 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Modal Autoencoder for Functionally Independent Feature Extraction
Jun 25, 2020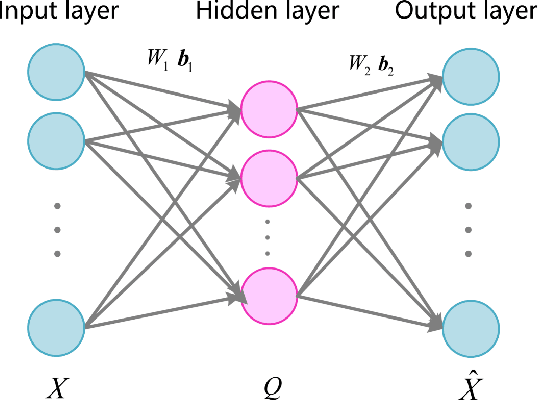
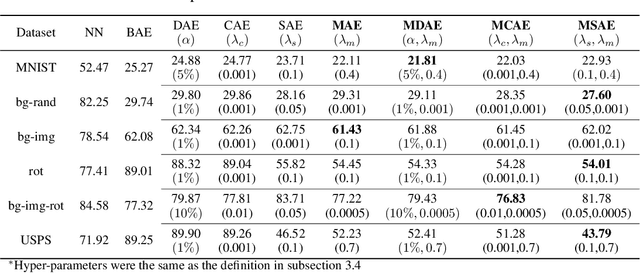
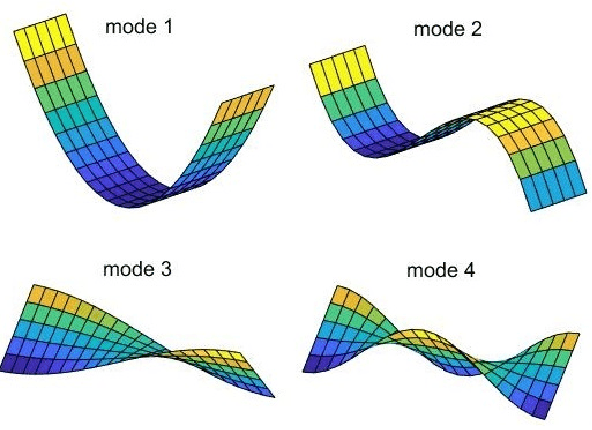
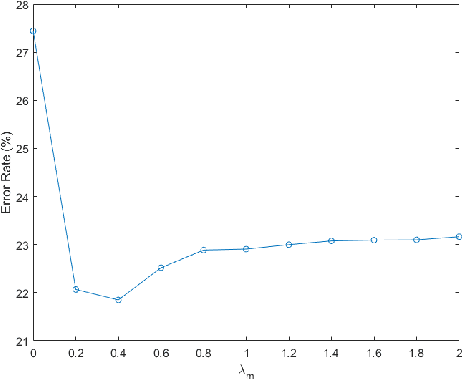
Autoencoders have been widely used for dimensional reduction and feature extraction. Various types of autoencoders have been proposed by introducing regularization terms. Most of these regularizations improve representation learning by constraining the weights in the encoder part, which maps input into hidden nodes and affects the generation of features. In this study, we show that a constraint to the decoder can also significantly improve its performance because the decoder determines how the latent variables contribute to the reconstruction of input. Inspired by the structural modal analysis method in mechanical engineering, a new modal autoencoder (MAE) is proposed by othogonalising the columns of the readout weight matrix. The new regularization helps to disentangle explanatory factors of variation and forces the MAE to extract fundamental modes in data. The learned representations are functionally independent in the reconstruction of input and perform better in consecutive classification tasks. The results were validated on the MNIST variations and USPS classification benchmark suite. Comparative experiments clearly show that the new algorithm has a surprising advantage. The new MAE introduces a very simple training principle for autoencoders and could be promising for the pre-training of deep neural networks.