 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
Cleansing the Artificial Mind: A Self-Reflective Detoxification Framework for Large Language Models
Jan 16, 2026Recent breakthroughs in Large Language Models (LLMs) have revealed remarkable generative capabilities and emerging self-regulatory mechanisms, including self-correction and self-rewarding. However, current detoxification techniques rarely exploit these built-in abilities; instead, they rely on external modules, labor-intensive data annotation, or human intervention --factors that hinder scalability and consistency. In this paper, we introduce a fully self-reflective detoxification framework that harnesses the inherent capacities of LLMs to detect, correct toxic content, and refine LLMs without external modules and data annotation. Specifically, we propose a Toxic Signal Detector --an internal self-identification mechanism, coupled with a systematic intervention process to transform toxic text into its non-toxic counterpart. This iterative procedure yields a contrastive detoxification dataset used to fine-tune the model, enhancing its ability for safe and coherent text generation. Experiments on benchmark datasets such as DetoxLLM and ParaDetox show that our method achieves better detoxification performance than state-of-the-art methods while preserving semantic fidelity. By obviating the need for human intervention or external components, this paper reveals the intrinsic self-detoxification ability of LLMs, offering a consistent and effective approach for mitigating harmful content generation. Ultimately, our findings underscore the potential for truly self-regulated language models, paving the way for more responsible and ethically guided text generation systems.
Improved AutoEncoder with LSTM module and KL divergence
Apr 30, 2024The task of anomaly detection is to separate anomalous data from normal data in the dataset. Models such as deep convolutional autoencoder (CAE) network and deep supporting vector data description (SVDD) model have been universally employed and have demonstrated significant success in detecting anomalies. However, the over-reconstruction ability of CAE network for anomalous data can easily lead to high false negative rate in detecting anomalous data. On the other hand, the deep SVDD model has the drawback of feature collapse, which leads to a decrease of detection accuracy for anomalies. To address these problems, we propose the Improved AutoEncoder with LSTM module and Kullback-Leibler divergence (IAE-LSTM-KL) model in this paper. An LSTM network is added after the encoder to memorize feature representations of normal data. In the meanwhile, the phenomenon of feature collapse can also be mitigated by penalizing the featured input to SVDD module via KL divergence. The efficacy of the IAE-LSTM-KL model is validated through experiments on both synthetic and real-world datasets. Experimental results show that IAE-LSTM-KL model yields higher detection accuracy for anomalies. In addition, it is also found that the IAE-LSTM-KL model demonstrates enhanced robustness to contaminated outliers in the dataset.
A Demographic Attribute Guided Approach to Age Estimation
May 20, 2022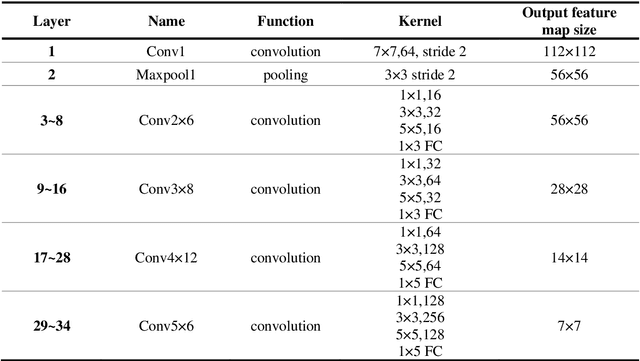
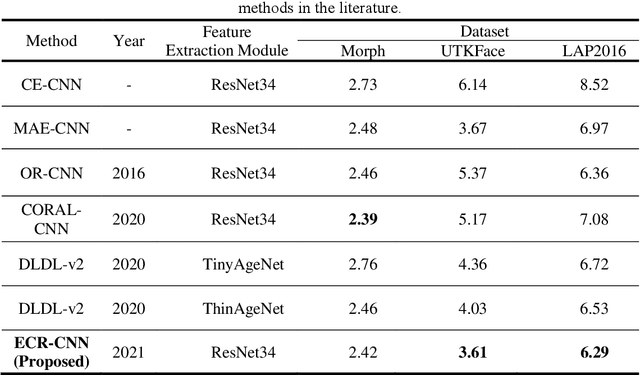
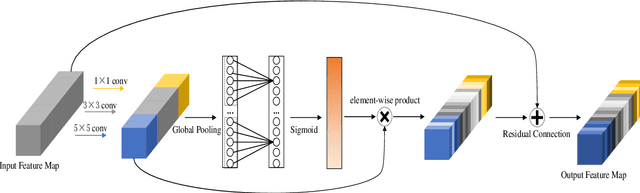
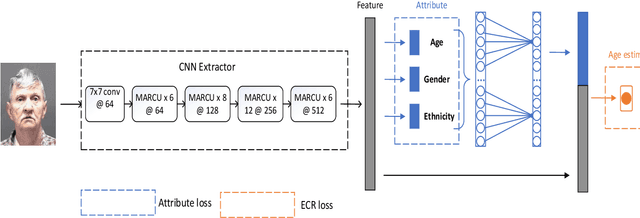
Face-based age estimation has attracted enormous attention due to wide applications to public security surveillance, human-computer interaction, etc. With vigorous development of deep learning, age estimation based on deep neural network has become the mainstream practice. However, seeking a more suitable problem paradigm for age change characteristics, designing the corresponding loss function and designing a more effective feature extraction module still needs to be studied. What is more, change of face age is also related to demographic attributes such as ethnicity and gender, and the dynamics of different age groups is also quite different. This problem has so far not been paid enough attention to. How to use demographic attribute information to improve the performance of age estimation remains to be further explored. In light of these issues, this research makes full use of auxiliary information of face attributes and proposes a new age estimation approach with an attribute guidance module. We first design a multi-scale attention residual convolution unit (MARCU) to extract robust facial features other than simply using other standard feature modules such as VGG and ResNet. Then, after being especially treated through full connection (FC) layers, the facial demographic attributes are weight-summed by 1*1 convolutional layer and eventually merged with the age features by a global FC layer. Lastly, we propose a new error compression ranking (ECR) loss to better converge the age regression value. Experimental results on three public datasets of UTKFace, LAP2016 and Morph show that our proposed approach achieves superior performance compared to other state-of-the-art methods.