 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning First, Then Fusing: A Novel Weakly Supervised Multimodal Violence Detection Method
Jan 13, 2025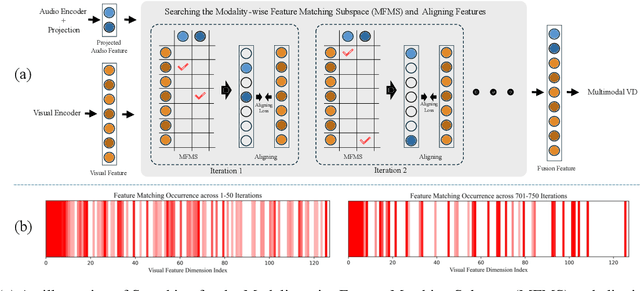
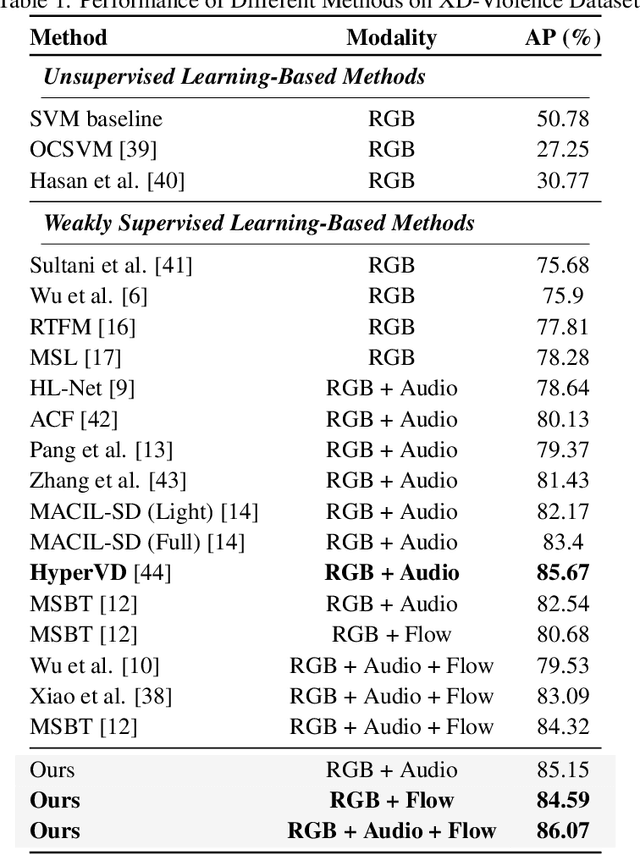
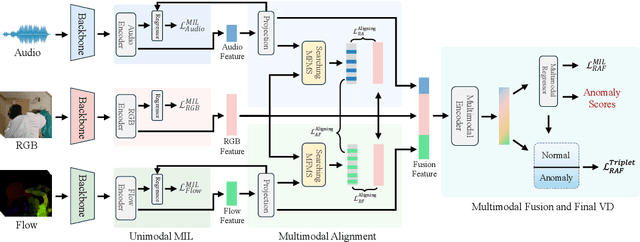
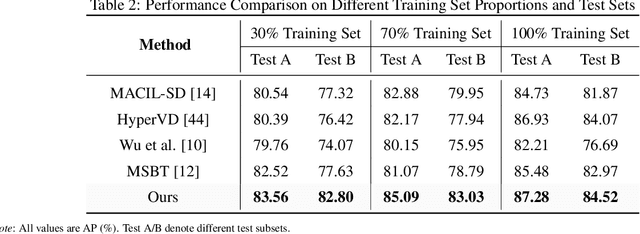
Weakly supervised violence detection refers to the technique of training models to identify violent segments in videos using only video-level labels. Among these approaches, multimodal violence detection, which integrates modalities such as audio and optical flow, holds great potential. Existing methods in this domain primarily focus on designing multimodal fusion models to address modality discrepancies. In contrast, we take a different approach; leveraging the inherent discrepancies across modalities in violence event representation to propose a novel multimodal semantic feature alignment method. This method sparsely maps the semantic features of local, transient, and less informative modalities ( such as audio and optical flow ) into the more informative RGB semantic feature space. Through an iterative process, the method identifies the suitable no-zero feature matching subspace and aligns the modality-specific event representations based on this subspace, enabling the full exploitation of information from all modalities during the subsequent modality fusion stage. Building on this, we design a new weakly supervised violence detection framework that consists of unimodal multiple-instance learning for extracting unimodal semantic features, multimodal alignment, multimodal fusion, and final detection. Experimental results on benchmark datasets demonstrate the effectiveness of our method, achieving an average precision (AP) of 86.07% on the XD-Violence dataset. Our code is available at https://github.com/xjpp2016/MAVD.
ISSTAD: Incremental Self-Supervised Learning Based on Transformer for Anomaly Detection and Localization
Apr 14, 2023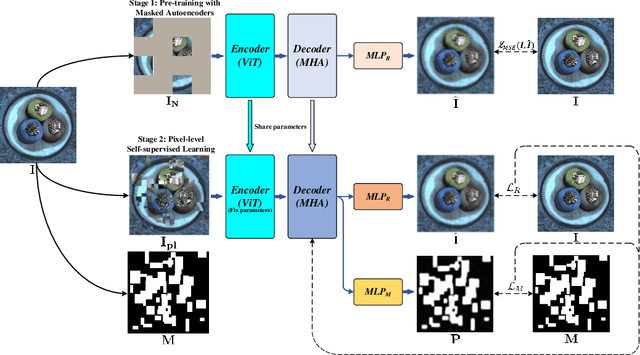
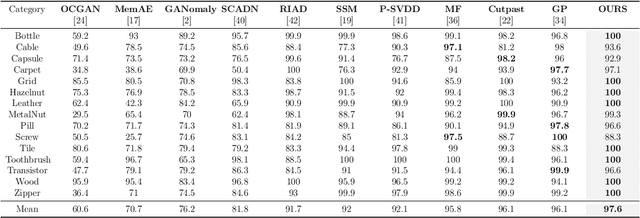
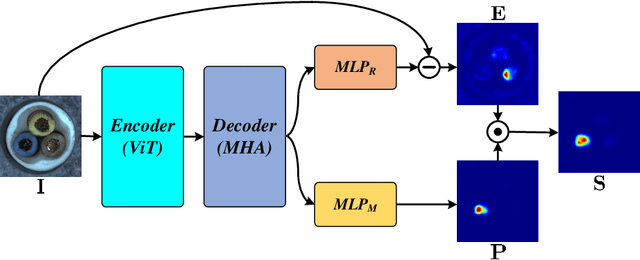
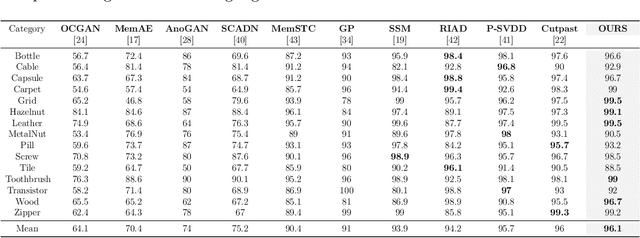
In the realm of machine learning, the study of anomaly detection and localization within image data has gained substantial traction, particularly for practical applications such as industrial defect detection. While the majority of existing methods predominantly use Convolutional Neural Networks (CNN) as their primary network architecture, we introduce a novel approach based on the Transformer backbone network. Our method employs a two-stage incremental learning strategy. During the first stage, we train a Masked Autoencoder (MAE) model solely on normal images. In the subsequent stage, we apply pixel-level data augmentation techniques to generate corrupted normal images and their corresponding pixel labels. This process allows the model to learn how to repair corrupted regions and classify the status of each pixel. Ultimately, the model generates a pixel reconstruction error matrix and a pixel anomaly probability matrix. These matrices are then combined to produce an anomaly scoring matrix that effectively detects abnormal regions. When benchmarked against several state-of-the-art CNN-based methods, our approach exhibits superior performance on the MVTec AD dataset, achieving an impressive 97.6% AUC.