 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Unified Framework for Post-Training LLMs Without Verifiable Rewards
Jan 08, 2026Current techniques for post-training Large Language Models (LLMs) rely either on costly human supervision or on external verifiers to boost performance on tasks such as mathematical reasoning and code generation. However, as LLMs improve their problem-solving, any further improvement will potentially require high-quality solutions to difficult problems that are not available to humans. As a result, learning from unlabeled data is becoming increasingly attractive in the research community. Existing methods extract learning signal from a model's consistency, either by majority voting or by converting the model's internal confidence into reward. Although internal consistency metric such as entropy or self-certainty require no human intervention, as we show in this work, these are unreliable signals for large-scale and long-term training. To address the unreliability, we propose PRISM, a unified training framework that uses a Process Reward Model (PRM) to guide learning alongside model's internal confidence in the absence of ground-truth labels. We show that effectively combining PRM with self-certainty can lead to both stable training and better test-time performance, and also keep the model's internal confidence in check.
DEPTHOR++: Robust Depth Enhancement from a Real-World Lightweight dToF and RGB Guidance
Sep 30, 2025Depth enhancement, which converts raw dToF signals into dense depth maps using RGB guidance, is crucial for improving depth perception in high-precision tasks such as 3D reconstruction and SLAM. However, existing methods often assume ideal dToF inputs and perfect dToF-RGB alignment, overlooking calibration errors and anomalies, thus limiting real-world applicability. This work systematically analyzes the noise characteristics of real-world lightweight dToF sensors and proposes a practical and novel depth completion framework, DEPTHOR++, which enhances robustness to noisy dToF inputs from three key aspects. First, we introduce a simulation method based on synthetic datasets to generate realistic training samples for robust model training. Second, we propose a learnable-parameter-free anomaly detection mechanism to identify and remove erroneous dToF measurements, preventing misleading propagation during completion. Third, we design a depth completion network tailored to noisy dToF inputs, which integrates RGB images and pre-trained monocular depth estimation priors to improve depth recovery in challenging regions. On the ZJU-L5 dataset and real-world samples, our training strategy significantly boosts existing depth completion models, with our model achieving state-of-the-art performance, improving RMSE and Rel by 22% and 11% on average. On the Mirror3D-NYU dataset, by incorporating the anomaly detection method, our model improves upon the previous SOTA by 37% in mirror regions. On the Hammer dataset, using simulated low-cost dToF data from RealSense L515, our method surpasses the L515 measurements with an average gain of 22%, demonstrating its potential to enable low-cost sensors to outperform higher-end devices. Qualitative results across diverse real-world datasets further validate the effectiveness and generalizability of our approach.
DEPTHOR: Depth Enhancement from a Practical Light-Weight dToF Sensor and RGB Image
Apr 02, 2025Depth enhancement, which uses RGB images as guidance to convert raw signals from dToF into high-precision, dense depth maps, is a critical task in computer vision. Although existing super-resolution-based methods show promising results on public datasets, they often rely on idealized assumptions like accurate region correspondences and reliable dToF inputs, overlooking calibration errors that cause misalignment and anomaly signals inherent to dToF imaging, limiting real-world applicability. To address these challenges, we propose a novel completion-based method, named DEPTHOR, featuring advances in both the training strategy and model architecture. First, we propose a method to simulate real-world dToF data from the accurate ground truth in synthetic datasets to enable noise-robust training. Second, we design a novel network that incorporates monocular depth estimation (MDE), leveraging global depth relationships and contextual information to improve prediction in challenging regions. On the ZJU-L5 dataset, our training strategy significantly enhances depth completion models, achieving results comparable to depth super-resolution methods, while our model achieves state-of-the-art results, improving Rel and RMSE by 27% and 18%, respectively. On a more challenging set of dToF samples we collected, our method outperforms SOTA methods on preliminary stereo-based GT, improving Rel and RMSE by 23% and 22%, respectively. Our Code is available at https://github.com/ShadowBbBb/Depthor
SVDC: Consistent Direct Time-of-Flight Video Depth Completion with Frequency Selective Fusion
Mar 03, 2025Lightweight direct Time-of-Flight (dToF) sensors are ideal for 3D sensing on mobile devices. However, due to the manufacturing constraints of compact devices and the inherent physical principles of imaging, dToF depth maps are sparse and noisy. In this paper, we propose a novel video depth completion method, called SVDC, by fusing the sparse dToF data with the corresponding RGB guidance. Our method employs a multi-frame fusion scheme to mitigate the spatial ambiguity resulting from the sparse dToF imaging. Misalignment between consecutive frames during multi-frame fusion could cause blending between object edges and the background, which results in a loss of detail. To address this, we introduce an adaptive frequency selective fusion (AFSF) module, which automatically selects convolution kernel sizes to fuse multi-frame features. Our AFSF utilizes a channel-spatial enhancement attention (CSEA) module to enhance features and generates an attention map as fusion weights. The AFSF ensures edge detail recovery while suppressing high-frequency noise in smooth regions. To further enhance temporal consistency, We propose a cross-window consistency loss to ensure consistent predictions across different windows, effectively reducing flickering. Our proposed SVDC achieves optimal accuracy and consistency on the TartanAir and Dynamic Replica datasets. Code is available at https://github.com/Lan1eve/SVDC.
Preference Optimization via Contrastive Divergence: Your Reward Model is Secretly an NLL Estimator
Feb 06, 2025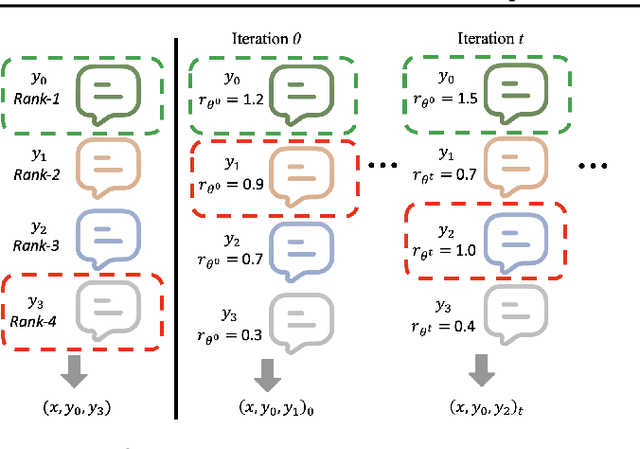
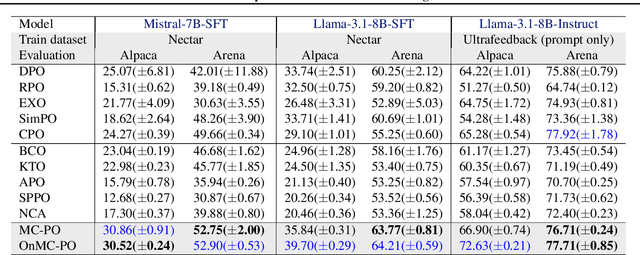
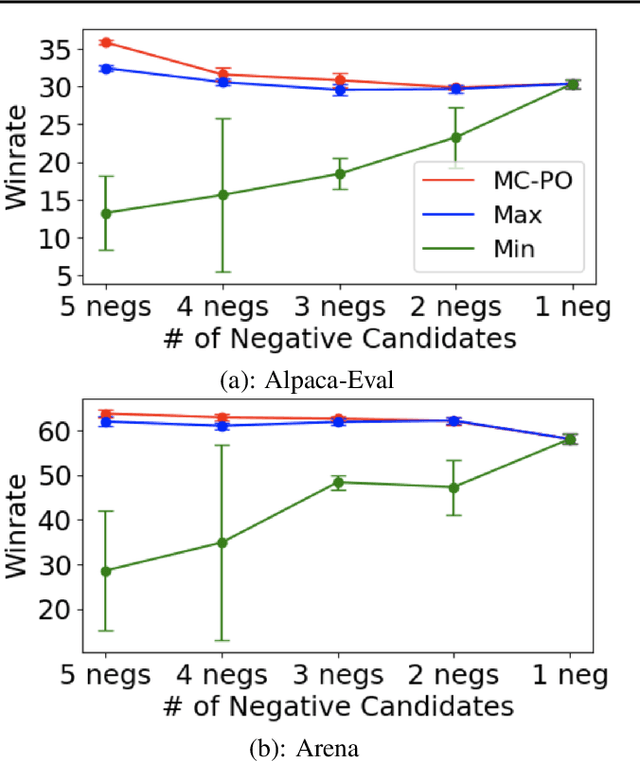
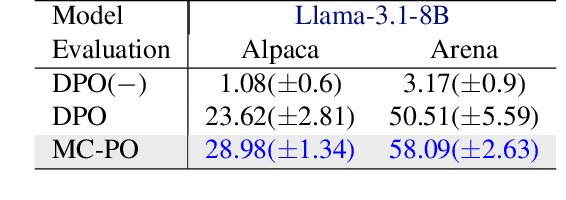
Existing studies on preference optimization (PO) have centered on constructing pairwise preference data following simple heuristics, such as maximizing the margin between preferred and dispreferred completions based on human (or AI) ranked scores. However, none of these heuristics has a full theoretical justification. In this work, we develop a novel PO framework that provides theoretical guidance to effectively sample dispreferred completions. To achieve this, we formulate PO as minimizing the negative log-likelihood (NLL) of a probability model and propose to estimate its normalization constant via a sampling strategy. As we will demonstrate, these estimative samples can act as dispreferred completions in PO. We then select contrastive divergence (CD) as the sampling strategy, and propose a novel MC-PO algorithm that applies the Monte Carlo (MC) kernel from CD to sample hard negatives w.r.t. the parameterized reward model. Finally, we propose the OnMC-PO algorithm, an extension of MC-PO to the online setting. On popular alignment benchmarks, MC-PO outperforms existing SOTA baselines, and OnMC-PO leads to further improvement.
AIDE: Task-Specific Fine Tuning with Attribute Guided Multi-Hop Data Expansion
Dec 09, 2024



Fine-tuning large language models (LLMs) for specific tasks requires high-quality, diverse training data relevant to the task. Recent research has leveraged LLMs to synthesize training data, but existing approaches either depend on large seed datasets or struggle to ensure both task relevance and data diversity in the generated outputs. To address these challenges, we propose AIDE, a novel data synthesis framework that uses a multi-hop process to expand 10 seed data points while ensuring diversity and task relevance. AIDE extracts the main topic and key knowledge attributes from the seed data to guide the synthesis process. In each subsequent hop, it extracts the topic and attributes from the newly generated data and continues guided synthesis. This process repeats for a total of K hops. To prevent irrelevant data generation as the hop depth increases, AIDE incorporates a residual connection mechanism and uses self-reflection to improve data quality. Our empirical results demonstrate that fine-tuning Mistral-7B, Llama-3.1-8B and Llama-3.2-3B with AIDE achieves more than 10% accuracy improvements over the base models across 13 tasks from 5 different benchmarks, while outperforming the models fine-tuned with state-of-the-art data synthesis methods like Evol-Instruct, DataTune and Prompt2Model.
TaeBench: Improving Quality of Toxic Adversarial Examples
Oct 08, 2024Toxicity text detectors can be vulnerable to adversarial examples - small perturbations to input text that fool the systems into wrong detection. Existing attack algorithms are time-consuming and often produce invalid or ambiguous adversarial examples, making them less useful for evaluating or improving real-world toxicity content moderators. This paper proposes an annotation pipeline for quality control of generated toxic adversarial examples (TAE). We design model-based automated annotation and human-based quality verification to assess the quality requirements of TAE. Successful TAE should fool a target toxicity model into making benign predictions, be grammatically reasonable, appear natural like human-generated text, and exhibit semantic toxicity. When applying these requirements to more than 20 state-of-the-art (SOTA) TAE attack recipes, we find many invalid samples from a total of 940k raw TAE attack generations. We then utilize the proposed pipeline to filter and curate a high-quality TAE dataset we call TaeBench (of size 264k). Empirically, we demonstrate that TaeBench can effectively transfer-attack SOTA toxicity content moderation models and services. Our experiments also show that TaeBench with adversarial training achieve significant improvements of the robustness of two toxicity detectors.
Diversity, Density, and Homogeneity: Quantitative Characteristic Metrics for Text Collections
Mar 19, 2020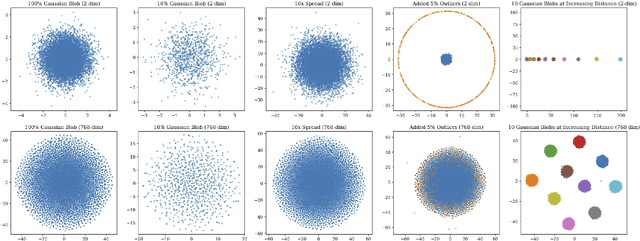
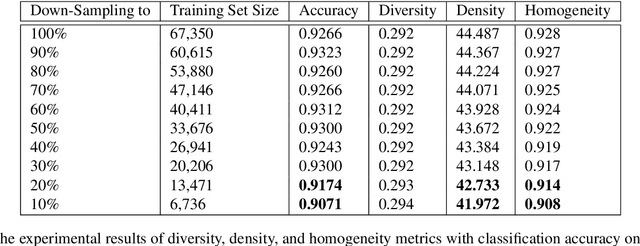
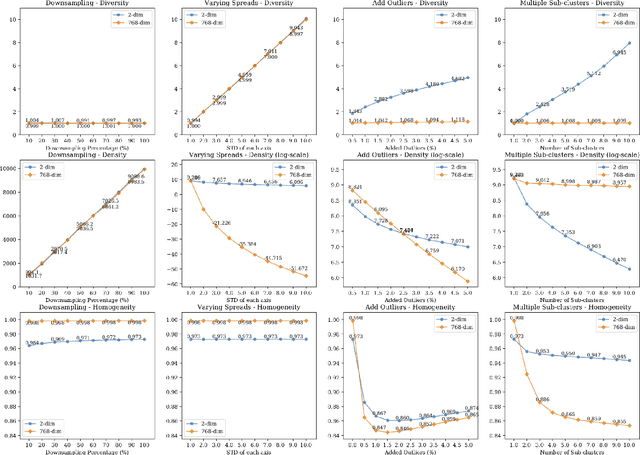
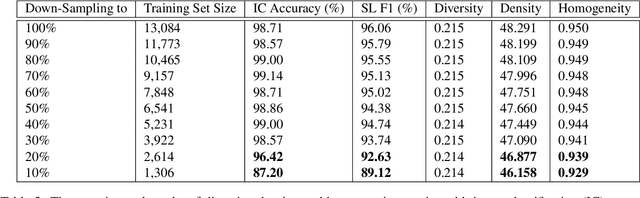
Summarizing data samples by quantitative measures has a long history, with descriptive statistics being a case in point. However, as natural language processing methods flourish, there are still insufficient characteristic metrics to describe a collection of texts in terms of the words, sentences, or paragraphs they comprise. In this work, we propose metrics of diversity, density, and homogeneity that quantitatively measure the dispersion, sparsity, and uniformity of a text collection. We conduct a series of simulations to verify that each metric holds desired properties and resonates with human intuitions. Experiments on real-world datasets demonstrate that the proposed characteristic metrics are highly correlated with text classification performance of a renowned model, BERT, which could inspire future applications.
Super-resolution based generative adversarial network using visual perceptual loss function
Apr 24, 2019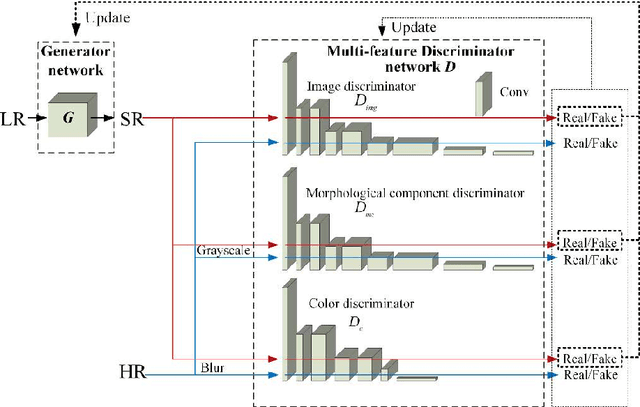

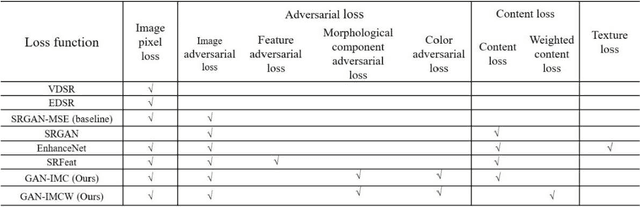
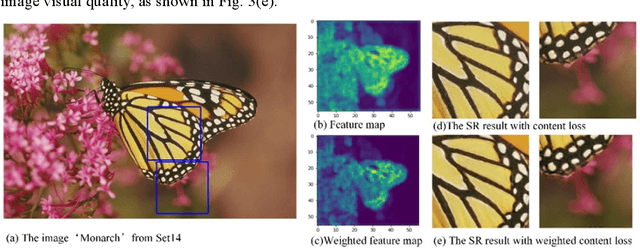
In recent years, perceptual-quality driven super-resolution methods show satisfactory results. However, super-resolved images have uncertain texture details and unpleasant artifact. We build a novel perceptual loss function composed of morphological components adversarial loss and color adversarial loss and salient content loss to ameliorate these problems. The adversarial loss is applied to constrain color and morphological components distribution of super-resolved images and the salient content loss highlights the perceptual similarity of feature-rich regions. Experiments show that proposed method achieves significant improvements in terms of perceptual index and visual quality compared with the state-of-the-art methods.
Personalized Dialogue Generation with Diversified Traits
Jan 28, 2019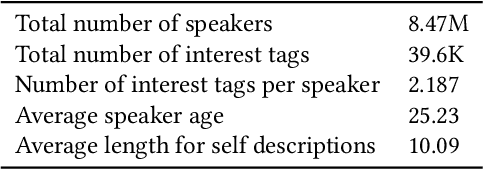
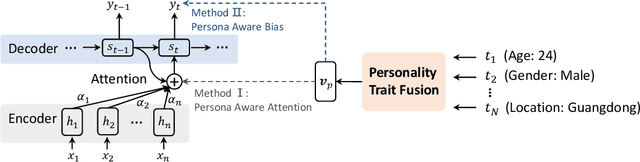

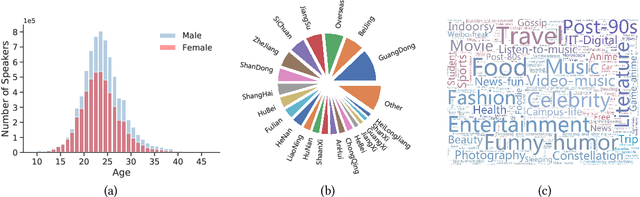
Endowing a dialogue system with particular personality traits is essential to deliver more human-like conversations. However, due to the challenge of embodying personality via language expression and the lack of large-scale persona-labeled dialogue data, this research problem is still far from well-studied. In this paper, we investigate the problem of incorporating explicit personality traits in dialogue generation to deliver personalized dialogues. To this end, firstly, we construct PersonalDialog, a large-scale multi-turn dialogue dataset containing various traits from a large number of speakers. The dataset consists of 20.83M sessions and 56.25M utterances from 8.47M speakers. Each utterance is associated with a speaker who is marked with traits like Age, Gender, Location, Interest Tags, etc. Several anonymization schemes are designed to protect the privacy of each speaker. This large-scale dataset will facilitate not only the study of personalized dialogue generation, but also other researches on sociolinguistics or social science. Secondly, to study how personality traits can be captured and addressed in dialogue generation, we propose persona-aware dialogue generation models within the sequence to sequence learning framework. Explicit personality traits (structured by key-value pairs) are embedded using a trait fusion module. During the decoding process, two techniques, namely persona-aware attention and persona-aware bias, are devised to capture and address trait-related information. Experiments demonstrate that our model is able to address proper traits in different contexts. Case studies also show interesting results for this challenging research problem.