 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASGNet: Adaptive Spectrum Guidance Network for Automatic Polyp Segmentation
Apr 16, 2026Early identification and removal of polyps can reduce the risk of developing colorectal cancer. However, the diverse morphologies, complex backgrounds and often concealed nature of polyps make polyp segmentation in colonoscopy images highly challenging. Despite the promising performance of existing deep learning-based polyp segmentation methods, their perceptual capabilities remain biased toward local regions, mainly because of the strong spatial correlations between neighboring pixels in the spatial domain. This limitation makes it difficult to capture the complete polyp structures, ultimately leading to sub-optimal segmentation results. In this paper, we propose a novel adaptive spectrum guidance network, called ASGNet, which addresses the limitations of spatial perception by integrating spectral features with global attributes. Specifically, we first design a spectrum-guided non-local perception module that jointly aggregates local and global information, therefore enhancing the discriminability of polyp structures, and refining their boundaries. Moreover, we introduce a multi-source semantic extractor that integrates rich high-level semantic information to assist in the preliminary localization of polyps. Furthermore, we construct a dense cross-layer interaction decoder that effectively integrates diverse information from different layers and strengthens it to generate high-quality representations for accurate polyp segmentation. Extensive quantitative and qualitative results demonstrate the superiority of our ASGNet approach over 21 state-of-the-art methods across five widely-used polyp segmentation benchmarks. The code will be publicly available at: https://github.com/CSYSI/ASGNet.
Few-Shot Incremental 3D Object Detection in Dynamic Indoor Environments
Apr 09, 2026Incremental 3D object perception is a critical step toward embodied intelligence in dynamic indoor environments. However, existing incremental 3D detection methods rely on extensive annotations of novel classes for satisfactory performance. To address this limitation, we propose FI3Det, a Few-shot Incremental 3D Detection framework that enables efficient 3D perception with only a few novel samples by leveraging vision-language models (VLMs) to learn knowledge of unseen categories. FI3Det introduces a VLM-guided unknown object learning module in the base stage to enhance perception of unseen categories. Specifically, it employs VLMs to mine unknown objects and extract comprehensive representations, including 2D semantic features and class-agnostic 3D bounding boxes. To mitigate noise in these representations, a weighting mechanism is further designed to re-weight the contributions of point- and box-level features based on their spatial locations and feature consistency within each box. Moreover, FI3Det proposes a gated multimodal prototype imprinting module, where category prototypes are constructed from aligned 2D semantic and 3D geometric features to compute classification scores, which are then fused via a multimodal gating mechanism for novel object detection. As the first framework for few-shot incremental 3D object detection, we establish both batch and sequential evaluation settings on two datasets, ScanNet V2 and SUN RGB-D, where FI3Det achieves strong and consistent improvements over baseline methods. Code is available at https://github.com/zyrant/FI3Det.
* Accepted by CVPR 2026
Progressive Representation Learning for Multimodal Sentiment Analysis with Incomplete Modalities
Mar 10, 2026Multimodal Sentiment Analysis (MSA) seeks to infer human emotions by integrating textual, acoustic, and visual cues. However, existing approaches often rely on all modalities are completeness, whereas real-world applications frequently encounter noise, hardware failures, or privacy restrictions that result in missing modalities. There exists a significant feature misalignment between incomplete and complete modalities, and directly fusing them may even distort the well-learned representations of the intact modalities. To this end, we propose PRLF, a Progressive Representation Learning Framework designed for MSA under uncertain missing-modality conditions. PRLF introduces an Adaptive Modality Reliability Estimator (AMRE), which dynamically quantifies the reliability of each modality using recognition confidence and Fisher information to determine the dominant modality. In addition, the Progressive Interaction (ProgInteract) module iteratively aligns the other modalities with the dominant one, thereby enhancing cross-modal consistency while suppressing noise. Extensive experiments on CMU-MOSI, CMU-MOSEI, and SIMS verify that PRLF outperforms state-of-the-art methods across both inter- and intra-modality missing scenarios, demonstrating its robustness and generalization capability.
WeatherGen: A Unified Diverse Weather Generator for LiDAR Point Clouds via Spider Mamba Diffusion
Apr 18, 2025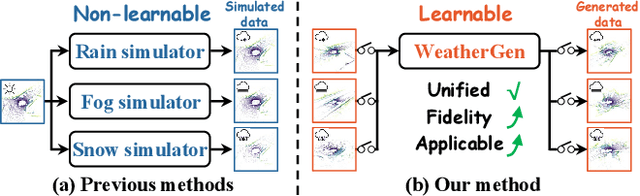

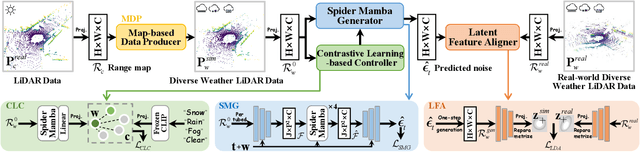

3D scene perception demands a large amount of adverse-weather LiDAR data, yet the cost of LiDAR data collection presents a significant scaling-up challenge. To this end, a series of LiDAR simulators have been proposed. Yet, they can only simulate a single adverse weather with a single physical model, and the fidelity of the generated data is quite limited. This paper presents WeatherGen, the first unified diverse-weather LiDAR data diffusion generation framework, significantly improving fidelity. Specifically, we first design a map-based data producer, which can provide a vast amount of high-quality diverse-weather data for training purposes. Then, we utilize the diffusion-denoising paradigm to construct a diffusion model. Among them, we propose a spider mamba generator to restore the disturbed diverse weather data gradually. The spider mamba models the feature interactions by scanning the LiDAR beam circle or central ray, excellently maintaining the physical structure of the LiDAR data. Subsequently, following the generator to transfer real-world knowledge, we design a latent feature aligner. Afterward, we devise a contrastive learning-based controller, which equips weather control signals with compact semantic knowledge through language supervision, guiding the diffusion model to generate more discriminative data. Extensive evaluations demonstrate the high generation quality of WeatherGen. Through WeatherGen, we construct the mini-weather dataset, promoting the performance of the downstream task under adverse weather conditions. Code is available: https://github.com/wuyang98/weathergen
Follow Your Motion: A Generic Temporal Consistency Portrait Editing Framework with Trajectory Guidance
Mar 28, 2025



Pre-trained conditional diffusion models have demonstrated remarkable potential in image editing. However, they often face challenges with temporal consistency, particularly in the talking head domain, where continuous changes in facial expressions intensify the level of difficulty. These issues stem from the independent editing of individual images and the inherent loss of temporal continuity during the editing process. In this paper, we introduce Follow Your Motion (FYM), a generic framework for maintaining temporal consistency in portrait editing. Specifically, given portrait images rendered by a pre-trained 3D Gaussian Splatting model, we first develop a diffusion model that intuitively and inherently learns motion trajectory changes at different scales and pixel coordinates, from the first frame to each subsequent frame. This approach ensures that temporally inconsistent edited avatars inherit the motion information from the rendered avatars. Secondly, to maintain fine-grained expression temporal consistency in talking head editing, we propose a dynamic re-weighted attention mechanism. This mechanism assigns higher weight coefficients to landmark points in space and dynamically updates these weights based on landmark loss, achieving more consistent and refined facial expressions. Extensive experiments demonstrate that our method outperforms existing approaches in terms of temporal consistency and can be used to optimize and compensate for temporally inconsistent outputs in a range of applications, such as text-driven editing, relighting, and various other applications.
Learning Class Prototypes for Unified Sparse Supervised 3D Object Detection
Mar 27, 2025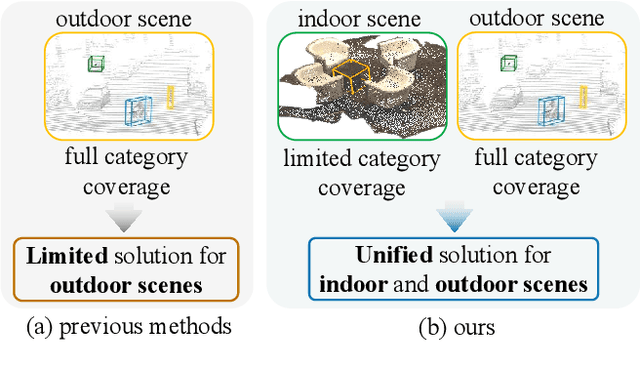
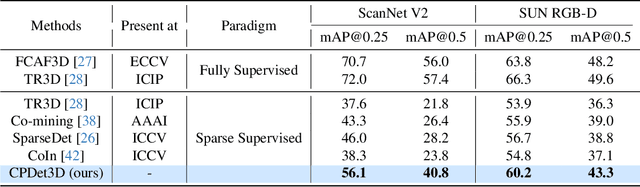
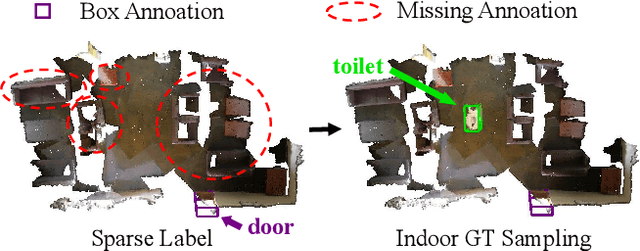
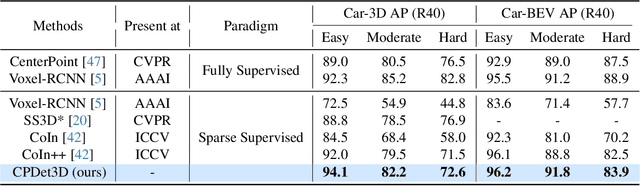
Both indoor and outdoor scene perceptions are essential for embodied intelligence. However, current sparse supervised 3D object detection methods focus solely on outdoor scenes without considering indoor settings. To this end, we propose a unified sparse supervised 3D object detection method for both indoor and outdoor scenes through learning class prototypes to effectively utilize unlabeled objects. Specifically, we first propose a prototype-based object mining module that converts the unlabeled object mining into a matching problem between class prototypes and unlabeled features. By using optimal transport matching results, we assign prototype labels to high-confidence features, thereby achieving the mining of unlabeled objects. We then present a multi-label cooperative refinement module to effectively recover missed detections through pseudo label quality control and prototype label cooperation. Experiments show that our method achieves state-of-the-art performance under the one object per scene sparse supervised setting across indoor and outdoor datasets. With only one labeled object per scene, our method achieves about 78%, 90%, and 96% performance compared to the fully supervised detector on ScanNet V2, SUN RGB-D, and KITTI, respectively, highlighting the scalability of our method. Code is available at https://github.com/zyrant/CPDet3D.
Remote Photoplethysmography in Real-World and Extreme Lighting Scenarios
Mar 14, 2025Physiological activities can be manifested by the sensitive changes in facial imaging. While they are barely observable to our eyes, computer vision manners can, and the derived remote photoplethysmography (rPPG) has shown considerable promise. However, existing studies mainly rely on spatial skin recognition and temporal rhythmic interactions, so they focus on identifying explicit features under ideal light conditions, but perform poorly in-the-wild with intricate obstacles and extreme illumination exposure. In this paper, we propose an end-to-end video transformer model for rPPG. It strives to eliminate complex and unknown external time-varying interferences, whether they are sufficient to occupy subtle biosignal amplitudes or exist as periodic perturbations that hinder network training. In the specific implementation, we utilize global interference sharing, subject background reference, and self-supervised disentanglement to eliminate interference, and further guide learning based on spatiotemporal filtering, reconstruction guidance, and frequency domain and biological prior constraints to achieve effective rPPG. To the best of our knowledge, this is the first robust rPPG model for real outdoor scenarios based on natural face videos, and is lightweight to deploy. Extensive experiments show the competitiveness and performance of our model in rPPG prediction across datasets and scenes.
ConsistentAvatar: Learning to Diffuse Fully Consistent Talking Head Avatar with Temporal Guidance
Nov 23, 2024



Diffusion models have shown impressive potential on talking head generation. While plausible appearance and talking effect are achieved, these methods still suffer from temporal, 3D or expression inconsistency due to the error accumulation and inherent limitation of single-image generation ability. In this paper, we propose ConsistentAvatar, a novel framework for fully consistent and high-fidelity talking avatar generation. Instead of directly employing multi-modal conditions to the diffusion process, our method learns to first model the temporal representation for stability between adjacent frames. Specifically, we propose a Temporally-Sensitive Detail (TSD) map containing high-frequency feature and contours that vary significantly along the time axis. Using a temporal consistent diffusion module, we learn to align TSD of the initial result to that of the video frame ground truth. The final avatar is generated by a fully consistent diffusion module, conditioned on the aligned TSD, rough head normal, and emotion prompt embedding. We find that the aligned TSD, which represents the temporal patterns, constrains the diffusion process to generate temporally stable talking head. Further, its reliable guidance complements the inaccuracy of other conditions, suppressing the accumulated error while improving the consistency on various aspects. Extensive experiments demonstrate that ConsistentAvatar outperforms the state-of-the-art methods on the generated appearance, 3D, expression and temporal consistency. Project page: https://njust-yang.github.io/ConsistentAvatar.github.io/
Text2LiDAR: Text-guided LiDAR Point Cloud Generation via Equirectangular Transformer
Jul 29, 2024



The complex traffic environment and various weather conditions make the collection of LiDAR data expensive and challenging. Achieving high-quality and controllable LiDAR data generation is urgently needed, controlling with text is a common practice, but there is little research in this field. To this end, we propose Text2LiDAR, the first efficient, diverse, and text-controllable LiDAR data generation model. Specifically, we design an equirectangular transformer architecture, utilizing the designed equirectangular attention to capture LiDAR features in a manner with data characteristics. Then, we design a control-signal embedding injector to efficiently integrate control signals through the global-to-focused attention mechanism. Additionally, we devise a frequency modulator to assist the model in recovering high-frequency details, ensuring the clarity of the generated point cloud. To foster development in the field and optimize text-controlled generation performance, we construct nuLiDARtext which offers diverse text descriptors for 34,149 LiDAR point clouds from 850 scenes. Experiments on uncontrolled and text-controlled generation in various forms on KITTI-360 and nuScenes datasets demonstrate the superiority of our approach.
MambaLLIE: Implicit Retinex-Aware Low Light Enhancement with Global-then-Local State Space
May 25, 2024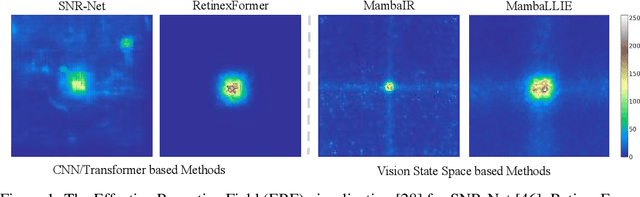
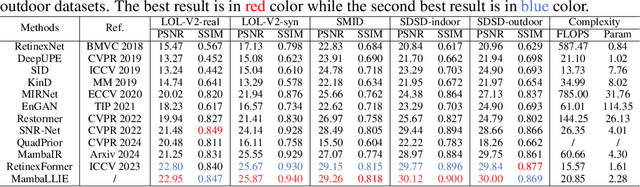
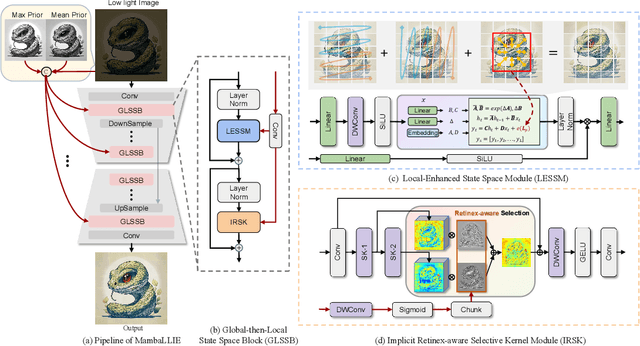
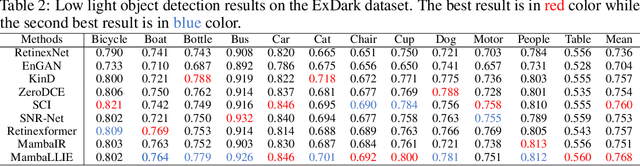
Recent advances in low light image enhancement have been dominated by Retinex-based learning framework, leveraging convolutional neural networks (CNNs) and Transformers. However, the vanilla Retinex theory primarily addresses global illumination degradation and neglects local issues such as noise and blur in dark conditions. Moreover, CNNs and Transformers struggle to capture global degradation due to their limited receptive fields. While state space models (SSMs) have shown promise in the long-sequence modeling, they face challenges in combining local invariants and global context in visual data. In this paper, we introduce MambaLLIE, an implicit Retinex-aware low light enhancer featuring a global-then-local state space design. We first propose a Local-Enhanced State Space Module (LESSM) that incorporates an augmented local bias within a 2D selective scan mechanism, enhancing the original SSMs by preserving local 2D dependency. Additionally, an Implicit Retinex-aware Selective Kernel module (IRSK) dynamically selects features using spatially-varying operations, adapting to varying inputs through an adaptive kernel selection process. Our Global-then-Local State Space Block (GLSSB) integrates LESSM and IRSK with LayerNorm as its core. This design enables MambaLLIE to achieve comprehensive global long-range modeling and flexible local feature aggregation. Extensive experiments demonstrate that MambaLLIE significantly outperforms state-of-the-art CNN and Transformer-based methods. Project Page: https://mamballie.github.io/anon/