 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity, Density, and Homogeneity: Quantitative Characteristic Metrics for Text Collections
Paper and Code
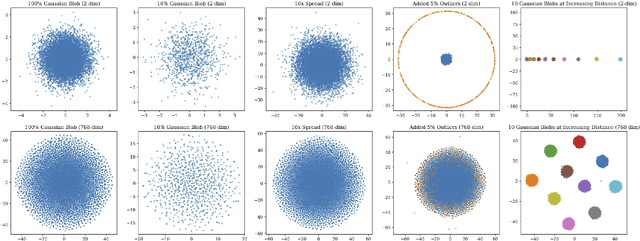
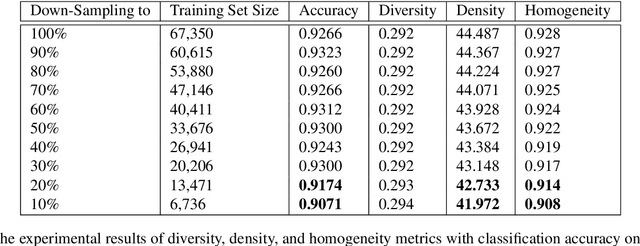
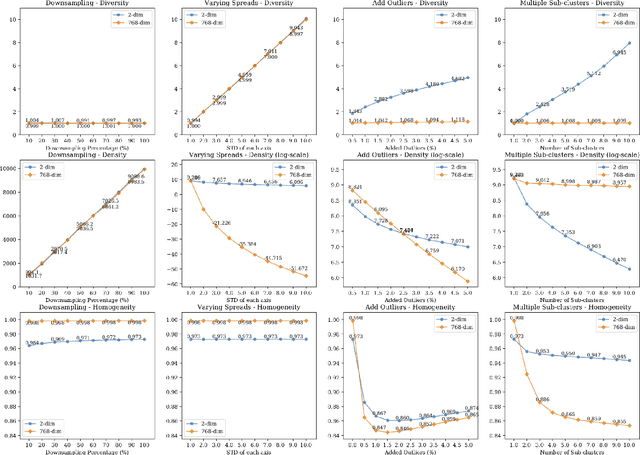
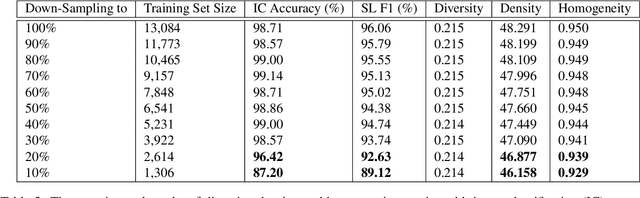
Summarizing data samples by quantitative measures has a long history, with descriptive statistics being a case in point. However, as natural language processing methods flourish, there are still insufficient characteristic metrics to describe a collection of texts in terms of the words, sentences, or paragraphs they comprise. In this work, we propose metrics of diversity, density, and homogeneity that quantitatively measure the dispersion, sparsity, and uniformity of a text collection. We conduct a series of simulations to verify that each metric holds desired properties and resonates with human intuitions. Experiments on real-world datasets demonstrate that the proposed characteristic metrics are highly correlated with text classification performance of a renowned model, BERT, which could inspire future applications.