowing the router to dynamically adapt to incoming data without requiring access to historical data. Also, the router effectively assigns the current task to an appropriate subspace and has a non-forgetting property of previously learned tasks with a solid theoretical guarantee. Experimental results demonstrate that our method achieves near-perfect retention of prior knowledge while seamlessly integrating new information, effectively overcoming the core limitations of existing methods. Our code will be released after acceptance.
LLM4PR: Improving Post-Ranking in Search Engine with Large Language Models
Nov 02, 2024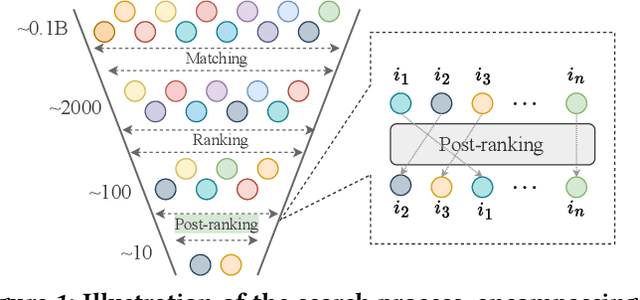



Alongside the rapid development of Large Language Models (LLMs), there has been a notable increase in efforts to integrate LLM techniques in information retrieval (IR) and search engines (SE). Recently, an additional post-ranking stage is suggested in SE to enhance user satisfaction in practical applications. Nevertheless, research dedicated to enhancing the post-ranking stage through LLMs remains largely unexplored. In this study, we introduce a novel paradigm named Large Language Models for Post-Ranking in search engine (LLM4PR), which leverages the capabilities of LLMs to accomplish the post-ranking task in SE. Concretely, a Query-Instructed Adapter (QIA) module is designed to derive the user/item representation vectors by incorporating their heterogeneous features. A feature adaptation step is further introduced to align the semantics of user/item representations with the LLM. Finally, the LLM4PR integrates a learning to post-rank step, leveraging both a main task and an auxiliary task to fine-tune the model to adapt the post-ranking task. Experiment studies demonstrate that the proposed framework leads to significant improvements and exhibits state-of-the-art performance compared with other alternatives.
Sensoring and Application of Multimodal Data for the Detection of Freezing of Gait in Parkinson's Disease
Oct 09, 2021
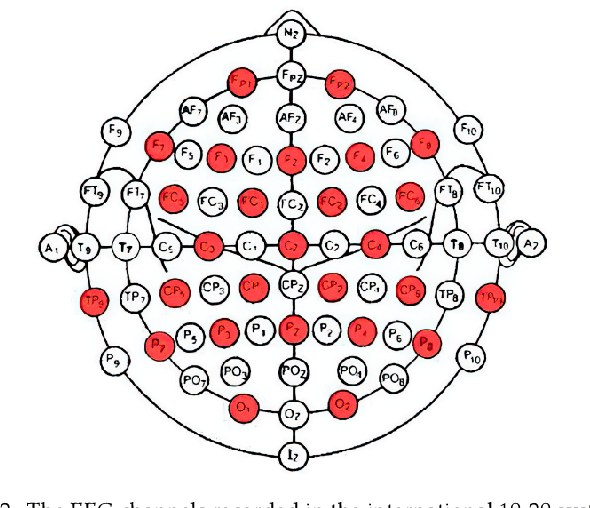

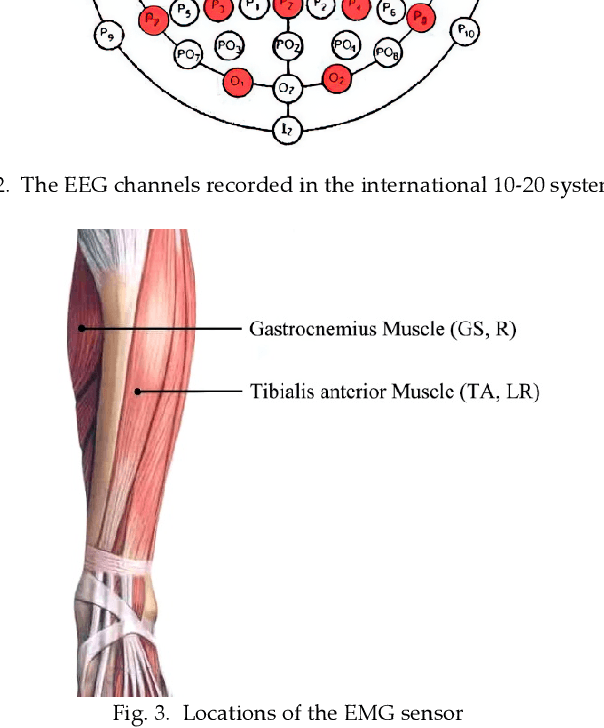
The accurate and reliable detection or prediction of freezing of gaits (FOG) is important for fall prevention in Parkinson's Disease (PD) and studying the physiological transitions during the occurrence of FOG. Integrating both commercial and self-designed sensors, a protocal has been designed to acquire multimodal physical and physiological information during FOG, including gait acceleration (ACC), electroencephalogram (EEG), electromyogram (EMG), and skin conductance (SC). Two tasks were designed to trigger FOG, including gait initiation failure and FOG during walking. A total number of 12 PD patients completed the experiments and produced a total length of 3 hours and 42 minutes of valid data. The FOG episodes were labeled by two qualified physicians. Each unimodal data and combinations have been used to detect FOG. Results showed that multimodal data benefit the detection of FOG. Among unimodal data, EEG had better discriminative ability than ACC and EMG. However, the acquisition of EEG are more complicated. Multimodal motional and electrophysiological data can also be used to study the physiological transition process during the occurrence of FOG and provide personalised interventions.
A New Modal Autoencoder for Functionally Independent Feature Extraction
Jun 25, 2020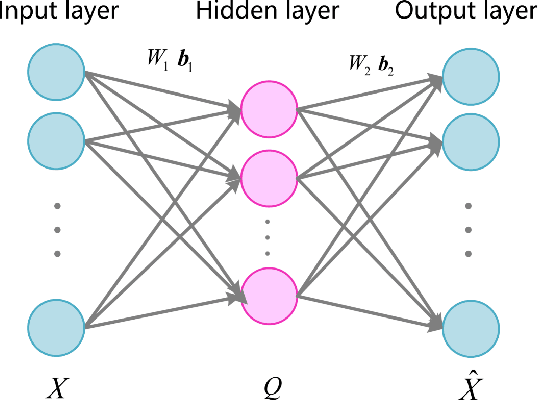
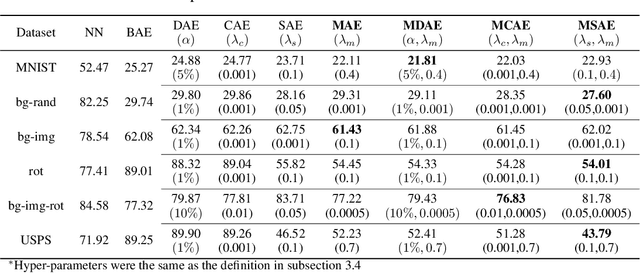
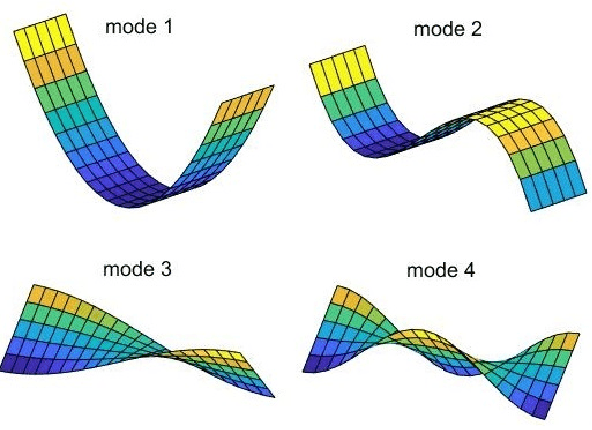
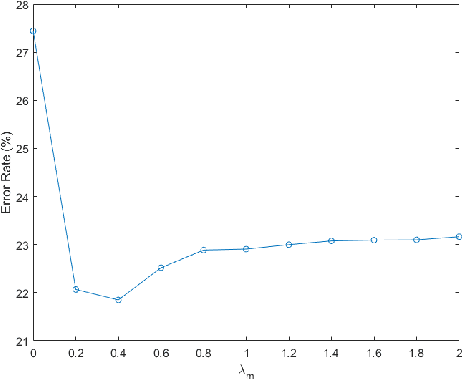
Autoencoders have been widely used for dimensional reduction and feature extraction. Various types of autoencoders have been proposed by introducing regularization terms. Most of these regularizations improve representation learning by constraining the weights in the encoder part, which maps input into hidden nodes and affects the generation of features. In this study, we show that a constraint to the decoder can also significantly improve its performance because the decoder determines how the latent variables contribute to the reconstruction of input. Inspired by the structural modal analysis method in mechanical engineering, a new modal autoencoder (MAE) is proposed by othogonalising the columns of the readout weight matrix. The new regularization helps to disentangle explanatory factors of variation and forces the MAE to extract fundamental modes in data. The learned representations are functionally independent in the reconstruction of input and perform better in consecutive classification tasks. The results were validated on the MNIST variations and USPS classification benchmark suite. Comparative experiments clearly show that the new algorithm has a surprising advantage. The new MAE introduces a very simple training principle for autoencoders and could be promising for the pre-training of deep neural networks.