 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Efficient Pig Counting in Crowds with Keypoints Tracking and Spatial-aware Temporal Response Filtering
May 27, 2020

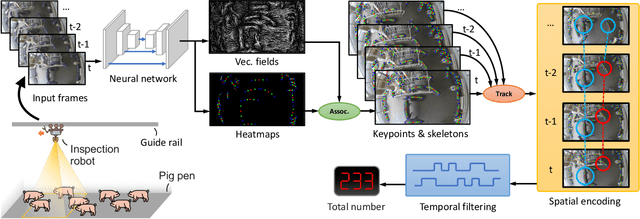
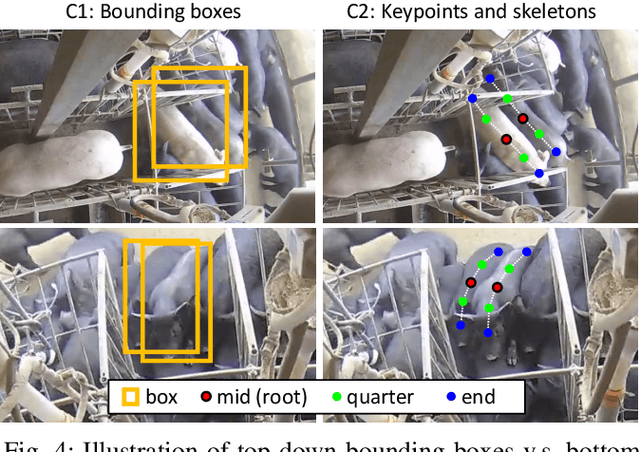
Pig counting is a crucial task for large-scale pig farming, which is usually completed by human visually. But this process is very time-consuming and error-prone. Few studies in literature developed automated pig counting method. Existing methods only focused on pig counting using single image, and its accuracy is challenged by several factors, including pig movements, occlusion and overlapping. Especially, the field of view of a single image is very limited, and could not meet the requirements of pig counting for large pig grouping houses. To that end, we presented a real-time automated pig counting system in crowds using only one monocular fisheye camera with an inspection robot. Our system showed that it produces accurate results surpassing human. Our pipeline began with a novel bottom-up pig detection algorithm to avoid false negatives due to overlapping, occlusion and deformation of pigs. A deep convolution neural network (CNN) is designed to detect keypoints of pig body part and associate the keypoints to identify individual pigs. After that, an efficient on-line tracking method is used to associate pigs across video frames. Finally, a novel spatial-aware temporal response filtering (STRF) method is proposed to predict the counts of pigs, which is effective to suppress false positives caused by pig or camera movements or tracking failures. The whole pipeline has been deployed in an edge computing device, and demonstrated the effectiveness.
Adaptive Graph Convolutional Network with Attention Graph Clustering for Co-saliency Detection
Mar 13, 2020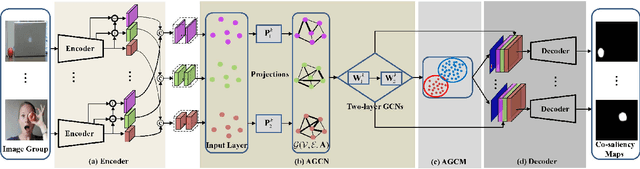

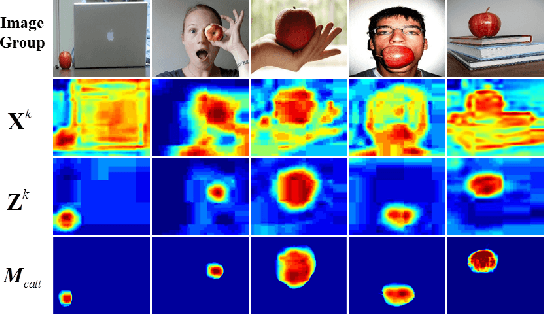
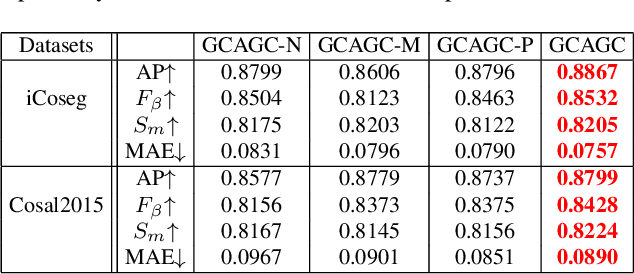
Co-saliency detection aims to discover the common and salient foregrounds from a group of relevant images. For this task, we present a novel adaptive graph convolutional network with attention graph clustering (GCAGC). Three major contributions have been made, and are experimentally shown to have substantial practical merits. First, we propose a graph convolutional network design to extract information cues to characterize the intra- and interimage correspondence. Second, we develop an attention graph clustering algorithm to discriminate the common objects from all the salient foreground objects in an unsupervised fashion. Third, we present a unified framework with encoder-decoder structure to jointly train and optimize the graph convolutional network, attention graph cluster, and co-saliency detection decoder in an end-to-end manner. We evaluate our proposed GCAGC method on three cosaliency detection benchmark datasets (iCoseg, Cosal2015 and COCO-SEG). Our GCAGC method obtains significant improvements over the state-of-the-arts on most of them.
Computed Tomography Image Enhancement using 3D Convolutional Neural Network
Jul 18, 2018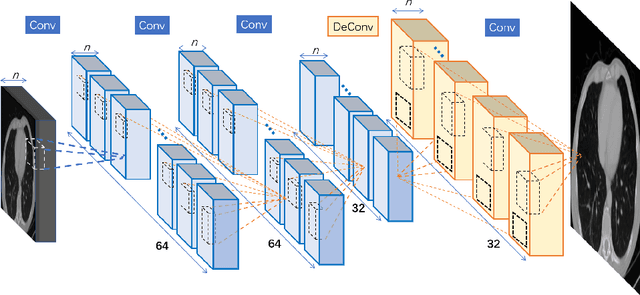
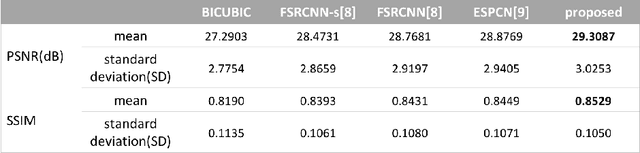
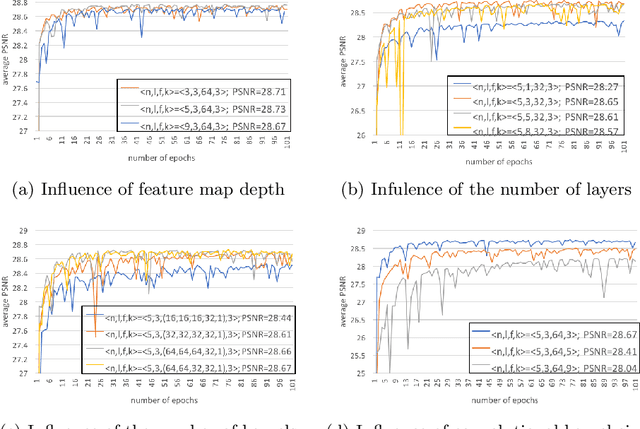
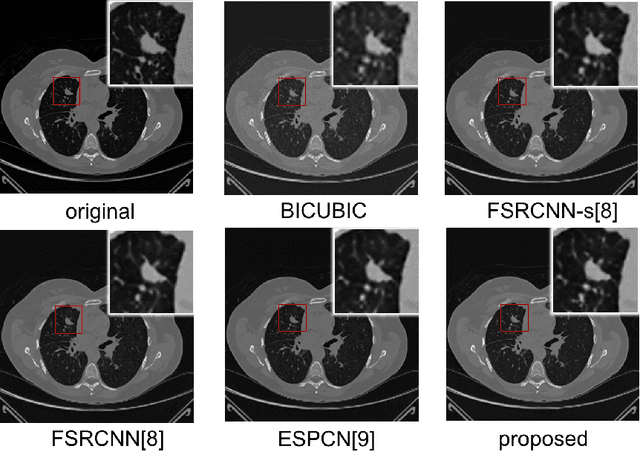
Computed tomography (CT) is increasingly being used for cancer screening, such as early detection of lung cancer. However, CT studies have varying pixel spacing due to differences in acquisition parameters. Thick slice CTs have lower resolution, hindering tasks such as nodule characterization during computer-aided detection due to partial volume effect. In this study, we propose a novel 3D enhancement convolutional neural network (3DECNN) to improve the spatial resolution of CT studies that were acquired using lower resolution/slice thicknesses to higher resolutions. Using a subset of the LIDC dataset consisting of 20,672 CT slices from 100 scans, we simulated lower resolution/thick section scans then attempted to reconstruct the original images using our 3DECNN network. A significant improvement in PSNR (29.3087dB vs. 28.8769dB, p-value < 2.2e-16) and SSIM (0.8529dB vs. 0.8449dB, p-value < 2.2e-16) compared to other state-of-art deep learning methods is observed.
An Interpretable Deep Hierarchical Semantic Convolutional Neural Network for Lung Nodule Malignancy Classification
Jun 02, 2018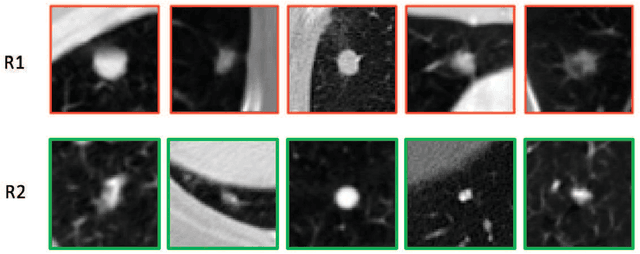
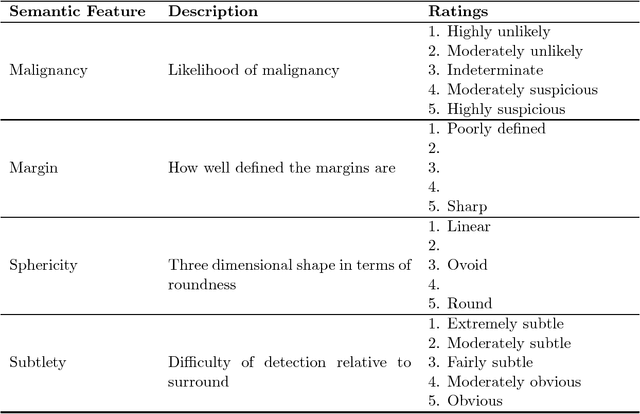

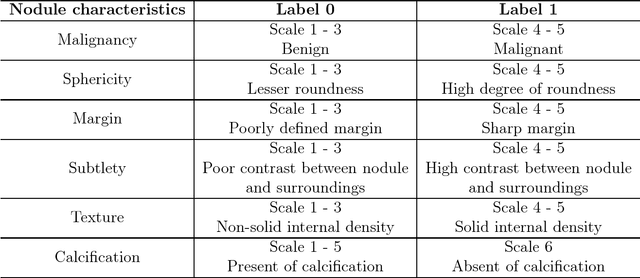
While deep learning methods are increasingly being applied to tasks such as computer-aided diagnosis, these models are difficult to interpret, do not incorporate prior domain knowledge, and are often considered as a "black-box." The lack of model interpretability hinders them from being fully understood by target users such as radiologists. In this paper, we present a novel interpretable deep hierarchical semantic convolutional neural network (HSCNN) to predict whether a given pulmonary nodule observed on a computed tomography (CT) scan is malignant. Our network provides two levels of output: 1) low-level radiologist semantic features, and 2) a high-level malignancy prediction score. The low-level semantic outputs quantify the diagnostic features used by radiologists and serve to explain how the model interprets the images in an expert-driven manner. The information from these low-level tasks, along with the representations learned by the convolutional layers, are then combined and used to infer the high-level task of predicting nodule malignancy. This unified architecture is trained by optimizing a global loss function including both low- and high-level tasks, thereby learning all the parameters within a joint framework. Our experimental results using the Lung Image Database Consortium (LIDC) show that the proposed method not only produces interpretable lung cancer predictions but also achieves significantly better results compared to common 3D CNN approaches.