 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASDiff: Physics-Aware Semantic Guidance for Joint Real-world Low-Light Face Enhancement and Restoration
Mar 26, 2026Face images captured in real-world low light suffer multiple degradations-low illumination, blur, noise, and low visibility, etc. Existing cascaded solutions often suffer from severe error accumulation, while generic joint models lack explicit facial priors and struggle to resolve clear face structures. In this paper, we propose PASDiff, a Physics-Aware Semantic Diffusion with a training-free manner. To achieve a plausible illumination and color distribution, we leverage inverse intensity weighting and Retinex theory to introduce photometric constraints, thereby reliably recovering visibility and natural chromaticity. To faithfully reconstruct facial details, our Style-Agnostic Structural Injection (SASI) extracts structures from an off-the-shelf facial prior while filtering out its intrinsic photometric biases, seamlessly harmonizing identity features with physical constraints. Furthermore, we construct WildDark-Face, a real-world benchmark of 700 low-light facial images with complex degradations. Extensive experiments demonstrate that PASDiff significantly outperforms existing methods, achieving a superior balance among natural illumination, color recovery, and identity consistency.
Event-Driven Dynamic Scene Depth Completion
May 19, 2025



Depth completion in dynamic scenes poses significant challenges due to rapid ego-motion and object motion, which can severely degrade the quality of input modalities such as RGB images and LiDAR measurements. Conventional RGB-D sensors often struggle to align precisely and capture reliable depth under such conditions. In contrast, event cameras with their high temporal resolution and sensitivity to motion at the pixel level provide complementary cues that are %particularly beneficial in dynamic environments.To this end, we propose EventDC, the first event-driven depth completion framework. It consists of two key components: Event-Modulated Alignment (EMA) and Local Depth Filtering (LDF). Both modules adaptively learn the two fundamental components of convolution operations: offsets and weights conditioned on motion-sensitive event streams. In the encoder, EMA leverages events to modulate the sampling positions of RGB-D features to achieve pixel redistribution for improved alignment and fusion. In the decoder, LDF refines depth estimations around moving objects by learning motion-aware masks from events. Additionally, EventDC incorporates two loss terms to further benefit global alignment and enhance local depth recovery. Moreover, we establish the first benchmark for event-based depth completion comprising one real-world and two synthetic datasets to facilitate future research. Extensive experiments on this benchmark demonstrate the superiority of our EventDC.
DuCos: Duality Constrained Depth Super-Resolution via Foundation Model
Mar 06, 2025We introduce DuCos, a novel depth super-resolution framework grounded in Lagrangian duality theory, offering a flexible integration of multiple constraints and reconstruction objectives to enhance accuracy and robustness. Our DuCos is the first to significantly improve generalization across diverse scenarios with foundation models as prompts. The prompt design consists of two key components: Correlative Fusion (CF) and Gradient Regulation (GR). CF facilitates precise geometric alignment and effective fusion between prompt and depth features, while GR refines depth predictions by enforcing consistency with sharp-edged depth maps derived from foundation models. Crucially, these prompts are seamlessly embedded into the Lagrangian constraint term, forming a synergistic and principled framework. Extensive experiments demonstrate that DuCos outperforms existing state-of-the-art methods, achieving superior accuracy, robustness, and generalization. The source codes and pre-trained models will be publicly available.
Completion as Enhancement: A Degradation-Aware Selective Image Guided Network for Depth Completion
Dec 26, 2024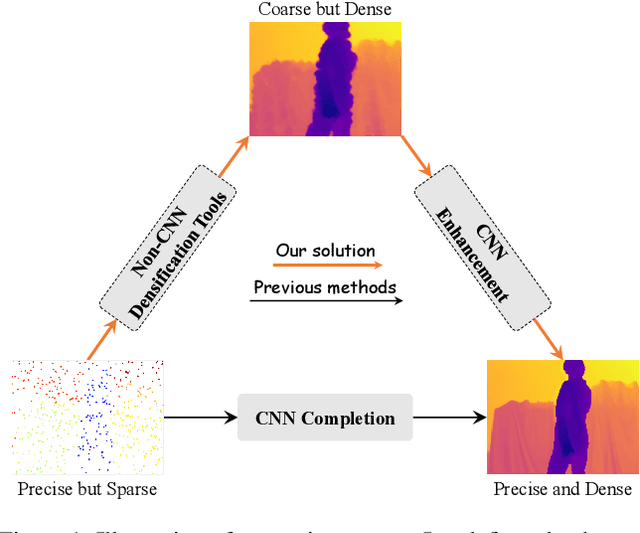
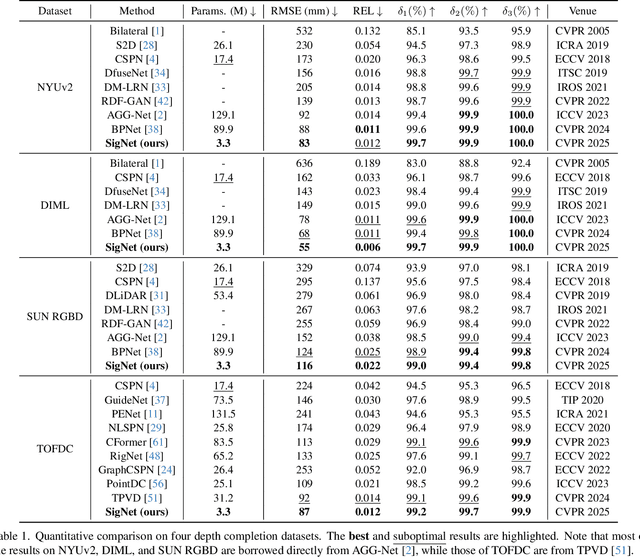
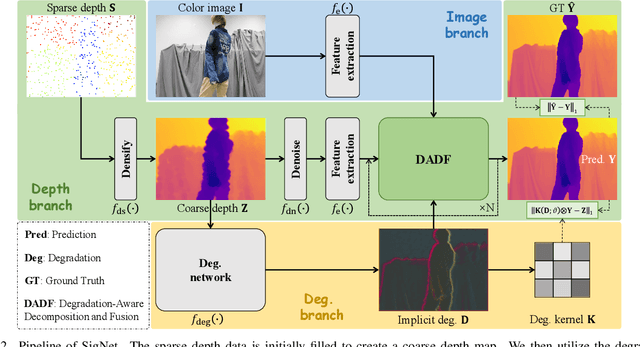

In this paper, we introduce the Selective Image Guided Network (SigNet), a novel degradation-aware framework that transforms depth completion into depth enhancement for the first time. Moving beyond direct completion using convolutional neural networks (CNNs), SigNet initially densifies sparse depth data through non-CNN densification tools to obtain coarse yet dense depth. This approach eliminates the mismatch and ambiguity caused by direct convolution over irregularly sampled sparse data. Subsequently, SigNet redefines completion as enhancement, establishing a self-supervised degradation bridge between the coarse depth and the targeted dense depth for effective RGB-D fusion. To achieve this, SigNet leverages the implicit degradation to adaptively select high-frequency components (e.g., edges) of RGB data to compensate for the coarse depth. This degradation is further integrated into a multi-modal conditional Mamba, dynamically generating the state parameters to enable efficient global high-frequency information interaction. We conduct extensive experiments on the NYUv2, DIML, SUN RGBD, and TOFDC datasets, demonstrating the state-of-the-art (SOTA) performance of SigNet.
Degradation Oriented and Regularized Network for Real-World Depth Super-Resolution
Oct 15, 2024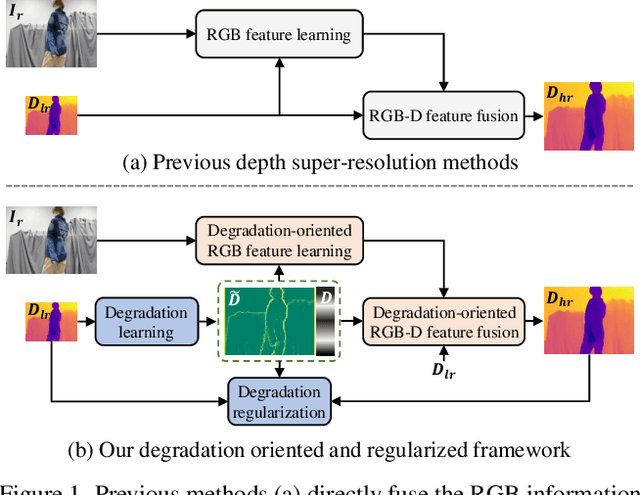
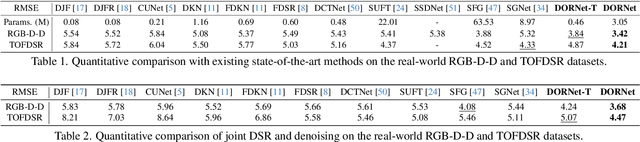

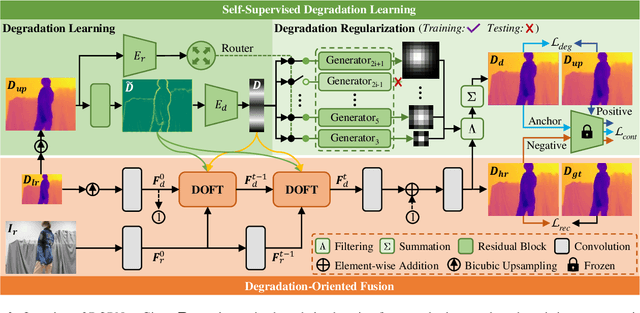
Recently, existing RGB-guided depth super-resolution methods achieve excellent performance based on the assumption of fixed and known degradation (e.g., bicubic downsampling). However, in real-world scenarios, the captured depth often suffers from unconventional and agnostic degradation due to sensor limitations and the complexity of imaging environments (e.g., low reflective surface, illumination). Their performance significantly declines when these real degradation differ from their assumptions. To address these issues, we propose a Degradation Oriented and Regularized Network, DORNet, which pays more attention on learning degradation representation of low-resolution depth that can provide targeted guidance for depth recovery. Specifically, we first design a self-supervised Degradation Learning to model the discriminative degradation representation of low-resolution depth using routing selection-based Degradation Regularization. Then, we present a Degradation Awareness that recursively conducts multiple Degradation-Oriented Feature Transformations, each of which selectively embeds RGB information into the depth based on the learned degradation representation. Extensive experimental results on both real and synthetic datasets demonstrate that our method achieves state-of-the-art performance.
Deep Height Decoupling for Precise Vision-based 3D Occupancy Prediction
Sep 12, 2024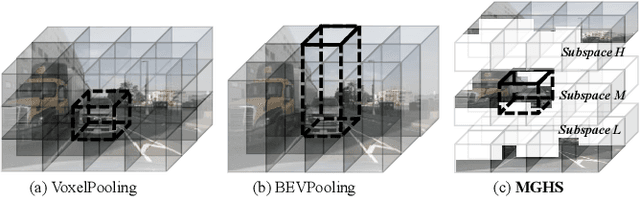
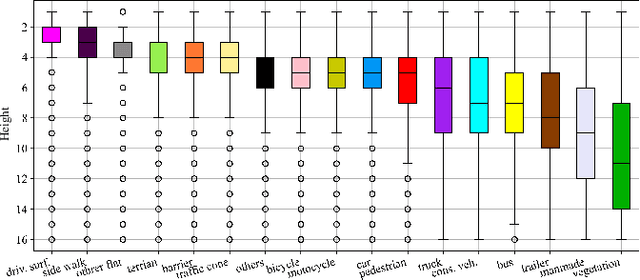
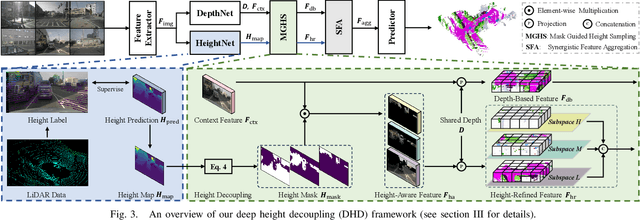

The task of vision-based 3D occupancy prediction aims to reconstruct 3D geometry and estimate its semantic classes from 2D color images, where the 2D-to-3D view transformation is an indispensable step. Most previous methods conduct forward projection, such as BEVPooling and VoxelPooling, both of which map the 2D image features into 3D grids. However, the current grid representing features within a certain height range usually introduces many confusing features that belong to other height ranges. To address this challenge, we present Deep Height Decoupling (DHD), a novel framework that incorporates explicit height prior to filter out the confusing features. Specifically, DHD first predicts height maps via explicit supervision. Based on the height distribution statistics, DHD designs Mask Guided Height Sampling (MGHS) to adaptively decoupled the height map into multiple binary masks. MGHS projects the 2D image features into multiple subspaces, where each grid contains features within reasonable height ranges. Finally, a Synergistic Feature Aggregation (SFA) module is deployed to enhance the feature representation through channel and spatial affinities, enabling further occupancy refinement. On the popular Occ3D-nuScenes benchmark, our method achieves state-of-the-art performance even with minimal input frames. Code is available at https://github.com/yanzq95/DHD.
Scene Prior Filtering for Depth Map Super-Resolution
Feb 23, 2024



Multi-modal fusion is vital to the success of super-resolution of depth maps. However, commonly used fusion strategies, such as addition and concatenation, fall short of effectively bridging the modal gap. As a result, guided image filtering methods have been introduced to mitigate this issue. Nevertheless, it is observed that their filter kernels usually encounter significant texture interference and edge inaccuracy. To tackle these two challenges, we introduce a Scene Prior Filtering network, SPFNet, which utilizes the priors surface normal and semantic map from large-scale models. Specifically, we design an All-in-one Prior Propagation that computes the similarity between multi-modal scene priors, i.e., RGB, normal, semantic, and depth, to reduce the texture interference. In addition, we present a One-to-one Prior Embedding that continuously embeds each single-modal prior into depth using Mutual Guided Filtering, further alleviating the texture interference while enhancing edges. Our SPFNet has been extensively evaluated on both real and synthetic datasets, achieving state-of-the-art performance.
SGNet: Structure Guided Network via Gradient-Frequency Awareness for Depth Map Super-Resolution
Dec 13, 2023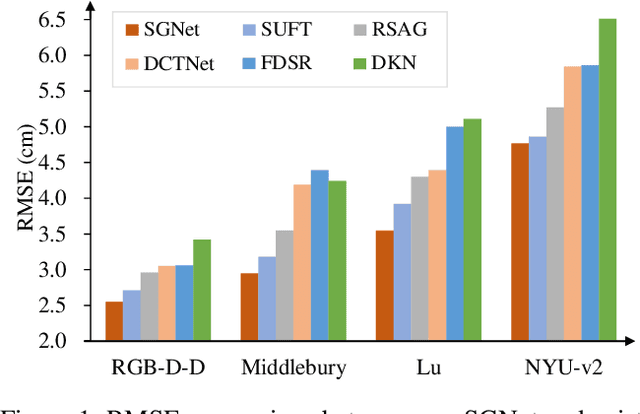

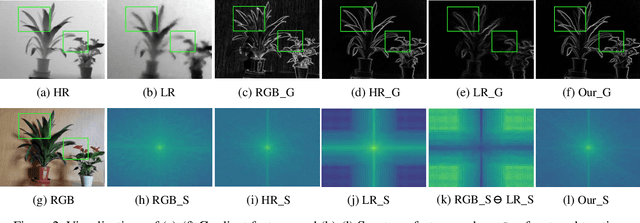
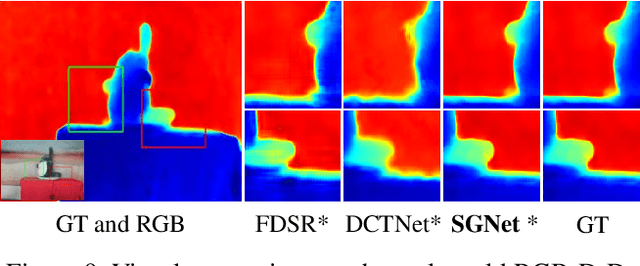
Depth super-resolution (DSR) aims to restore high-resolution (HR) depth from low-resolution (LR) one, where RGB image is often used to promote this task. Recent image guided DSR approaches mainly focus on spatial domain to rebuild depth structure. However, since the structure of LR depth is usually blurry, only considering spatial domain is not very sufficient to acquire satisfactory results. In this paper, we propose structure guided network (SGNet), a method that pays more attention to gradient and frequency domains, both of which have the inherent ability to capture high-frequency structure. Specifically, we first introduce the gradient calibration module (GCM), which employs the accurate gradient prior of RGB to sharpen the LR depth structure. Then we present the Frequency Awareness Module (FAM) that recursively conducts multiple spectrum differencing blocks (SDB), each of which propagates the precise high-frequency components of RGB into the LR depth. Extensive experimental results on both real and synthetic datasets demonstrate the superiority of our SGNet, reaching the state-of-the-art. Codes and pre-trained models are available at https://github.com/yanzq95/SGNet.
Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer
Apr 28, 2022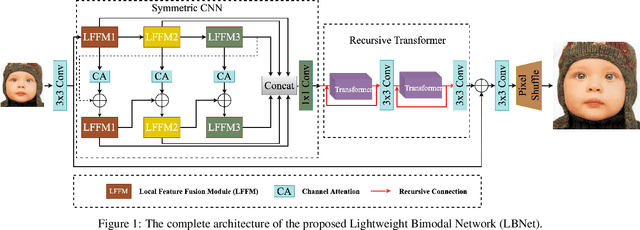
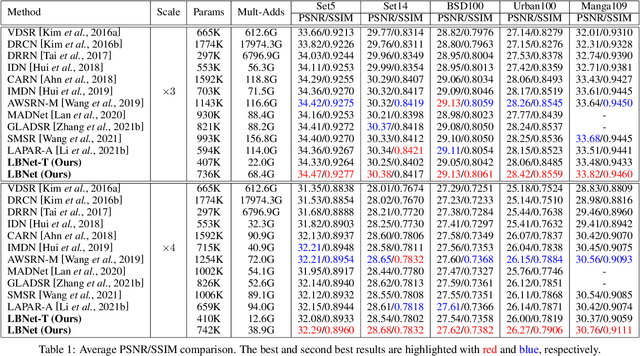
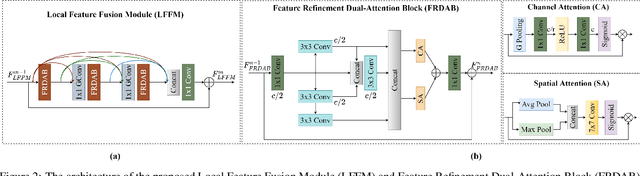
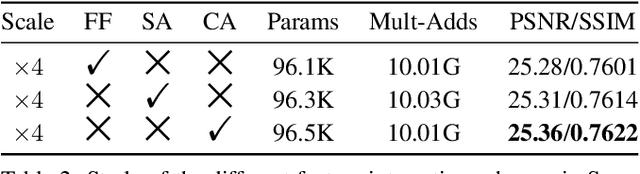
Single-image super-resolution (SISR) has achieved significant breakthroughs with the development of deep learning. However, these methods are difficult to be applied in real-world scenarios since they are inevitably accompanied by the problems of computational and memory costs caused by the complex operations. To solve this issue, we propose a Lightweight Bimodal Network (LBNet) for SISR. Specifically, an effective Symmetric CNN is designed for local feature extraction and coarse image reconstruction. Meanwhile, we propose a Recursive Transformer to fully learn the long-term dependence of images thus the global information can be fully used to further refine texture details. Studies show that the hybrid of CNN and Transformer can build a more efficient model. Extensive experiments have proved that our LBNet achieves more prominent performance than other state-of-the-art methods with a relatively low computational cost and memory consumption. The code is available at https://github.com/IVIPLab/LBNet.
Lightweight Image Super-Resolution with Multi-scale Feature Interaction Network
Mar 24, 2021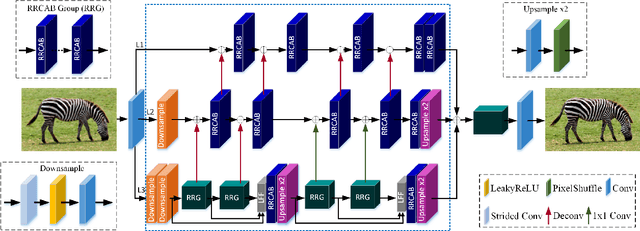

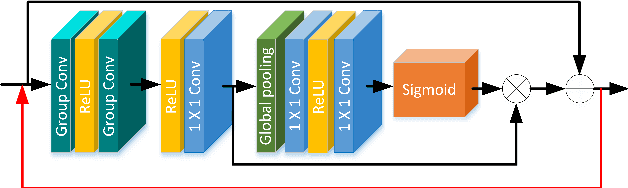
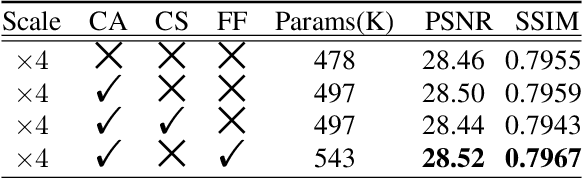
Recently, the single image super-resolution (SISR) approaches with deep and complex convolutional neural network structures have achieved promising performance. However, those methods improve the performance at the cost of higher memory consumption, which is difficult to be applied for some mobile devices with limited storage and computing resources. To solve this problem, we present a lightweight multi-scale feature interaction network (MSFIN). For lightweight SISR, MSFIN expands the receptive field and adequately exploits the informative features of the low-resolution observed images from various scales and interactive connections. In addition, we design a lightweight recurrent residual channel attention block (RRCAB) so that the network can benefit from the channel attention mechanism while being sufficiently lightweight. Extensive experiments on some benchmarks have confirmed that our proposed MSFIN can achieve comparable performance against the state-of-the-arts with a more lightweight model.