 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline
Feb 24, 2026Song generation aims to produce full songs with vocals and accompaniment from lyrics and text descriptions, yet end-to-end models remain data- and compute-intensive and provide limited editability. We advocate a compositional alternative that decomposes the task into melody composition, singing voice synthesis, and singing accompaniment generation. Central to our approach is MIDI-informed singing accompaniment generation (MIDI-SAG), which conditions accompaniment on the symbolic vocal-melody MIDI to improve rhythmic and harmonic alignment between singing and instrumentation. Moreover, beyond conventional SAG settings that assume continuously sung vocals, compositional song generation features intermittent vocals; we address this by combining explicit rhythmic/harmonic controls with audio continuation to keep the backing track consistent across vocal and non-vocal regions. With lightweight newly trained components requiring only 2.5k hours of audio on a single RTX 3090, our pipeline approaches the perceptual quality of recent open-source end-to-end baselines in several metrics. We provide audio demos and will open-source our model at https://composerflow.github.io/web/.
RoundTable: Investigating Group Decision-Making Mechanism in Multi-Agent Collaboration
Nov 11, 2024This study investigates the efficacy of Multi-Agent Systems in eliciting cross-agent communication and enhancing collective intelligence through group decision-making in a decentralized setting. Unlike centralized mechanisms, where a fixed hierarchy governs social choice, decentralized group decision-making allows agents to engage in joint deliberation. Our research focuses on the dynamics of communication and decision-making within various social choice methods. By applying different voting rules in various environments, we find that moderate decision flexibility yields better outcomes. Additionally, exploring the linguistic features of agent-to-agent conversations reveals indicators of effective collaboration, offering insights into communication patterns that facilitate or hinder collaboration. Finally, we propose various methods for determining the optimal stopping point in multi-agent collaborations based on linguistic cues. Our findings contribute to a deeper understanding of how decentralized decision-making and group conversation shape multi-agent collaboration, with implications for the design of more effective MAS environments.
Improving Prediction Backward-Compatiblility in NLP Model Upgrade with Gated Fusion
Feb 04, 2023



When upgrading neural models to a newer version, new errors that were not encountered in the legacy version can be introduced, known as regression errors. This inconsistent behavior during model upgrade often outweighs the benefits of accuracy gain and hinders the adoption of new models. To mitigate regression errors from model upgrade, distillation and ensemble have proven to be viable solutions without significant compromise in performance. Despite the progress, these approaches attained an incremental reduction in regression which is still far from achieving backward-compatible model upgrade. In this work, we propose a novel method, Gated Fusion, that promotes backward compatibility via learning to mix predictions between old and new models. Empirical results on two distinct model upgrade scenarios show that our method reduces the number of regression errors by 62% on average, outperforming the strongest baseline by an average of 25%.
Backward Compatibility During Data Updates by Weight Interpolation
Jan 25, 2023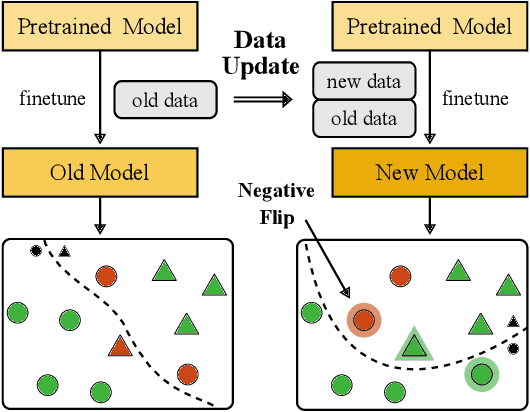



Backward compatibility of model predictions is a desired property when updating a machine learning driven application. It allows to seamlessly improve the underlying model without introducing regression bugs. In classification tasks these bugs occur in the form of negative flips. This means an instance that was correctly classified by the old model is now classified incorrectly by the updated model. This has direct negative impact on the user experience of such systems e.g. a frequently used voice assistant query is suddenly misclassified. A common reason to update the model is when new training data becomes available and needs to be incorporated. Simply retraining the model with the updated data introduces the unwanted negative flips. We study the problem of regression during data updates and propose Backward Compatible Weight Interpolation (BCWI). This method interpolates between the weights of the old and new model and we show in extensive experiments that it reduces negative flips without sacrificing the improved accuracy of the new model. BCWI is straight forward to implement and does not increase inference cost. We also explore the use of importance weighting during interpolation and averaging the weights of multiple new models in order to further reduce negative flips.
Measuring and Reducing Model Update Regression in Structured Prediction for NLP
Feb 07, 2022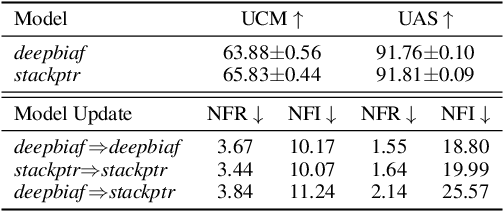

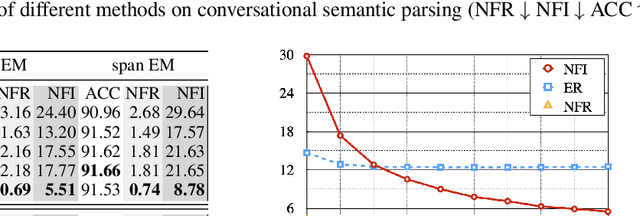
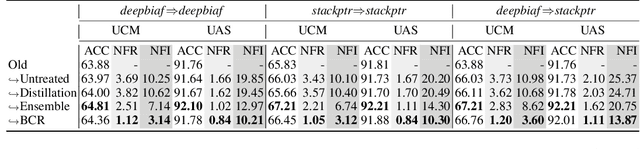
Recent advance in deep learning has led to rapid adoption of machine learning based NLP models in a wide range of applications. Despite the continuous gain in accuracy, backward compatibility is also an important aspect for industrial applications, yet it received little research attention. Backward compatibility requires that the new model does not regress on cases that were correctly handled by its predecessor. This work studies model update regression in structured prediction tasks. We choose syntactic dependency parsing and conversational semantic parsing as representative examples of structured prediction tasks in NLP. First, we measure and analyze model update regression in different model update settings. Next, we explore and benchmark existing techniques for reducing model update regression including model ensemble and knowledge distillation. We further propose a simple and effective method, Backward-Congruent Re-ranking (BCR), by taking into account the characteristics of structured output. Experiments show that BCR can better mitigate model update regression than model ensemble and knowledge distillation approaches.
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Sep 29, 2021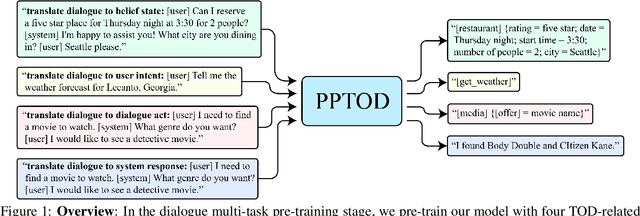
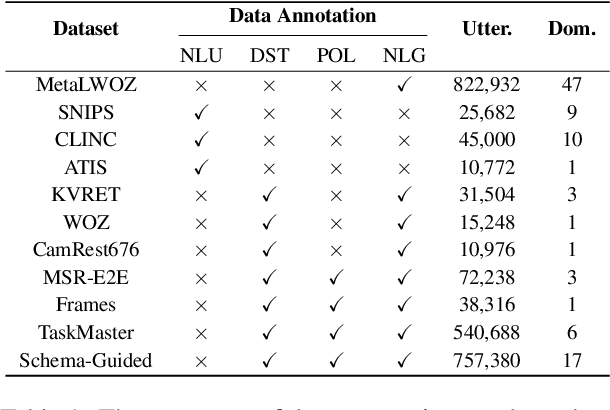
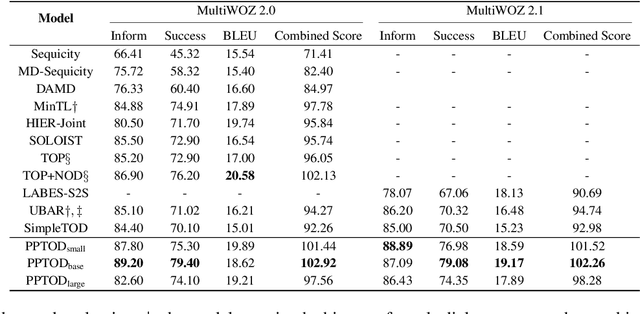
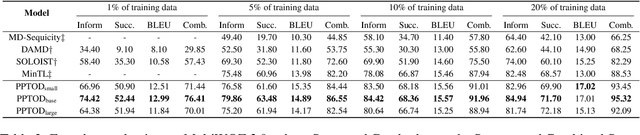
Pre-trained language models have been recently shown to benefit task-oriented dialogue (TOD) systems. Despite their success, existing methods often formulate this task as a cascaded generation problem which can lead to error accumulation across different sub-tasks and greater data annotation overhead. In this study, we present PPTOD, a unified plug-and-play model for task-oriented dialogue. In addition, we introduce a new dialogue multi-task pre-training strategy that allows the model to learn the primary TOD task completion skills from heterogeneous dialog corpora. We extensively test our model on three benchmark TOD tasks, including end-to-end dialogue modelling, dialogue state tracking, and intent classification. Experimental results show that PPTOD achieves new state of the art on all evaluated tasks in both high-resource and low-resource scenarios. Furthermore, comparisons against previous SOTA methods show that the responses generated by PPTOD are more factually correct and semantically coherent as judged by human annotators.
Diversity, Density, and Homogeneity: Quantitative Characteristic Metrics for Text Collections
Mar 19, 2020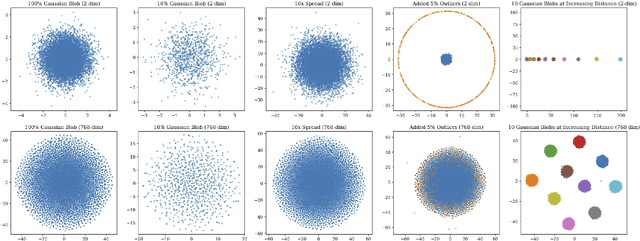
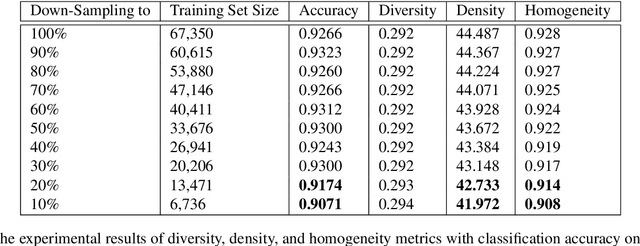
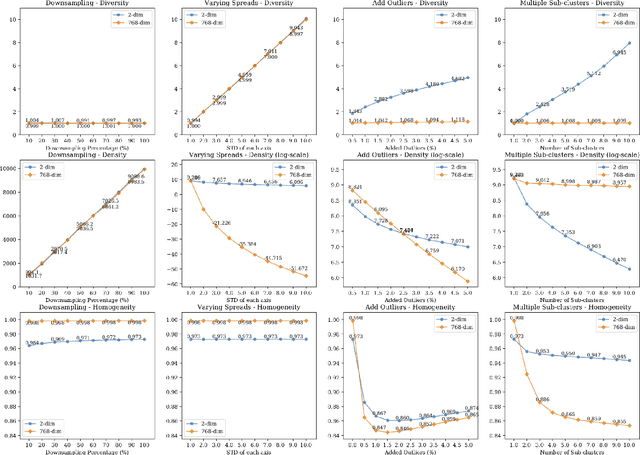
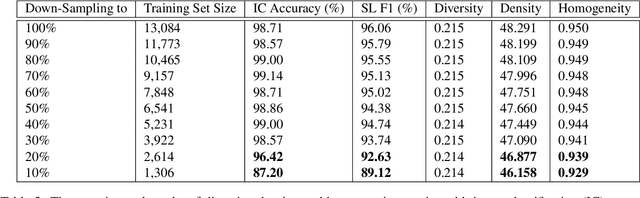
Summarizing data samples by quantitative measures has a long history, with descriptive statistics being a case in point. However, as natural language processing methods flourish, there are still insufficient characteristic metrics to describe a collection of texts in terms of the words, sentences, or paragraphs they comprise. In this work, we propose metrics of diversity, density, and homogeneity that quantitatively measure the dispersion, sparsity, and uniformity of a text collection. We conduct a series of simulations to verify that each metric holds desired properties and resonates with human intuitions. Experiments on real-world datasets demonstrate that the proposed characteristic metrics are highly correlated with text classification performance of a renowned model, BERT, which could inspire future applications.
Goal-Embedded Dual Hierarchical Model for Task-Oriented Dialogue Generation
Sep 19, 2019

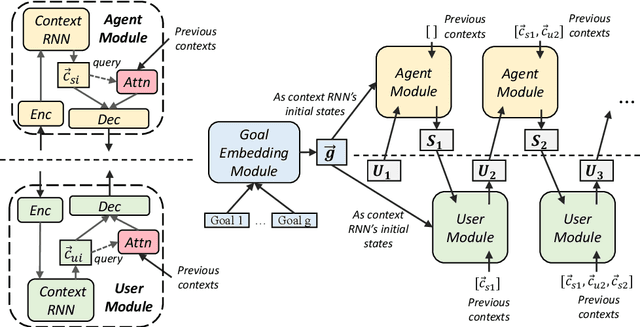
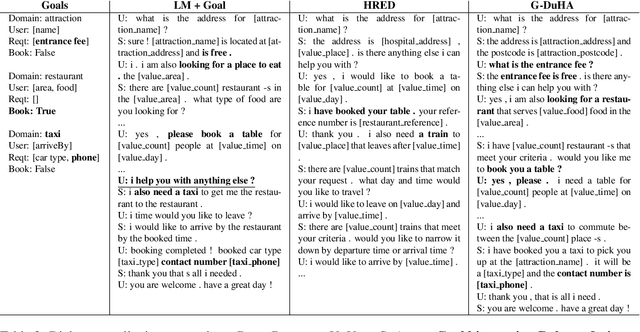
Hierarchical neural networks are often used to model inherent structures within dialogues. For goal-oriented dialogues, these models miss a mechanism adhering to the goals and neglect the distinct conversational patterns between two interlocutors. In this work, we propose Goal-Embedded Dual Hierarchical Attentional Encoder-Decoder (G-DuHA) able to center around goals and capture interlocutor-level disparity while modeling goal-oriented dialogues. Experiments on dialogue generation, response generation, and human evaluations demonstrate that the proposed model successfully generates higher-quality, more diverse and goal-centric dialogues. Moreover, we apply data augmentation via goal-oriented dialogue generation for task-oriented dialog systems with better performance achieved.
Attribute-aware Collaborative Filtering: Survey and Classification
Oct 20, 2018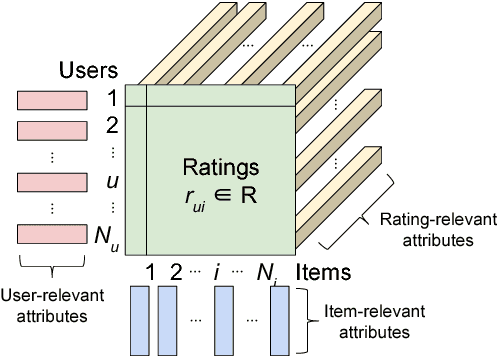

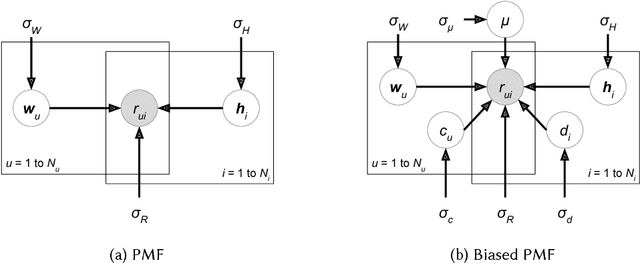
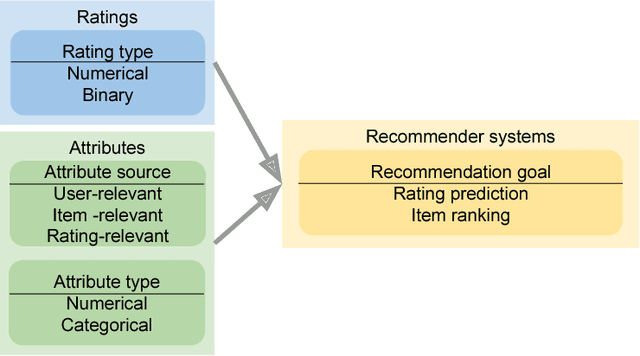
Attribute-aware CF models aims at rating prediction given not only the historical rating from users to items, but also the information associated with users (e.g. age), items (e.g. price), or even ratings (e.g. rating time). This paper surveys works in the past decade developing attribute-aware CF systems, and discovered that mathematically they can be classified into four different categories. We provide the readers not only the high level mathematical interpretation of the existing works in this area but also the mathematical insight for each category of models. Finally we provide in-depth experiment results comparing the effectiveness of the major works in each category.