 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inverse Laplacian Pyramid for Progressive Depth Completion
Feb 11, 2025Depth completion endeavors to reconstruct a dense depth map from sparse depth measurements, leveraging the information provided by a corresponding color image. Existing approaches mostly hinge on single-scale propagation strategies that iteratively ameliorate initial coarse depth estimates through pixel-level message passing. Despite their commendable outcomes, these techniques are frequently hampered by computational inefficiencies and a limited grasp of scene context. To circumvent these challenges, we introduce LP-Net, an innovative framework that implements a multi-scale, progressive prediction paradigm based on Laplacian Pyramid decomposition. Diverging from propagation-based approaches, LP-Net initiates with a rudimentary, low-resolution depth prediction to encapsulate the global scene context, subsequently refining this through successive upsampling and the reinstatement of high-frequency details at incremental scales. We have developed two novel modules to bolster this strategy: 1) the Multi-path Feature Pyramid module, which segregates feature maps into discrete pathways, employing multi-scale transformations to amalgamate comprehensive spatial information, and 2) the Selective Depth Filtering module, which dynamically learns to apply both smoothness and sharpness filters to judiciously mitigate noise while accentuating intricate details. By integrating these advancements, LP-Net not only secures state-of-the-art (SOTA) performance across both outdoor and indoor benchmarks such as KITTI, NYUv2, and TOFDC, but also demonstrates superior computational efficiency. At the time of submission, LP-Net ranks 1st among all peer-reviewed methods on the official KITTI leaderboard.
Guided Real Image Dehazing using YCbCr Color Space
Dec 24, 2024



Image dehazing, particularly with learning-based methods, has gained significant attention due to its importance in real-world applications. However, relying solely on the RGB color space often fall short, frequently leaving residual haze. This arises from two main issues: the difficulty in obtaining clear textural features from hazy RGB images and the complexity of acquiring real haze/clean image pairs outside controlled environments like smoke-filled scenes. To address these issues, we first propose a novel Structure Guided Dehazing Network (SGDN) that leverages the superior structural properties of YCbCr features over RGB. It comprises two key modules: Bi-Color Guidance Bridge (BGB) and Color Enhancement Module (CEM). BGB integrates a phase integration module and an interactive attention module, utilizing the rich texture features of the YCbCr space to guide the RGB space, thereby recovering clearer features in both frequency and spatial domains. To maintain tonal consistency, CEM further enhances the color perception of RGB features by aggregating YCbCr channel information. Furthermore, for effective supervised learning, we introduce a Real-World Well-Aligned Haze (RW$^2$AH) dataset, which includes a diverse range of scenes from various geographical regions and climate conditions. Experimental results demonstrate that our method surpasses existing state-of-the-art methods across multiple real-world smoke/haze datasets. Code and Dataset: \textcolor{blue}{\url{https://github.com/fiwy0527/AAAI25_SGDN.}}
Depth-Centric Dehazing and Depth-Estimation from Real-World Hazy Driving Video
Dec 16, 2024
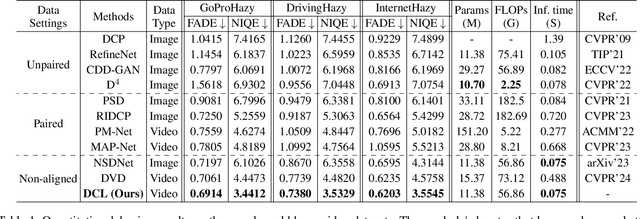
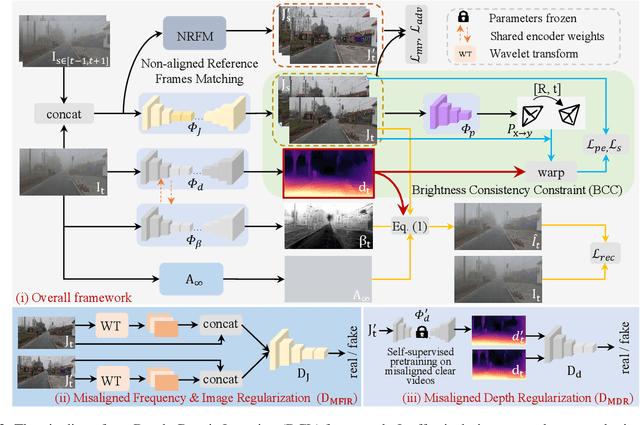
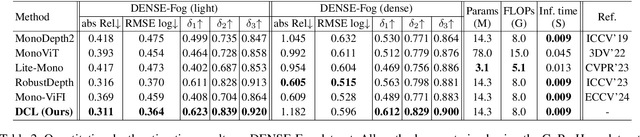
In this paper, we study the challenging problem of simultaneously removing haze and estimating depth from real monocular hazy videos. These tasks are inherently complementary: enhanced depth estimation improves dehazing via the atmospheric scattering model (ASM), while superior dehazing contributes to more accurate depth estimation through the brightness consistency constraint (BCC). To tackle these intertwined tasks, we propose a novel depth-centric learning framework that integrates the ASM model with the BCC constraint. Our key idea is that both ASM and BCC rely on a shared depth estimation network. This network simultaneously exploits adjacent dehazed frames to enhance depth estimation via BCC and uses the refined depth cues to more effectively remove haze through ASM. Additionally, we leverage a non-aligned clear video and its estimated depth to independently regularize the dehazing and depth estimation networks. This is achieved by designing two discriminator networks: $D_{MFIR}$ enhances high-frequency details in dehazed videos, and $D_{MDR}$ reduces the occurrence of black holes in low-texture regions. Extensive experiments demonstrate that the proposed method outperforms current state-of-the-art techniques in both video dehazing and depth estimation tasks, especially in real-world hazy scenes. Project page: https://fanjunkai1.github.io/projectpage/DCL/index.html.
DCDepth: Progressive Monocular Depth Estimation in Discrete Cosine Domain
Oct 19, 2024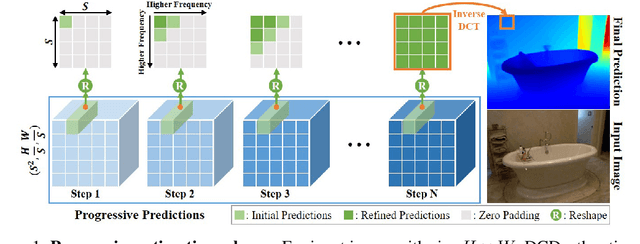
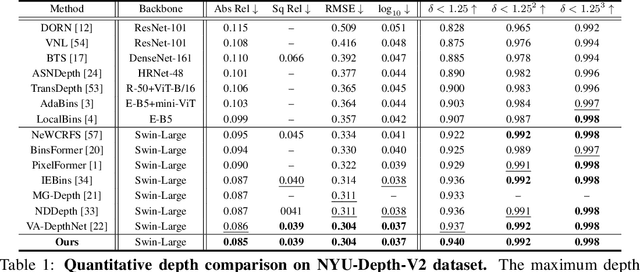

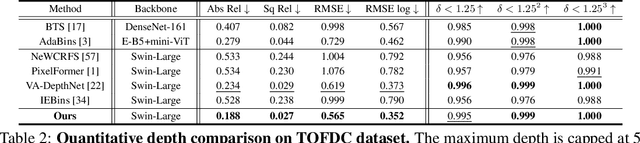
In this paper, we introduce DCDepth, a novel framework for the long-standing monocular depth estimation task. Moving beyond conventional pixel-wise depth estimation in the spatial domain, our approach estimates the frequency coefficients of depth patches after transforming them into the discrete cosine domain. This unique formulation allows for the modeling of local depth correlations within each patch. Crucially, the frequency transformation segregates the depth information into various frequency components, with low-frequency components encapsulating the core scene structure and high-frequency components detailing the finer aspects. This decomposition forms the basis of our progressive strategy, which begins with the prediction of low-frequency components to establish a global scene context, followed by successive refinement of local details through the prediction of higher-frequency components. We conduct comprehensive experiments on NYU-Depth-V2, TOFDC, and KITTI datasets, and demonstrate the state-of-the-art performance of DCDepth. Code is available at https://github.com/w2kun/DCDepth.
Driving-Video Dehazing with Non-Aligned Regularization for Safety Assistance
May 16, 2024



Real driving-video dehazing poses a significant challenge due to the inherent difficulty in acquiring precisely aligned hazy/clear video pairs for effective model training, especially in dynamic driving scenarios with unpredictable weather conditions. In this paper, we propose a pioneering approach that addresses this challenge through a nonaligned regularization strategy. Our core concept involves identifying clear frames that closely match hazy frames, serving as references to supervise a video dehazing network. Our approach comprises two key components: reference matching and video dehazing. Firstly, we introduce a non-aligned reference frame matching module, leveraging an adaptive sliding window to match high-quality reference frames from clear videos. Video dehazing incorporates flow-guided cosine attention sampler and deformable cosine attention fusion modules to enhance spatial multiframe alignment and fuse their improved information. To validate our approach, we collect a GoProHazy dataset captured effortlessly with GoPro cameras in diverse rural and urban road environments. Extensive experiments demonstrate the superiority of the proposed method over current state-of-the-art methods in the challenging task of real driving-video dehazing. Project page.
Non-aligned supervision for Real Image Dehazing
Mar 14, 2023Removing haze from real-world images is challenging due to unpredictable weather conditions, resulting in misaligned hazy and clear image pairs. In this paper, we propose a non-aligned supervision framework that consists of three networks - dehazing, airlight, and transmission. In particular, we explore a non-alignment setting by utilizing a clear reference image that is not aligned with the hazy input image to supervise the dehazing network through a multi-scale reference loss that compares the features of the two images. Our setting makes it easier to collect hazy/clear image pairs in real-world environments, even under conditions of misalignment and shift views. To demonstrate this, we have created a new hazy dataset called "Phone-Hazy", which was captured using mobile phones in both rural and urban areas. Additionally, we present a mean and variance self-attention network to model the infinite airlight using dark channel prior as position guidance, and employ a channel attention network to estimate the three-channel transmission. Experimental results show that our framework outperforms current state-of-the-art methods in the real-world image dehazing. Phone-Hazy and code will be available at https://github.com/hello2377/NSDNet.