 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEPTHOR: Depth Enhancement from a Practical Light-Weight dToF Sensor and RGB Image
Apr 02, 2025Depth enhancement, which uses RGB images as guidance to convert raw signals from dToF into high-precision, dense depth maps, is a critical task in computer vision. Although existing super-resolution-based methods show promising results on public datasets, they often rely on idealized assumptions like accurate region correspondences and reliable dToF inputs, overlooking calibration errors that cause misalignment and anomaly signals inherent to dToF imaging, limiting real-world applicability. To address these challenges, we propose a novel completion-based method, named DEPTHOR, featuring advances in both the training strategy and model architecture. First, we propose a method to simulate real-world dToF data from the accurate ground truth in synthetic datasets to enable noise-robust training. Second, we design a novel network that incorporates monocular depth estimation (MDE), leveraging global depth relationships and contextual information to improve prediction in challenging regions. On the ZJU-L5 dataset, our training strategy significantly enhances depth completion models, achieving results comparable to depth super-resolution methods, while our model achieves state-of-the-art results, improving Rel and RMSE by 27% and 18%, respectively. On a more challenging set of dToF samples we collected, our method outperforms SOTA methods on preliminary stereo-based GT, improving Rel and RMSE by 23% and 22%, respectively. Our Code is available at https://github.com/ShadowBbBb/Depthor
SVDC: Consistent Direct Time-of-Flight Video Depth Completion with Frequency Selective Fusion
Mar 03, 2025Lightweight direct Time-of-Flight (dToF) sensors are ideal for 3D sensing on mobile devices. However, due to the manufacturing constraints of compact devices and the inherent physical principles of imaging, dToF depth maps are sparse and noisy. In this paper, we propose a novel video depth completion method, called SVDC, by fusing the sparse dToF data with the corresponding RGB guidance. Our method employs a multi-frame fusion scheme to mitigate the spatial ambiguity resulting from the sparse dToF imaging. Misalignment between consecutive frames during multi-frame fusion could cause blending between object edges and the background, which results in a loss of detail. To address this, we introduce an adaptive frequency selective fusion (AFSF) module, which automatically selects convolution kernel sizes to fuse multi-frame features. Our AFSF utilizes a channel-spatial enhancement attention (CSEA) module to enhance features and generates an attention map as fusion weights. The AFSF ensures edge detail recovery while suppressing high-frequency noise in smooth regions. To further enhance temporal consistency, We propose a cross-window consistency loss to ensure consistent predictions across different windows, effectively reducing flickering. Our proposed SVDC achieves optimal accuracy and consistency on the TartanAir and Dynamic Replica datasets. Code is available at https://github.com/Lan1eve/SVDC.
Graph Feedback Bandits on Similar Arms: With and Without Graph Structures
Jan 24, 2025
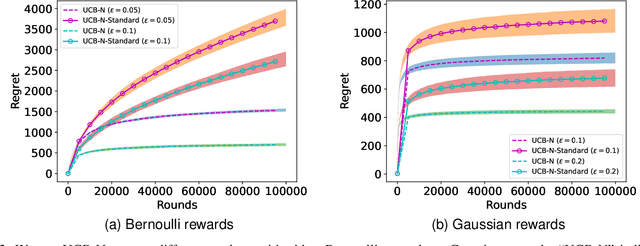
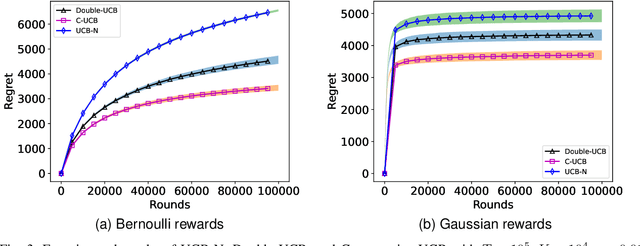

In this paper, we study the stochastic multi-armed bandit problem with graph feedback. Motivated by applications in clinical trials and recommendation systems, we assume that two arms are connected if and only if they are similar (i.e., their means are close to each other). We establish a regret lower bound for this problem under the novel feedback structure and introduce two upper confidence bound (UCB)-based algorithms: Double-UCB, which has problem-independent regret upper bounds, and Conservative-UCB, which has problem-dependent upper bounds. Leveraging the similarity structure, we also explore a scenario where the number of arms increases over time (referred to as the \emph{ballooning setting}). Practical applications of this scenario include Q\&A platforms (e.g., Reddit, Stack Overflow, Quora) and product reviews on platforms like Amazon and Flipkart, where answers (or reviews) continuously appear, and the goal is to display the best ones at the top. We extend these two UCB-based algorithms to the ballooning setting. Under mild assumptions, we provide regret upper bounds for both algorithms and discuss their sub-linearity. Furthermore, we propose a new version of the corresponding algorithms that do not rely on prior knowledge of the graph's structural information and provide regret upper bounds. Finally, we conduct experiments to validate the theoretical results.
DMSD-CDFSAR: Distillation from Mixed-Source Domain for Cross-Domain Few-shot Action Recognition
Jul 08, 2024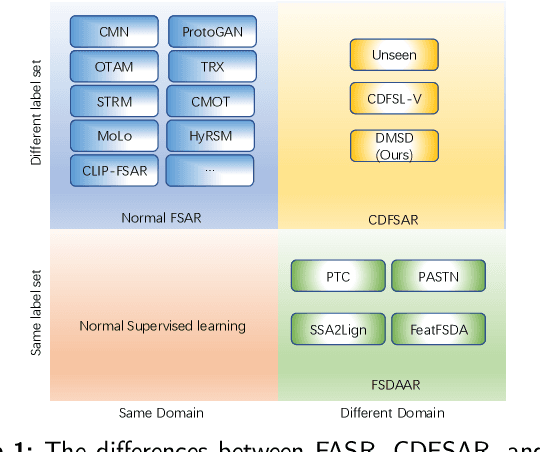
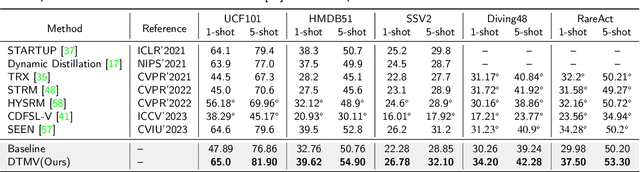
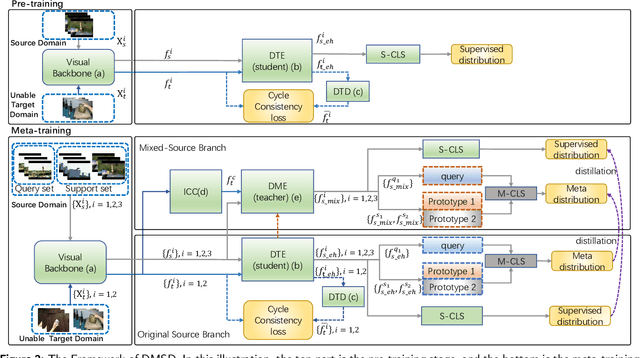

Few-shot action recognition is an emerging field in computer vision, primarily focused on meta-learning within the same domain. However, challenges arise in real-world scenario deployment, as gathering extensive labeled data within a specific domain is laborious and time-intensive. Thus, attention shifts towards cross-domain few-shot action recognition, requiring the model to generalize across domains with significant deviations. Therefore, we propose a novel approach, ``Distillation from Mixed-Source Domain", tailored to address this conundrum. Our method strategically integrates insights from both labeled data of the source domain and unlabeled data of the target domain during the training. The ResNet18 is used as the backbone to extract spatial features from the source and target domains. We design two branches for meta-training: the original-source and the mixed-source branches. In the first branch, a Domain Temporal Encoder is employed to capture temporal features for both the source and target domains. Additionally, a Domain Temporal Decoder is employed to reconstruct all extracted features. In the other branch, a Domain Mixed Encoder is used to handle labeled source domain data and unlabeled target domain data, generating mixed-source domain features. We incorporate a pre-training stage before meta-training, featuring a network architecture similar to that of the first branch. Lastly, we introduce a dual distillation mechanism to refine the classification probabilities of source domain features, aligning them with those of mixed-source domain features. This iterative process enriches the insights of the original-source branch with knowledge from the mixed-source branch, thereby enhancing the model's generalization capabilities. Our code is available at URL: \url{https://xxxx/xxxx/xxxx.git}
Multi-view Distillation based on Multi-modal Fusion for Few-shot Action Recognition
Jan 16, 2024In recent years, few-shot action recognition has attracted increasing attention. It generally adopts the paradigm of meta-learning. In this field, overcoming the overlapping distribution of classes and outliers is still a challenging problem based on limited samples. We believe the combination of Multi-modal and Multi-view can improve this issue depending on information complementarity. Therefore, we propose a method of Multi-view Distillation based on Multi-modal Fusion. Firstly, a Probability Prompt Selector for the query is constructed to generate probability prompt embedding based on the comparison score between the prompt embeddings of the support and the visual embedding of the query. Secondly, we establish a Multi-view. In each view, we fuse the prompt embedding as consistent information with visual and the global or local temporal context to overcome the overlapping distribution of classes and outliers. Thirdly, we perform the distance fusion for the Multi-view and the mutual distillation of matching ability from one to another, enabling the model to be more robust to the distribution bias. Our code is available at the URL: \url{https://github.com/cofly2014/MDMF}.
Forced Exploration in Bandit Problems
Dec 13, 2023
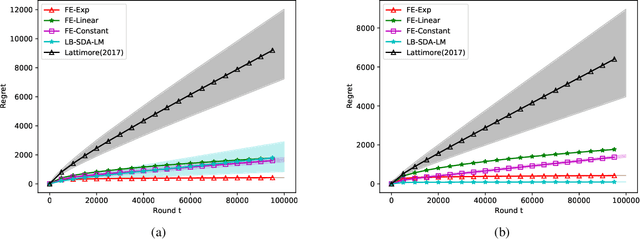
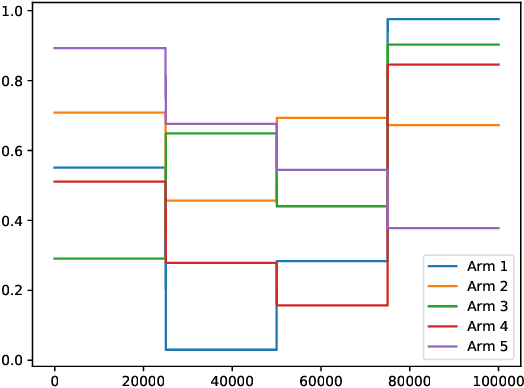
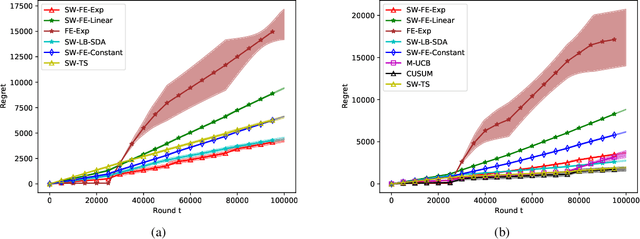
The multi-armed bandit(MAB) is a classical sequential decision problem. Most work requires assumptions about the reward distribution (e.g., bounded), while practitioners may have difficulty obtaining information about these distributions to design models for their problems, especially in non-stationary MAB problems. This paper aims to design a multi-armed bandit algorithm that can be implemented without using information about the reward distribution while still achieving substantial regret upper bounds. To this end, we propose a novel algorithm alternating between greedy rule and forced exploration. Our method can be applied to Gaussian, Bernoulli and other subgaussian distributions, and its implementation does not require additional information. We employ a unified analysis method for different forced exploration strategies and provide problem-dependent regret upper bounds for stationary and piecewise-stationary settings. Furthermore, we compare our algorithm with popular bandit algorithms on different reward distributions.
Consistency Prototype Module and Motion Compensation for Few-Shot Action Recognition (CLIP-CP$\mathbf{M^2}$C)
Dec 02, 2023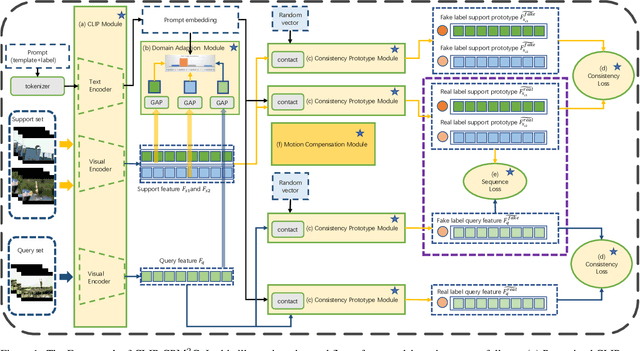



Recently, few-shot action recognition has significantly progressed by learning the feature discriminability and designing suitable comparison methods. Still, there are the following restrictions. (a) Previous works are mainly based on visual mono-modal. Although some multi-modal works use labels as supplementary to construct prototypes of support videos, they can not use this information for query videos. The labels are not used efficiently. (b) Most of the works ignore the motion feature of video, although the motion features are essential for distinguishing. We proposed a Consistency Prototype and Motion Compensation Network(CLIP-CP$M^2$C) to address these issues. Firstly, we use the CLIP for multi-modal few-shot action recognition with the text-image comparison for domain adaption. Secondly, in order to make the amount of information between the prototype and the query more similar, we propose a novel method to compensate for the text(prompt) information of query videos when text(prompt) does not exist, which depends on a Consistency Loss. Thirdly, we use the differential features of the adjacent frames in two directions as the motion features, which explicitly embeds the network with motion dynamics. We also apply the Consistency Loss to the motion features. Extensive experiments on standard benchmark datasets demonstrate that the proposed method can compete with state-of-the-art results. Our code is available at the URL: https://github.com/xxx/xxx.git.
Task-Specific Alignment and Multiple Level Transformer for Few-Shot Action Recognition
Jul 05, 2023



In the research field of few-shot learning, the main difference between image-based and video-based is the additional temporal dimension for videos. In recent years, many approaches for few-shot action recognition have followed the metric-based methods, especially, since some works use the Transformer to get the cross-attention feature of the videos or the enhanced prototype, and the results are competitive. However, they do not mine enough information from the Transformer because they only focus on the feature of a single level. In our paper, we have addressed this problem. We propose an end-to-end method named "Task-Specific Alignment and Multiple Level Transformer Network (TSA-MLT)". In our model, the Multiple Level Transformer focuses on the multiple-level feature of the support video and query video. Especially before Multiple Level Transformer, we use task-specific TSA to filter unimportant or misleading frames as a pre-processing. Furthermore, we adopt a fusion loss using two kinds of distance, the first is L2 sequence distance, which focuses on temporal order alignment. The second one is Optimal transport distance, which focuses on measuring the gap between the appearance and semantics of the videos. Using a simple fusion network, we fuse the two distances element-wise, then use the cross-entropy loss as our fusion loss. Extensive experiments show our method achieves state-of-the-art results on the HMDB51 and UCF101 datasets and a competitive result on the benchmark of Kinetics and something-2-something V2 datasets. Our code will be available at the URL: https://github.com/cofly2014/tsa-mlt.git
ISSTAD: Incremental Self-Supervised Learning Based on Transformer for Anomaly Detection and Localization
Apr 14, 2023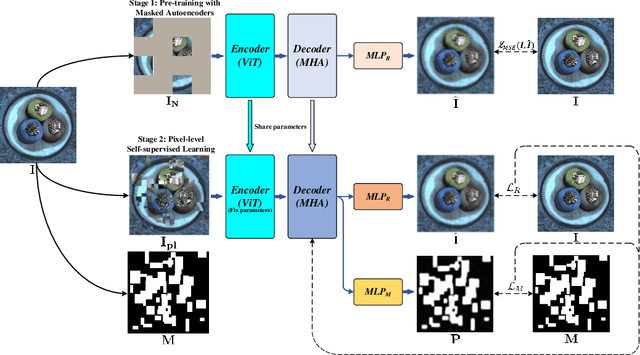
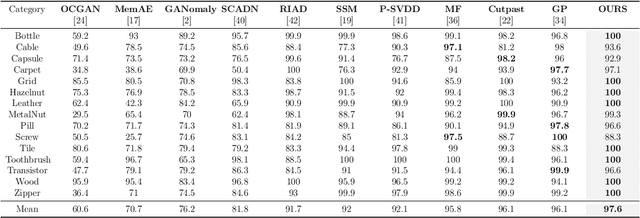
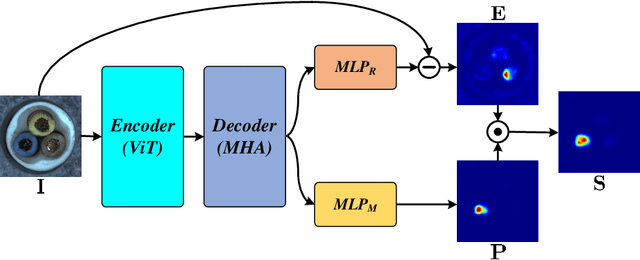
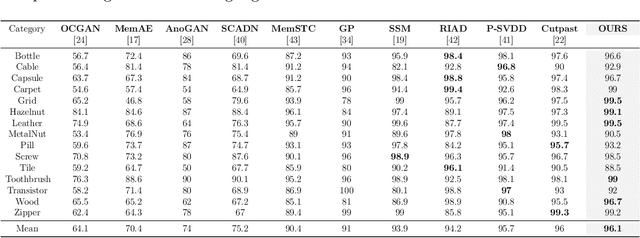
In the realm of machine learning, the study of anomaly detection and localization within image data has gained substantial traction, particularly for practical applications such as industrial defect detection. While the majority of existing methods predominantly use Convolutional Neural Networks (CNN) as their primary network architecture, we introduce a novel approach based on the Transformer backbone network. Our method employs a two-stage incremental learning strategy. During the first stage, we train a Masked Autoencoder (MAE) model solely on normal images. In the subsequent stage, we apply pixel-level data augmentation techniques to generate corrupted normal images and their corresponding pixel labels. This process allows the model to learn how to repair corrupted regions and classify the status of each pixel. Ultimately, the model generates a pixel reconstruction error matrix and a pixel anomaly probability matrix. These matrices are then combined to produce an anomaly scoring matrix that effectively detects abnormal regions. When benchmarked against several state-of-the-art CNN-based methods, our approach exhibits superior performance on the MVTec AD dataset, achieving an impressive 97.6% AUC.
Non-aligned supervision for Real Image Dehazing
Mar 14, 2023Removing haze from real-world images is challenging due to unpredictable weather conditions, resulting in misaligned hazy and clear image pairs. In this paper, we propose a non-aligned supervision framework that consists of three networks - dehazing, airlight, and transmission. In particular, we explore a non-alignment setting by utilizing a clear reference image that is not aligned with the hazy input image to supervise the dehazing network through a multi-scale reference loss that compares the features of the two images. Our setting makes it easier to collect hazy/clear image pairs in real-world environments, even under conditions of misalignment and shift views. To demonstrate this, we have created a new hazy dataset called "Phone-Hazy", which was captured using mobile phones in both rural and urban areas. Additionally, we present a mean and variance self-attention network to model the infinite airlight using dark channel prior as position guidance, and employ a channel attention network to estimate the three-channel transmission. Experimental results show that our framework outperforms current state-of-the-art methods in the real-world image dehazing. Phone-Hazy and code will be available at https://github.com/hello2377/NSDNet.