 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Optimization via Contrastive Divergence: Your Reward Model is Secretly an NLL Estimator
Paper and Code
Feb 06, 2025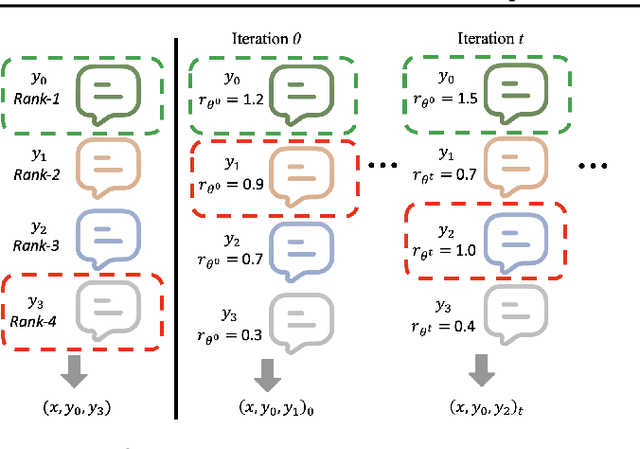
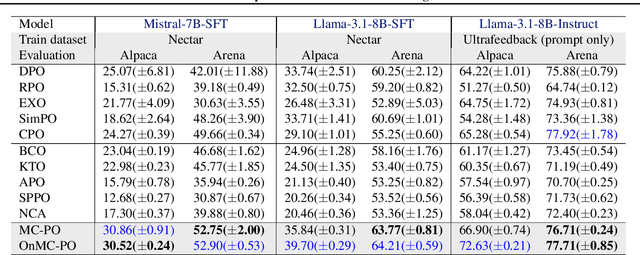
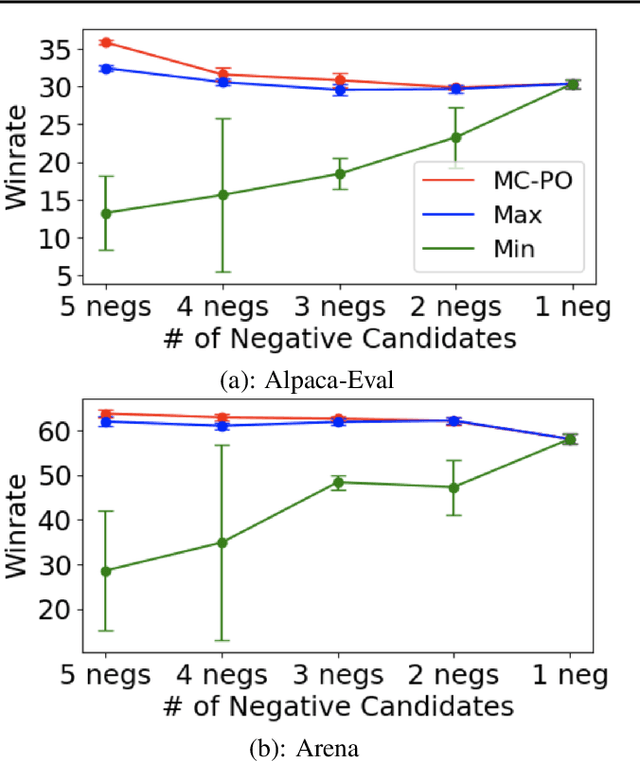
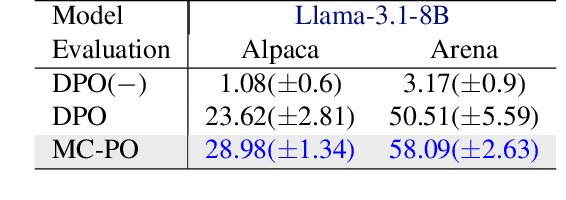
Existing studies on preference optimization (PO) have centered on constructing pairwise preference data following simple heuristics, such as maximizing the margin between preferred and dispreferred completions based on human (or AI) ranked scores. However, none of these heuristics has a full theoretical justification. In this work, we develop a novel PO framework that provides theoretical guidance to effectively sample dispreferred completions. To achieve this, we formulate PO as minimizing the negative log-likelihood (NLL) of a probability model and propose to estimate its normalization constant via a sampling strategy. As we will demonstrate, these estimative samples can act as dispreferred completions in PO. We then select contrastive divergence (CD) as the sampling strategy, and propose a novel MC-PO algorithm that applies the Monte Carlo (MC) kernel from CD to sample hard negatives w.r.t. the parameterized reward model. Finally, we propose the OnMC-PO algorithm, an extension of MC-PO to the online setting. On popular alignment benchmarks, MC-PO outperforms existing SOTA baselines, and OnMC-PO leads to further improvement.