 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegBins: Degradation-Driven Binning for Depth Super-Resolution
May 10, 2026Depth super-resolution (DSR) aims to recover a high-resolution (HR) depth map from its low-resolution (LR) counterpart. With color image guidance, this task is typically formulated as learning the residual between HR and LR in a low-dimensional feature space. However, this additive formulation is insufficient to accurately capture the complex relationship between HR and LR, especially under spatially varying degradations. In this paper, we introduce DegBins, a novel DSR framework that leverages degradation-driven binning to adaptively enhance residual modeling. Specifically, DegBins reformulates the regression-based DSR as a hybrid classification-regression problem, where the residual depth is represented as a linear combination of discrete depth bins weighted by their learned probability distribution, yielding more flexible and expressive representations. Furthermore, DegBins models the degradation relationship between HR and LR in a high-dimensional feature space, enabling adaptive bin range adjustment and probability optimization conditioned on local degradation characteristics. To progressively improve reconstruction quality, DegBins adopts a multi-stage refinement scheme, where each stage performs finer-grained bin partitioning and probability updating based on the former estimation. This coarse-to-fine design facilitates more accurate depth recovery, particularly in regions with severe degradations or complex structural variations. Extensive experiments across five benchmarks demonstrate that DegBins consistently outperforms existing state-of-the-art methods in terms of accuracy, robustness, and generalization.
Height-Guided Projection Reparameterization for Camera-LiDAR Occupancy
May 06, 20263D occupancy prediction aims to infer dense, voxel-wise scene semantics from sensor observations, where the 2D-to-3D view transformation serves as a crucial step in bridging image features and volumetric representations. Most previous methods rely on a fixed projection space, where 3D reference points are uniformly sampled along pillars. However, such sampling struggles to capture the sparsity and height variations of real-world scenes, leading to ambiguous correspondences and unreliable feature aggregation. To address these challenges, we propose HiPR, a camera-LiDAR occupancy framework with Height-Guided Projection Reparameterization. HiPR first encodes LiDAR into a BEV height map to capture the maximum height of the point cloud. HiPR then adjusts the sampling range of each pillar using the height prior, enabling adaptive reparameterization of the projection space. As a result, the projected points are redistributed into geometrically meaningful regions rather than fixed ranges. Meanwhile, we mask out the invalid parts of the height map to avoid misleading the feature aggregation. In addition, to alleviate the training instability caused by noisy LiDAR-derived heights, we introduce a training-time Progressive Height Conditioning strategy, which gradually transitions the conditioning signal from ground-truth heights to LiDAR heights. Extensive experiments demonstrate that HiPR consistently outperforms existing state-of-the-art methods while maintaining real-time inference. The code and pretrained models can be found at https://github.com/Rayn-Wu/HiPR.
Towards Lifelong Aerial Autonomy: Geometric Memory Management for Continual Visual Place Recognition in Dynamic Environments
Apr 10, 2026Robust geo-localization in changing environmental conditions is critical for long-term aerial autonomy. While visual place recognition (VPR) models perform well when airborne views match the training domain, adapting them to shifting distributions during sequential missions triggers catastrophic forgetting. Existing continual learning (CL) methods often fail here because geographic features exhibit severe intra-class variations. In this work, we formulate aerial VPR as a mission-based domain-incremental learning (DIL) problem and propose a novel heterogeneous memory framework. To respect strict onboard storage constraints, our "Learn-and-Dispose" pipeline decouples geographic knowledge into static satellite anchors (preserving global geometric priors) and a dynamic experience replay buffer (retaining domain-specific features). We introduce a spatially-constrained allocation strategy that optimizes buffer selection based on sample difficulty or feature space diversity. To facilitate systematic assessment, we provide three evaluation criteria and a comprehensive benchmark derived from 21 diverse mission sequences. Extensive experiments demonstrate that our architecture significantly boosts spatial generalization; our diversity-driven buffer selection outperforms the random baseline by 7.8% in knowledge retention. Unlike class-mean preservation methods that fail in unstructured environments, maximizing structural diversity achieves a superior plasticity-stability balance and ensures order-agnostic robustness across randomized sequences. These results prove that maintaining structural feature coverage is more critical than sample difficulty for resolving catastrophic forgetting in lifelong aerial autonomy.
CM-Bench: A Comprehensive Cross-Modal Feature Matching Benchmark Bridging Visible and Infrared Images
Mar 13, 2026Infrared-visible (IR-VIS) feature matching plays an essential role in cross-modality visual localization, navigation and perception. Along with the rapid development of deep learning techniques, a number of representative image matching methods have been proposed. However, crossmodal feature matching is still a challenging task due to the significant appearance difference. A significant gap for cross-modal feature matching research lies in the absence of standardized benchmarks and metrics for evaluations. In this paper, we introduce a comprehensive cross-modal feature matching benchmark, CM-Bench, which encompasses 30 feature matching algorithms across diverse cross-modal datasets. Specifically, state-of-the-art traditional and deep learning-based methods are first summarized and categorized into sparse, semidense, and dense methods. These methods are evaluated by different tasks including homography estimation, relative pose estimation, and feature-matching-based geo-localization. In addition, we introduce a classification-network-based adaptive preprocessing front-end that automatically selects suitable enhancement strategies before matching. We also present a novel infrared-satellite cross-modal dataset with manually annotated ground-truth correspondences for practical geo-localization evaluation. The dataset and resource will be available at: https://github.com/SLZ98/CM-Bench.
See through the Dark: Learning Illumination-affined Representations for Nighttime Occupancy Prediction
May 28, 2025



Occupancy prediction aims to estimate the 3D spatial distribution of occupied regions along with their corresponding semantic labels. Existing vision-based methods perform well on daytime benchmarks but struggle in nighttime scenarios due to limited visibility and challenging lighting conditions. To address these challenges, we propose \textbf{LIAR}, a novel framework that learns illumination-affined representations. LIAR first introduces Selective Low-light Image Enhancement (SLLIE), which leverages the illumination priors from daytime scenes to adaptively determine whether a nighttime image is genuinely dark or sufficiently well-lit, enabling more targeted global enhancement. Building on the illumination maps generated by SLLIE, LIAR further incorporates two illumination-aware components: 2D Illumination-guided Sampling (2D-IGS) and 3D Illumination-driven Projection (3D-IDP), to respectively tackle local underexposure and overexposure. Specifically, 2D-IGS modulates feature sampling positions according to illumination maps, assigning larger offsets to darker regions and smaller ones to brighter regions, thereby alleviating feature degradation in underexposed areas. Subsequently, 3D-IDP enhances semantic understanding in overexposed regions by constructing illumination intensity fields and supplying refined residual queries to the BEV context refinement process. Extensive experiments on both real and synthetic datasets demonstrate the superior performance of LIAR under challenging nighttime scenarios. The source code and pretrained models are available \href{https://github.com/yanzq95/LIAR}{here}.
Event-Driven Dynamic Scene Depth Completion
May 19, 2025



Depth completion in dynamic scenes poses significant challenges due to rapid ego-motion and object motion, which can severely degrade the quality of input modalities such as RGB images and LiDAR measurements. Conventional RGB-D sensors often struggle to align precisely and capture reliable depth under such conditions. In contrast, event cameras with their high temporal resolution and sensitivity to motion at the pixel level provide complementary cues that are %particularly beneficial in dynamic environments.To this end, we propose EventDC, the first event-driven depth completion framework. It consists of two key components: Event-Modulated Alignment (EMA) and Local Depth Filtering (LDF). Both modules adaptively learn the two fundamental components of convolution operations: offsets and weights conditioned on motion-sensitive event streams. In the encoder, EMA leverages events to modulate the sampling positions of RGB-D features to achieve pixel redistribution for improved alignment and fusion. In the decoder, LDF refines depth estimations around moving objects by learning motion-aware masks from events. Additionally, EventDC incorporates two loss terms to further benefit global alignment and enhance local depth recovery. Moreover, we establish the first benchmark for event-based depth completion comprising one real-world and two synthetic datasets to facilitate future research. Extensive experiments on this benchmark demonstrate the superiority of our EventDC.
DuCos: Duality Constrained Depth Super-Resolution via Foundation Model
Mar 06, 2025We introduce DuCos, a novel depth super-resolution framework grounded in Lagrangian duality theory, offering a flexible integration of multiple constraints and reconstruction objectives to enhance accuracy and robustness. Our DuCos is the first to significantly improve generalization across diverse scenarios with foundation models as prompts. The prompt design consists of two key components: Correlative Fusion (CF) and Gradient Regulation (GR). CF facilitates precise geometric alignment and effective fusion between prompt and depth features, while GR refines depth predictions by enforcing consistency with sharp-edged depth maps derived from foundation models. Crucially, these prompts are seamlessly embedded into the Lagrangian constraint term, forming a synergistic and principled framework. Extensive experiments demonstrate that DuCos outperforms existing state-of-the-art methods, achieving superior accuracy, robustness, and generalization. The source codes and pre-trained models will be publicly available.
Learning Inverse Laplacian Pyramid for Progressive Depth Completion
Feb 11, 2025Depth completion endeavors to reconstruct a dense depth map from sparse depth measurements, leveraging the information provided by a corresponding color image. Existing approaches mostly hinge on single-scale propagation strategies that iteratively ameliorate initial coarse depth estimates through pixel-level message passing. Despite their commendable outcomes, these techniques are frequently hampered by computational inefficiencies and a limited grasp of scene context. To circumvent these challenges, we introduce LP-Net, an innovative framework that implements a multi-scale, progressive prediction paradigm based on Laplacian Pyramid decomposition. Diverging from propagation-based approaches, LP-Net initiates with a rudimentary, low-resolution depth prediction to encapsulate the global scene context, subsequently refining this through successive upsampling and the reinstatement of high-frequency details at incremental scales. We have developed two novel modules to bolster this strategy: 1) the Multi-path Feature Pyramid module, which segregates feature maps into discrete pathways, employing multi-scale transformations to amalgamate comprehensive spatial information, and 2) the Selective Depth Filtering module, which dynamically learns to apply both smoothness and sharpness filters to judiciously mitigate noise while accentuating intricate details. By integrating these advancements, LP-Net not only secures state-of-the-art (SOTA) performance across both outdoor and indoor benchmarks such as KITTI, NYUv2, and TOFDC, but also demonstrates superior computational efficiency. At the time of submission, LP-Net ranks 1st among all peer-reviewed methods on the official KITTI leaderboard.
Completion as Enhancement: A Degradation-Aware Selective Image Guided Network for Depth Completion
Dec 26, 2024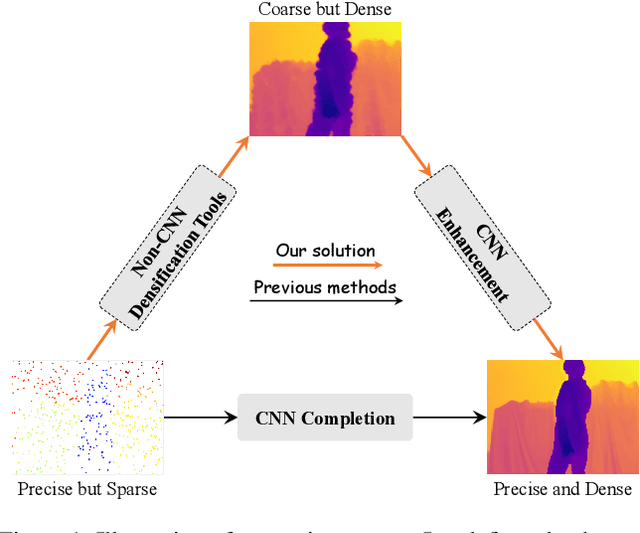
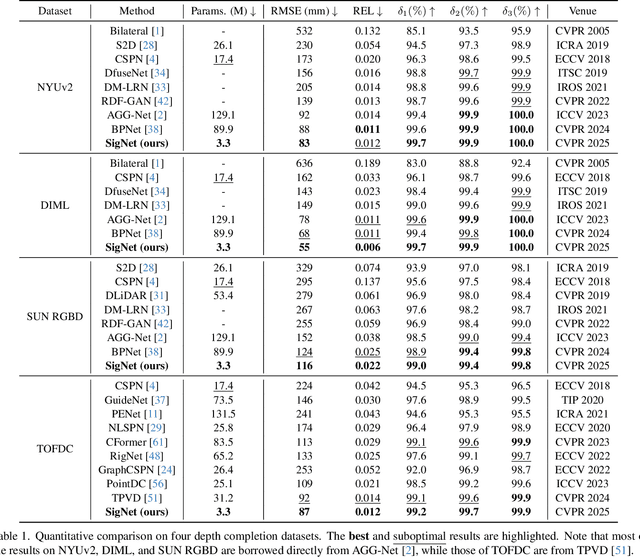
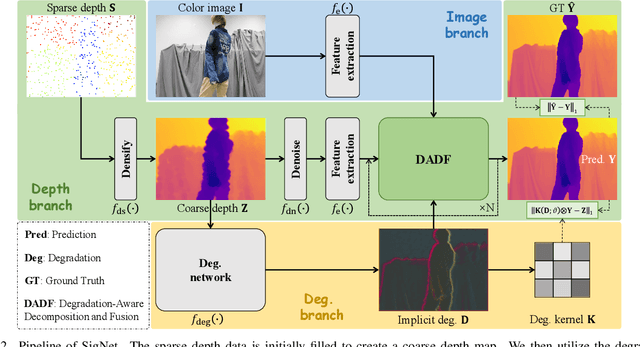

In this paper, we introduce the Selective Image Guided Network (SigNet), a novel degradation-aware framework that transforms depth completion into depth enhancement for the first time. Moving beyond direct completion using convolutional neural networks (CNNs), SigNet initially densifies sparse depth data through non-CNN densification tools to obtain coarse yet dense depth. This approach eliminates the mismatch and ambiguity caused by direct convolution over irregularly sampled sparse data. Subsequently, SigNet redefines completion as enhancement, establishing a self-supervised degradation bridge between the coarse depth and the targeted dense depth for effective RGB-D fusion. To achieve this, SigNet leverages the implicit degradation to adaptively select high-frequency components (e.g., edges) of RGB data to compensate for the coarse depth. This degradation is further integrated into a multi-modal conditional Mamba, dynamically generating the state parameters to enable efficient global high-frequency information interaction. We conduct extensive experiments on the NYUv2, DIML, SUN RGBD, and TOFDC datasets, demonstrating the state-of-the-art (SOTA) performance of SigNet.
Depth-Centric Dehazing and Depth-Estimation from Real-World Hazy Driving Video
Dec 16, 2024
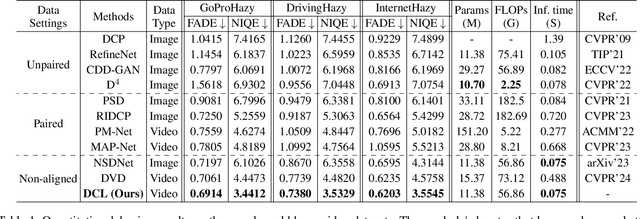
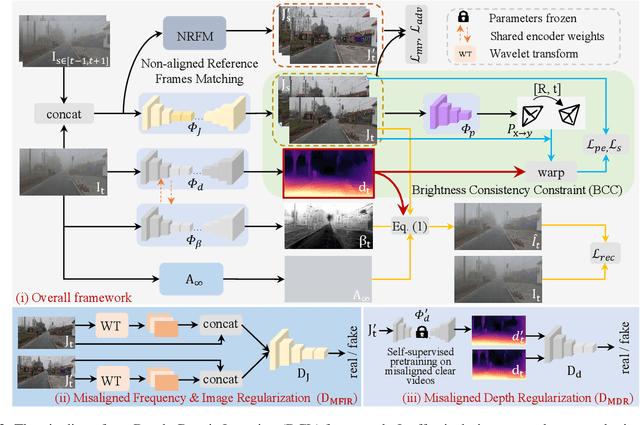
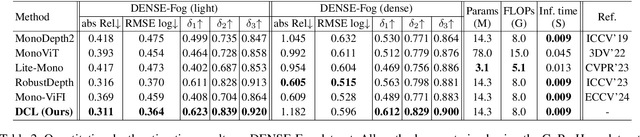
In this paper, we study the challenging problem of simultaneously removing haze and estimating depth from real monocular hazy videos. These tasks are inherently complementary: enhanced depth estimation improves dehazing via the atmospheric scattering model (ASM), while superior dehazing contributes to more accurate depth estimation through the brightness consistency constraint (BCC). To tackle these intertwined tasks, we propose a novel depth-centric learning framework that integrates the ASM model with the BCC constraint. Our key idea is that both ASM and BCC rely on a shared depth estimation network. This network simultaneously exploits adjacent dehazed frames to enhance depth estimation via BCC and uses the refined depth cues to more effectively remove haze through ASM. Additionally, we leverage a non-aligned clear video and its estimated depth to independently regularize the dehazing and depth estimation networks. This is achieved by designing two discriminator networks: $D_{MFIR}$ enhances high-frequency details in dehazed videos, and $D_{MDR}$ reduces the occurrence of black holes in low-texture regions. Extensive experiments demonstrate that the proposed method outperforms current state-of-the-art techniques in both video dehazing and depth estimation tasks, especially in real-world hazy scenes. Project page: https://fanjunkai1.github.io/projectpage/DCL/index.html.