 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherGen: A Unified Diverse Weather Generator for LiDAR Point Clouds via Spider Mamba Diffusion
Apr 18, 2025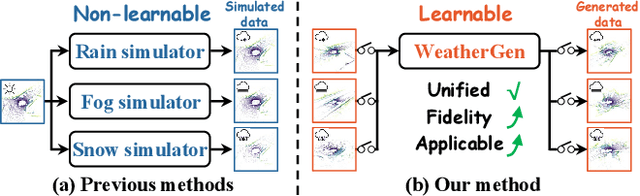

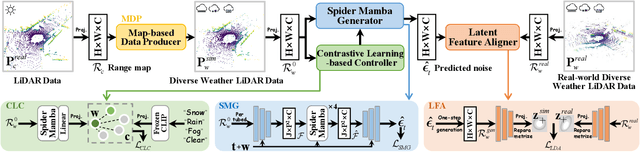

3D scene perception demands a large amount of adverse-weather LiDAR data, yet the cost of LiDAR data collection presents a significant scaling-up challenge. To this end, a series of LiDAR simulators have been proposed. Yet, they can only simulate a single adverse weather with a single physical model, and the fidelity of the generated data is quite limited. This paper presents WeatherGen, the first unified diverse-weather LiDAR data diffusion generation framework, significantly improving fidelity. Specifically, we first design a map-based data producer, which can provide a vast amount of high-quality diverse-weather data for training purposes. Then, we utilize the diffusion-denoising paradigm to construct a diffusion model. Among them, we propose a spider mamba generator to restore the disturbed diverse weather data gradually. The spider mamba models the feature interactions by scanning the LiDAR beam circle or central ray, excellently maintaining the physical structure of the LiDAR data. Subsequently, following the generator to transfer real-world knowledge, we design a latent feature aligner. Afterward, we devise a contrastive learning-based controller, which equips weather control signals with compact semantic knowledge through language supervision, guiding the diffusion model to generate more discriminative data. Extensive evaluations demonstrate the high generation quality of WeatherGen. Through WeatherGen, we construct the mini-weather dataset, promoting the performance of the downstream task under adverse weather conditions. Code is available: https://github.com/wuyang98/weathergen
Text2LiDAR: Text-guided LiDAR Point Cloud Generation via Equirectangular Transformer
Jul 29, 2024



The complex traffic environment and various weather conditions make the collection of LiDAR data expensive and challenging. Achieving high-quality and controllable LiDAR data generation is urgently needed, controlling with text is a common practice, but there is little research in this field. To this end, we propose Text2LiDAR, the first efficient, diverse, and text-controllable LiDAR data generation model. Specifically, we design an equirectangular transformer architecture, utilizing the designed equirectangular attention to capture LiDAR features in a manner with data characteristics. Then, we design a control-signal embedding injector to efficiently integrate control signals through the global-to-focused attention mechanism. Additionally, we devise a frequency modulator to assist the model in recovering high-frequency details, ensuring the clarity of the generated point cloud. To foster development in the field and optimize text-controlled generation performance, we construct nuLiDARtext which offers diverse text descriptors for 34,149 LiDAR point clouds from 850 scenes. Experiments on uncontrolled and text-controlled generation in various forms on KITTI-360 and nuScenes datasets demonstrate the superiority of our approach.
Shifting Spotlight for Co-supervision: A Simple yet Efficient Single-branch Network to See Through Camouflage
Apr 13, 2024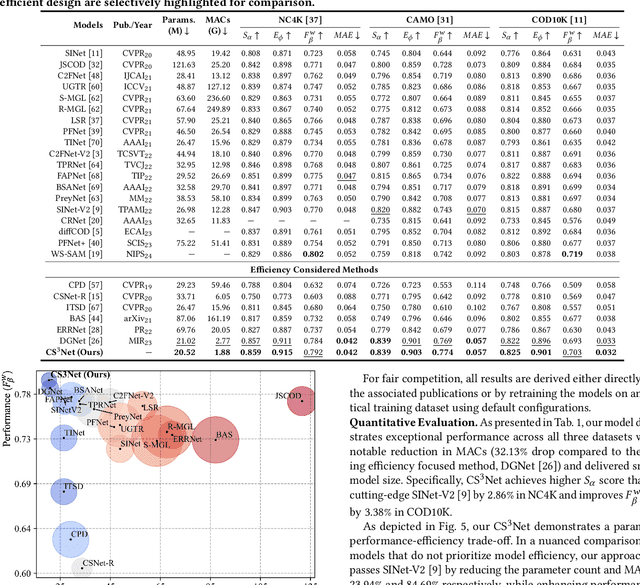
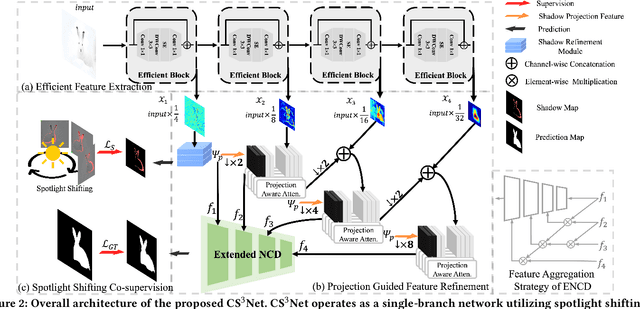

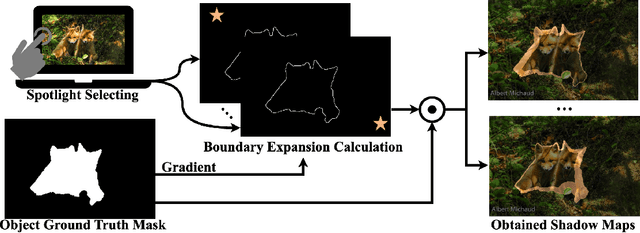
Efficient and accurate camouflaged object detection (COD) poses a challenge in the field of computer vision. Recent approaches explored the utility of edge information for network co-supervision, achieving notable advancements. However, these approaches introduce an extra branch for complex edge extraction, complicate the model architecture and increases computational demands. Addressing this issue, our work replicates the effect that animal's camouflage can be easily revealed under a shifting spotlight, and leverages it for network co-supervision to form a compact yet efficient single-branch network, the Co-Supervised Spotlight Shifting Network (CS$^3$Net). The spotlight shifting strategy allows CS$^3$Net to learn additional prior within a single-branch framework, obviating the need for resource demanding multi-branch design. To leverage the prior of spotlight shifting co-supervision, we propose Shadow Refinement Module (SRM) and Projection Aware Attention (PAA) for feature refinement and enhancement. To ensure the continuity of multi-scale features aggregation, we utilize the Extended Neighbor Connection Decoder (ENCD) for generating the final predictions. Empirical evaluations on public datasets confirm that our CS$^3$Net offers an optimal balance between efficiency and performance: it accomplishes a 32.13% reduction in Multiply-Accumulate (MACs) operations compared to leading efficient COD models, while also delivering superior performance.
Towards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
Oct 16, 2023The traditional definition of co-salient object detection (CoSOD) task is to segment the common salient objects in a group of relevant images. This definition is based on an assumption of group consensus consistency that is not always reasonable in the open-world setting, which results in robustness issue in the model when dealing with irrelevant images in the inputting image group under the open-word scenarios. To tackle this problem, we introduce a group selective exchange-masking (GSEM) approach for enhancing the robustness of the CoSOD model. GSEM takes two groups of images as input, each containing different types of salient objects. Based on the mixed metric we designed, GSEM selects a subset of images from each group using a novel learning-based strategy, then the selected images are exchanged. To simultaneously consider the uncertainty introduced by irrelevant images and the consensus features of the remaining relevant images in the group, we designed a latent variable generator branch and CoSOD transformer branch. The former is composed of a vector quantised-variational autoencoder to generate stochastic global variables that model uncertainty. The latter is designed to capture correlation-based local features that include group consensus. Finally, the outputs of the two branches are merged and passed to a transformer-based decoder to generate robust predictions. Taking into account that there are currently no benchmark datasets specifically designed for open-world scenarios, we constructed three open-world benchmark datasets, namely OWCoSal, OWCoSOD, and OWCoCA, based on existing datasets. By breaking the group-consistency assumption, these datasets provide effective simulations of real-world scenarios and can better evaluate the robustness and practicality of models.
Learning Self-Supervised Low-Rank Network for Single-Stage Weakly and Semi-Supervised Semantic Segmentation
Mar 19, 2022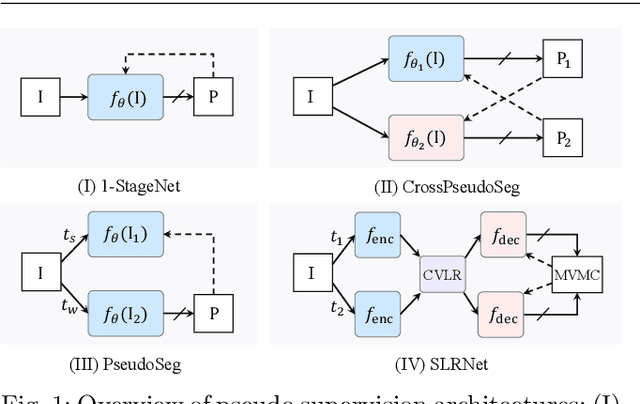
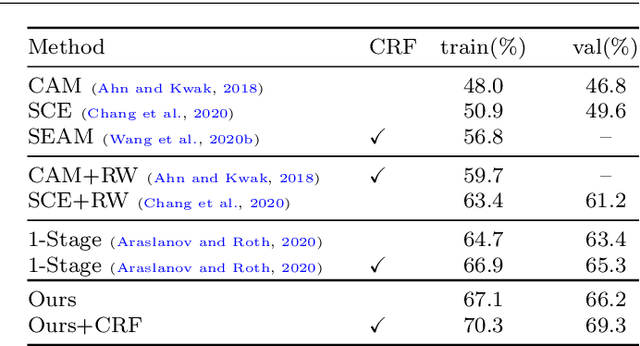
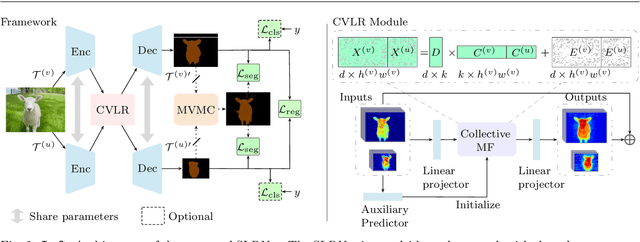
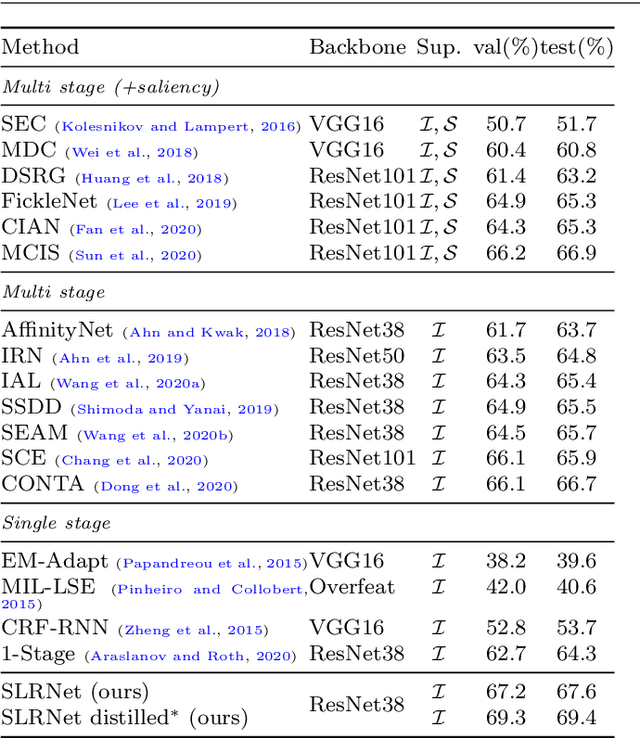
Semantic segmentation with limited annotations, such as weakly supervised semantic segmentation (WSSS) and semi-supervised semantic segmentation (SSSS), is a challenging task that has attracted much attention recently. Most leading WSSS methods employ a sophisticated multi-stage training strategy to estimate pseudo-labels as precise as possible, but they suffer from high model complexity. In contrast, there exists another research line that trains a single network with image-level labels in one training cycle. However, such a single-stage strategy often performs poorly because of the compounding effect caused by inaccurate pseudo-label estimation. To address this issue, this paper presents a Self-supervised Low-Rank Network (SLRNet) for single-stage WSSS and SSSS. The SLRNet uses cross-view self-supervision, that is, it simultaneously predicts several complementary attentive LR representations from different views of an image to learn precise pseudo-labels. Specifically, we reformulate the LR representation learning as a collective matrix factorization problem and optimize it jointly with the network learning in an end-to-end manner. The resulting LR representation deprecates noisy information while capturing stable semantics across different views, making it robust to the input variations, thereby reducing overfitting to self-supervision errors. The SLRNet can provide a unified single-stage framework for various label-efficient semantic segmentation settings: 1) WSSS with image-level labeled data, 2) SSSS with a few pixel-level labeled data, and 3) SSSS with a few pixel-level labeled data and many image-level labeled data. Extensive experiments on the Pascal VOC 2012, COCO, and L2ID datasets demonstrate that our SLRNet outperforms both state-of-the-art WSSS and SSSS methods with a variety of different settings, proving its good generalizability and efficacy.
Learning Dynamic Compact Memory Embedding for Deformable Visual Object Tracking
Nov 23, 2021
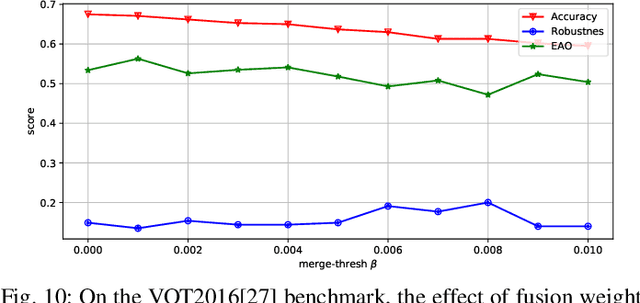

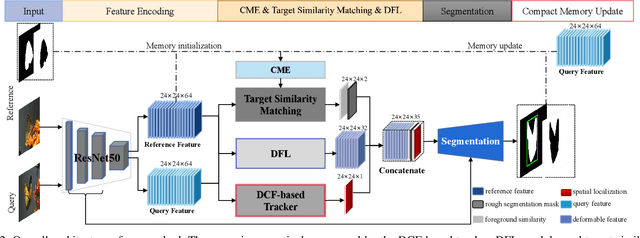
Recently, template-based trackers have become the leading tracking algorithms with promising performance in terms of efficiency and accuracy. However, the correlation operation between query feature and the given template only exploits accurate target localization, leading to state estimation error especially when the target suffers from severe deformable variations. To address this issue, segmentation-based trackers have been proposed that employ per-pixel matching to improve the tracking performance of deformable objects effectively. However, most of existing trackers only refer to the target features in the initial frame, thereby lacking the discriminative capacity to handle challenging factors, e.g., similar distractors, background clutter, appearance change, etc. To this end, we propose a dynamic compact memory embedding to enhance the discrimination of the segmentation-based deformable visual tracking method. Specifically, we initialize a memory embedding with the target features in the first frame. During the tracking process, the current target features that have high correlation with existing memory are updated to the memory embedding online. To further improve the segmentation accuracy for deformable objects, we employ a point-to-global matching strategy to measure the correlation between the pixel-wise query features and the whole template, so as to capture more detailed deformation information. Extensive evaluations on six challenging tracking benchmarks including VOT2016, VOT2018, VOT2019, GOT-10K, TrackingNet, and LaSOT demonstrate the superiority of our method over recent remarkable trackers. Besides, our method outperforms the excellent segmentation-based trackers, i.e., D3S and SiamMask on DAVIS2017 benchmark.
Discriminative Segmentation Tracking Using Dual Memory Banks
Sep 29, 2020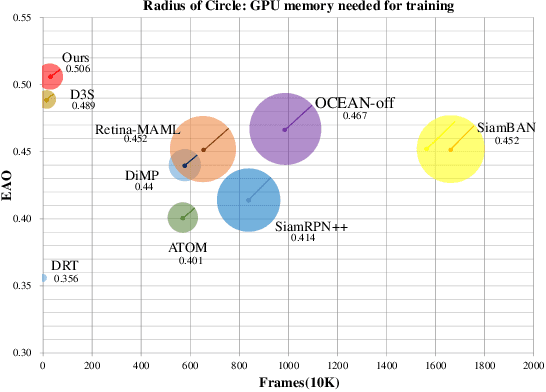
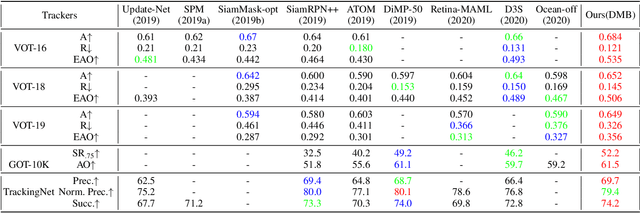
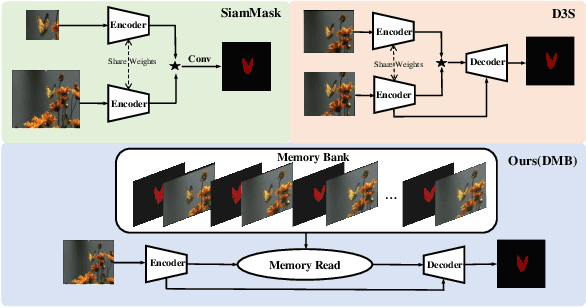
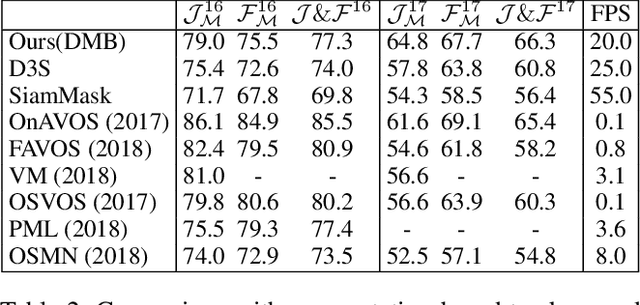
Existing template-based trackers usually localize the target in each frame with bounding box, thereby being limited in learning pixel-wise representation and handling complex and non-rigid transformation of the target. Further, existing segmentation tracking methods are still insufficient in modeling and exploiting dense correspondence of target pixels across frames. To overcome these limitations, this work presents a novel discriminative segmentation tracking architecture equipped with dual memory banks, i.e., appearance memory bank and spatial memory bank. In particular, the appearance memory bank utilizes spatial and temporal non-local similarity to propagate segmentation mask to the current frame, and we further treat discriminative correlation filter as spatial memory bank to store the mapping between feature map and spatial map. Without bells and whistles, our simple-yet-effective tracking architecture sets a new state-of-the-art on the VOT2016, VOT2018, VOT2019, GOT-10K and TrackingNet benchmarks, especially achieving the EAO of 0.535 and 0.506 respectively on VOT2016 and VOT2018. Moreover, our approach outperforms the leading segmentation tracker D3S on two video object segmentation benchmarks DAVIS16 and DAVIS17. The source code will be released at https://github.com/phiphiphi31/DMB.
Adaptive Graph Convolutional Network with Attention Graph Clustering for Co-saliency Detection
Mar 13, 2020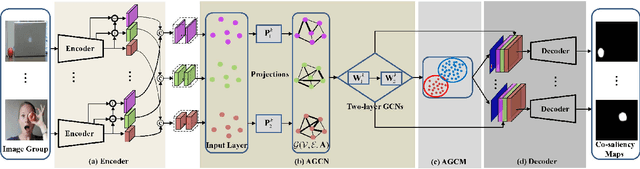

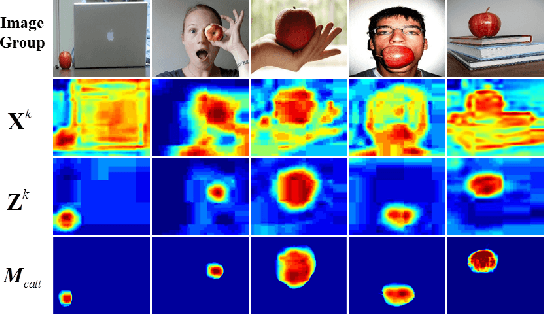
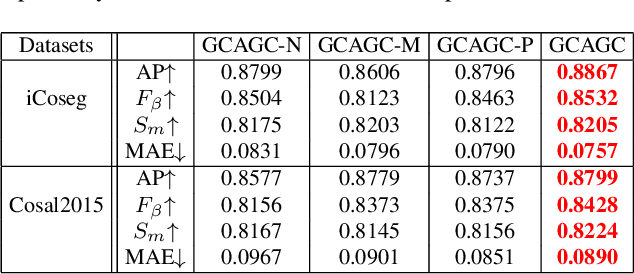
Co-saliency detection aims to discover the common and salient foregrounds from a group of relevant images. For this task, we present a novel adaptive graph convolutional network with attention graph clustering (GCAGC). Three major contributions have been made, and are experimentally shown to have substantial practical merits. First, we propose a graph convolutional network design to extract information cues to characterize the intra- and interimage correspondence. Second, we develop an attention graph clustering algorithm to discriminate the common objects from all the salient foreground objects in an unsupervised fashion. Third, we present a unified framework with encoder-decoder structure to jointly train and optimize the graph convolutional network, attention graph cluster, and co-saliency detection decoder in an end-to-end manner. We evaluate our proposed GCAGC method on three cosaliency detection benchmark datasets (iCoseg, Cosal2015 and COCO-SEG). Our GCAGC method obtains significant improvements over the state-of-the-arts on most of them.
Dual Temporal Memory Network for Efficient Video Object Segmentation
Mar 13, 2020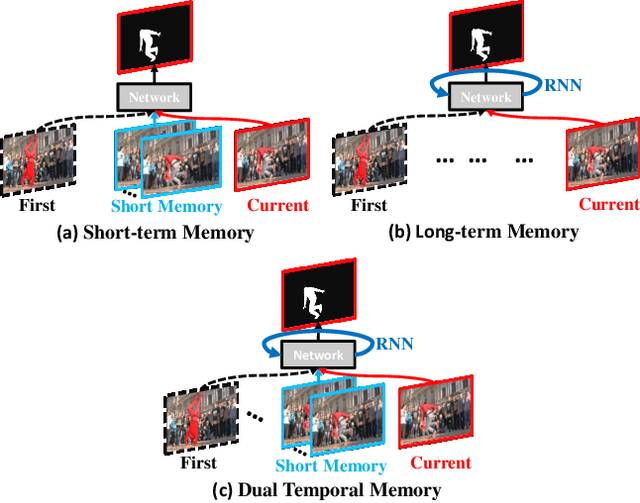
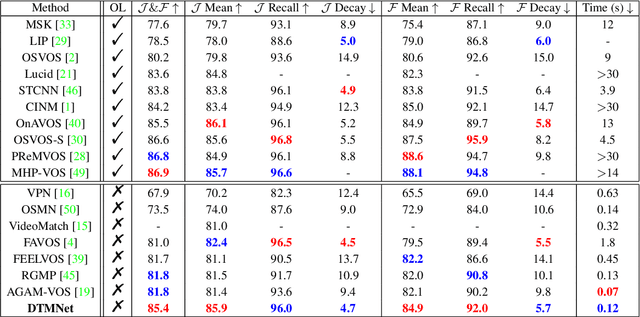
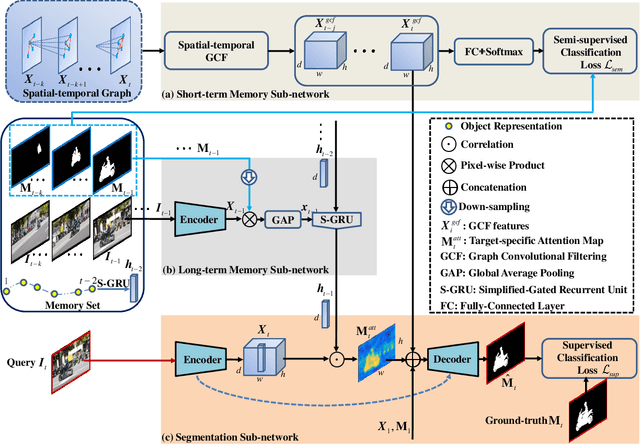
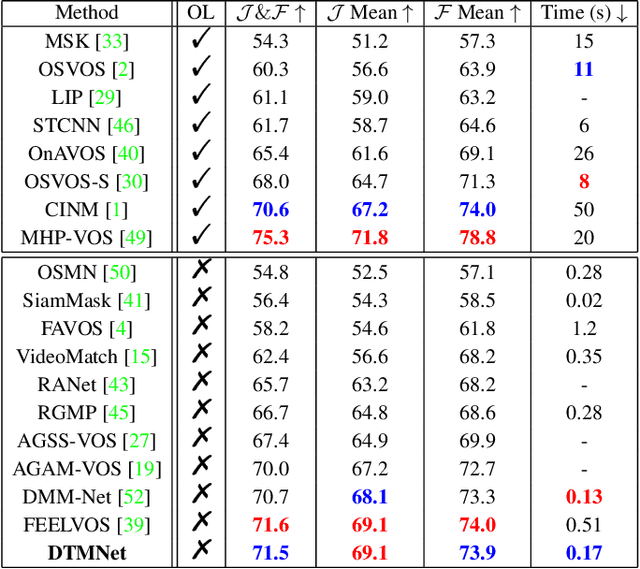
Video Object Segmentation (VOS) is typically formulated in a semi-supervised setting. Given the ground-truth segmentation mask on the first frame, the task of VOS is to track and segment the single or multiple objects of interests in the rest frames of the video at the pixel level. One of the fundamental challenges in VOS is how to make the most use of the temporal information to boost the performance. We present an end-to-end network which stores short- and long-term video sequence information preceding the current frame as the temporal memories to address the temporal modeling in VOS. Our network consists of two temporal sub-networks including a short-term memory sub-network and a long-term memory sub-network. The short-term memory sub-network models the fine-grained spatial-temporal interactions between local regions across neighboring frames in video via a graph-based learning framework, which can well preserve the visual consistency of local regions over time. The long-term memory sub-network models the long-range evolution of object via a Simplified-Gated Recurrent Unit (S-GRU), making the segmentation be robust against occlusions and drift errors. In our experiments, we show that our proposed method achieves a favorable and competitive performance on three frequently-used VOS datasets, including DAVIS 2016, DAVIS 2017 and Youtube-VOS in terms of both speed and accuracy.
Video Saliency Prediction Using Enhanced Spatiotemporal Alignment Network
Jan 02, 2020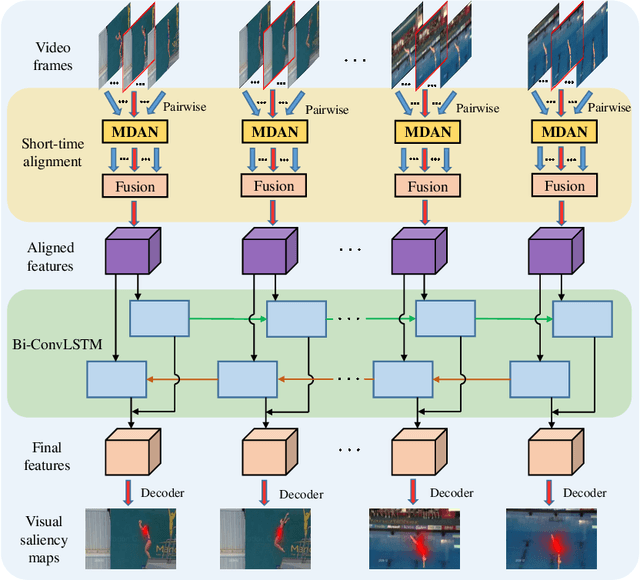
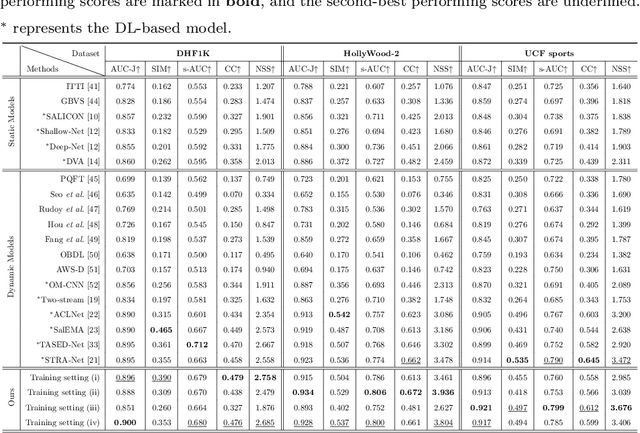
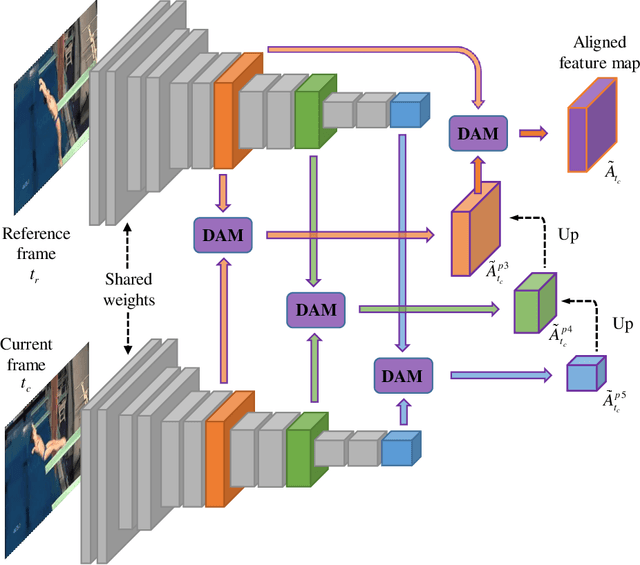
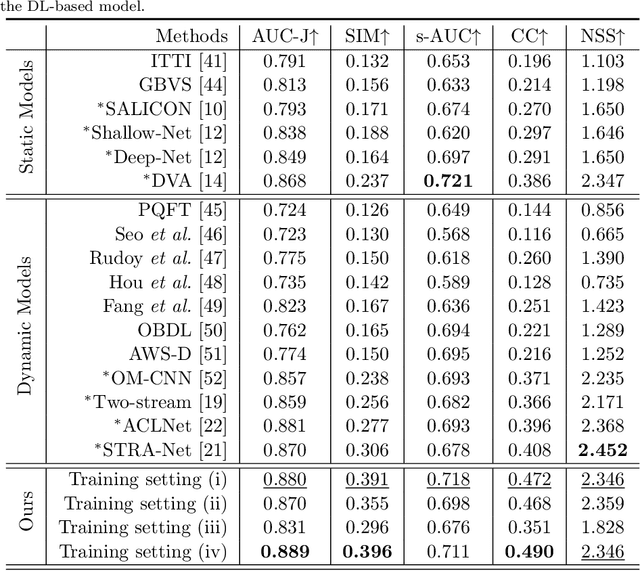
Due to a variety of motions across different frames, it is highly challenging to learn an effective spatiotemporal representation for accurate video saliency prediction (VSP). To address this issue, we develop an effective spatiotemporal feature alignment network tailored to VSP, mainly including two key sub-networks: a multi-scale deformable convolutional alignment network (MDAN) and a bidirectional convolutional Long Short-Term Memory (Bi-ConvLSTM) network. The MDAN learns to align the features of the neighboring frames to the reference one in a coarse-to-fine manner, which can well handle various motions. Specifically, the MDAN owns a pyramidal feature hierarchy structure that first leverages deformable convolution (Dconv) to align the lower-resolution features across frames, and then aggregates the aligned features to align the higher-resolution features, progressively enhancing the features from top to bottom. The output of MDAN is then fed into the Bi-ConvLSTM for further enhancement, which captures the useful long-time temporal information along forward and backward timing directions to effectively guide attention orientation shift prediction under complex scene transformation. Finally, the enhanced features are decoded to generate the predicted saliency map. The proposed model is trained end-to-end without any intricate post processing. Extensive evaluations on four VSP benchmark datasets demonstrate that the proposed method achieves favorable performance against state-of-the-art methods. The source codes and all the results will be released.